版本 2.9.4
© 2012-2020 Pivotal Software, Inc.
本文档的副本可以供您自己使用和分发给其他人,前提是您不对此类副本收取任何费用,并且进一步前提是每份副本都包含本版权声明,无论是印刷版还是电子版。
前言
1. 关于文档
2. 寻求帮助
Spring Cloud Data Flow 遇到问题?我们愿意提供帮助!
-
问一个问题。我们监控stackoverflow.com中带有 标记的问题
spring-cloud-dataflow。 -
在github.com/spring-cloud/spring-cloud-dataflow/issues报告 Spring Cloud Data Flow 的错误。
-
在Gitter上与社区和开发人员聊天。
| 所有 Spring Cloud Data Flow 都是开源的,包括文档!如果您发现文档有问题,或者您只是想改进它们,请参与进来。 |
入门
3. 入门 - 本地
4. 入门 - Cloud Foundry
本节介绍如何开始使用 Cloud Foundry 上的 Spring Cloud Data Flow。有关在 Cloud Foundry 上安装 Spring Cloud Data Flow 的更多信息,请参阅微型站点的Cloud Foundry部分。
5. 入门 - Kubernetes
Spring Cloud Data Flow是一个用于构建数据集成和实时数据处理管道的工具包。
管道由使用 Spring Cloud Stream 或 Spring Cloud Task 微服务框架构建的 Spring Boot 应用程序组成。这使得 Spring Cloud Data Flow 适用于从导入导出到事件流和预测分析的一系列数据处理用例。
该项目支持使用带有 Kubernetes 的 Spring Cloud Data Flow 作为这些管道的运行时,并将应用程序打包为 Docker 映像。
有关在 Kubernetes 上安装 Spring Cloud Data Flow 的更多信息,请参阅微型站点的Kubernetes部分。
5.1。应用程序和服务器属性
本节介绍如何自定义应用程序的部署。您可以使用许多属性来影响已部署应用程序的设置。可以基于每个应用程序或在所有已部署应用程序的适当服务器配置中应用属性。
| 基于每个应用程序设置的属性始终优先于设置为服务器配置的属性。这种安排允许您基于每个应用程序覆盖全局服务器级属性。 |
要应用于所有已部署任务的属性在src/kubernetes/server/server-config-[binder].yaml文件中定义,对于 Streams 在src/kubernetes/skipper/skipper-config-[binder].yaml. 替换[binder]为您正在使用的消息传递中间件 - 例如,rabbit或kafka.
5.1.1。内存和 CPU 设置
应用程序使用默认内存和 CPU 设置进行部署。如果需要,您可以调整这些值。以下示例显示了如何设置Limits为1000mfor CPUand 1024Mifor memory 以及Requeststo 800mfor for CPU and 640Mifor memory:
deployer.<application>.kubernetes.limits.cpu=1000m
deployer.<application>.kubernetes.limits.memory=1024Mi
deployer.<application>.kubernetes.requests.cpu=800m
deployer.<application>.kubernetes.requests.memory=640Mi这些值会导致使用以下容器设置:
Limits:
cpu: 1
memory: 1Gi
Requests:
cpu: 800m
memory: 640Mi您还可以控制全局设置cpu和的默认值。memory
以下示例显示了如何为流设置 CPU 和内存:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
limits:
memory: 640mi
cpu: 500m以下示例显示了如何为任务设置 CPU 和内存:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
limits:
memory: 640mi
cpu: 500m到目前为止我们使用的设置只影响容器的设置。它们不会影响容器中 JVM 进程的内存设置。如果您想设置 JVM 内存设置,您可以设置一个环境变量来执行此操作。有关详细信息,请参阅下一节。
5.1.2. 环境变量
要影响给定应用程序的环境设置,您可以使用spring.cloud.deployer.kubernetes.environmentVariablesdeployer 属性。例如,生产设置中的一个常见要求是影响 JVM 内存参数。您可以使用JAVA_TOOL_OPTIONS环境变量来执行此操作,如以下示例所示:
deployer.<application>.kubernetes.environmentVariables=JAVA_TOOL_OPTIONS=-Xmx1024m
该environmentVariables属性接受逗号分隔的字符串。如果环境变量包含的值也是逗号分隔的字符串,则必须将其括在单引号中——例如,
spring.cloud.deployer.kubernetes.environmentVariables=spring.cloud.stream.kafka.binder.brokers='somehost:9092,
anotherhost:9093'
|
这会覆盖所需的 JVM 内存设置<application>(替换<application>为您的应用程序的名称)。
5.1.3. 活跃度和就绪度探测
liveness和探针分别使用称为和的readiness路径。他们分别使用 a of和 a of and 。您可以在使用部署程序属性部署流时更改这些默认值。liveness 和 readiness 探针仅适用于流。/health/infodelay10period6010
以下示例通过设置部署程序属性来更改liveness探测(替换为您的应用程序的名称):<application>
deployer.<application>.kubernetes.livenessProbePath=/health
deployer.<application>.kubernetes.livenessProbeDelay=120
deployer.<application>.kubernetes.livenessProbePeriod=20您可以将其声明为流的服务器全局配置的一部分,如以下示例所示:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
livenessProbePath: /health
livenessProbeDelay: 120
livenessProbePeriod: 20同样,您可以交换liveness以readiness覆盖默认readiness设置。
默认情况下,端口 8080 用作探测端口。liveness您可以使用部署程序属性更改这两个端口和探测端口的默认值readiness,如以下示例所示:
deployer.<application>.kubernetes.readinessProbePort=7000
deployer.<application>.kubernetes.livenessProbePort=7000您可以将其声明为流的全局配置的一部分,如以下示例所示:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
readinessProbePort: 7000
livenessProbePort: 7000|
默认情况下, 要在每个应用程序的基础上自动将两者 |
您可以使用存储在Kubernetes secret中的凭据访问安全探测端点。您可以使用现有的密钥,前提是凭据包含在密钥块的credentials密钥名称下data。您可以基于每个应用程序配置探测身份验证。启用后,它通过使用相同的凭据和身份验证类型应用于端点liveness和readiness探测端点。目前,仅Basic支持身份验证。
要创建新密钥:
-
使用用于访问安全探测端点的凭据生成 base64 字符串。
基本身份验证将用户名和密码编码为 base64 字符串,格式为
username:password.以下示例(包括输出,您应该在其中替换
user并pass使用您的值)显示了如何生成 base64 字符串:$ echo -n "user:pass" | base64 dXNlcjpwYXNz -
myprobesecret.yml使用编码的凭据,创建一个包含以下内容的文件(例如, ):apiVersion: v1 kind: Secret metadata: name: myprobesecret type: Opaque data: credentials: GENERATED_BASE64_STRING -
替换
GENERATED_BASE64_STRING为之前生成的 base64 编码值。 -
使用 创建密钥
kubectl,如以下示例所示:$ kubectl create -f ./myprobesecret.yml secret "myprobesecret" created -
设置以下部署程序属性以在访问探测端点时使用身份验证,如以下示例所示:
deployer.<application>.kubernetes.probeCredentialsSecret=myprobesecret替换
<application>为要应用身份验证的应用程序的名称。
5.1.4。使用SPRING_APPLICATION_JSON
您可以使用SPRING_APPLICATION_JSON环境变量来设置在所有数据流服务器实现中通用的数据流服务器属性(包括 Maven 存储库设置的配置)。env这些设置位于部署 YAML 的容器部分的服务器级别。以下示例显示了如何执行此操作:
env:
- name: SPRING_APPLICATION_JSON
value: "{ \"maven\": { \"local-repository\": null, \"remote-repositories\": { \"repo1\": { \"url\": \"https://repo.spring.io/libs-snapshot\"} } } }"5.1.5。私有 Docker 注册表
您可以基于每个应用程序从私有注册表中提取 Docker 映像。首先,您必须在集群中创建一个秘密。按照从私有注册表中提取图像指南创建密钥。
创建密钥后,您可以使用该imagePullSecret属性设置要使用的密钥,如以下示例所示:
deployer.<application>.kubernetes.imagePullSecret=mysecret替换<application>为您的应用程序mysecret的名称和您之前创建的密钥的名称。
您还可以在全局服务器级别配置图像拉取密钥。
以下示例显示了如何对流执行此操作:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
imagePullSecret: mysecret以下示例显示了如何对任务执行此操作:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
imagePullSecret: mysecret替换mysecret为您之前创建的密钥的名称。
5.1.6。注释
您可以基于每个应用程序向 Kubernetes 对象添加注释。支持的对象类型是 pod Deployment、Service和Job。注释以一种key:value格式定义,允许多个注释用逗号分隔。有关注释的更多信息和用例,请参阅注释。
以下示例显示了如何配置应用程序以使用注释:
deployer.<application>.kubernetes.podAnnotations=annotationName:annotationValue
deployer.<application>.kubernetes.serviceAnnotations=annotationName:annotationValue,annotationName2:annotationValue2
deployer.<application>.kubernetes.jobAnnotations=annotationName:annotationValue替换<application>为您的应用程序的名称和注释的值。
5.1.7。入口点样式
入口点样式会影响应用程序属性如何传递到要部署的容器。目前支持三种样式:
-
exec(默认):将部署请求中的所有应用程序属性和命令行参数作为容器参数传递。应用程序属性转换为--key=value. -
shell:将所有应用程序属性和命令行参数作为环境变量传递。每个应用程序或命令行参数属性都被转换为大写字符串,并且.字符被替换为_. -
boot:创建一个名为的环境变量SPRING_APPLICATION_JSON,其中包含所有应用程序属性的 JSON 表示。部署请求中的命令行参数设置为容器参数。
| 在所有情况下,在服务器级别配置和基于每个应用程序定义的环境变量都按原样发送到容器。 |
您可以按如下方式配置应用程序:
deployer.<application>.kubernetes.entryPointStyle=<Entry Point Style>替换<application>为您的应用程序的名称和<Entry Point Style>您想要的入口点样式。
您还可以在全局服务器级别配置入口点样式。
以下示例显示了如何对流执行此操作:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
entryPointStyle: entryPointStyle以下示例显示了如何对任务执行此操作:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
entryPointStyle: entryPointStyle替换entryPointStyle为所需的入口点样式。
您应该选择exec或的入口点样式shell,以对应ENTRYPOINT于容器的Dockerfile. 有关execvs的更多信息和用例shell,请参阅 Docker 文档的ENTRYPOINT部分。
使用boot入口点样式对应于使用exec样式ENTRYPOINT。来自部署请求的命令行参数被传递给容器,添加的应用程序属性被映射到SPRING_APPLICATION_JSON环境变量而不是命令行参数。
当您使用boot入口点样式时,该deployer.<application>.kubernetes.environmentVariables属性不得包含SPRING_APPLICATION_JSON.
|
5.1.8。部署服务帐户
您可以通过属性为应用程序部署配置自定义服务帐户。您可以使用现有服务帐户或创建一个新帐户。创建服务帐户的一种方法是使用kubectl,如以下示例所示:
$ kubectl create serviceaccount myserviceaccountname
serviceaccount "myserviceaccountname" created然后,您可以按如下方式配置各个应用程序:
deployer.<application>.kubernetes.deploymentServiceAccountName=myserviceaccountname替换<application>为您的应用程序名称和myserviceaccountname您的服务帐户名称。
您还可以在全局服务器级别配置服务帐户名称。
以下示例显示了如何对流执行此操作:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
deploymentServiceAccountName: myserviceaccountname以下示例显示了如何对任务执行此操作:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
deploymentServiceAccountName: myserviceaccountname替换myserviceaccountname为要应用于所有部署的服务帐户名称。
5.1.9。图像拉取策略
镜像拉取策略定义了何时应该将 Docker 镜像拉取到本地注册表。目前支持三种策略:
-
IfNotPresent(默认):如果图像已经存在,则不要拉取图像。 -
Always:无论是否已经存在,始终拉取图像。 -
Never:永远不要拉图像。仅使用已存在的图像。
以下示例显示了如何单独配置应用程序:
deployer.<application>.kubernetes.imagePullPolicy=Always替换<application>为您的应用程序的名称和Always您所需的图像拉取策略。
您可以在全局服务器级别配置图像拉取策略。
以下示例显示了如何对流执行此操作:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
imagePullPolicy: Always以下示例显示了如何对任务执行此操作:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
imagePullPolicy: Always替换Always为您想要的图像拉取策略。
5.1.10。部署标签
您可以在与Deployment相关的对象上设置自定义标签。有关标签的更多信息,请参阅标签。标签以key:value格式指定。
以下示例显示了如何单独配置应用程序:
deployer.<application>.kubernetes.deploymentLabels=myLabelName:myLabelValue替换<application>为应用程序的myLabelName名称、标签名称和标签myLabelValue的值。
此外,您可以应用多个标签,如以下示例所示:
deployer.<application>.kubernetes.deploymentLabels=myLabelName:myLabelValue,myLabelName2:myLabelValue25.1.11。容差
Tolerations 与污点一起工作,以确保 Pod 不会被调度到特定节点上。Tolerations 被设置到 pod 配置中,而 taints 被设置到节点上。有关更多信息,请参阅Kubernetes 参考的污点和容忍部分。
以下示例显示了如何单独配置应用程序:
deployer.<application>.kubernetes.tolerations=[{key: 'mykey', operator: 'Equal', value: 'myvalue', effect: 'NoSchedule'}]根据您所需的容忍配置替换<application>为您的应用程序的名称和键值对。
您也可以在全局服务器级别配置容限。
以下示例显示了如何对流执行此操作:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
tolerations:
- key: mykey
operator: Equal
value: myvalue
effect: NoSchedule以下示例显示了如何对任务执行此操作:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
tolerations:
- key: mykey
operator: Equal
value: myvalue
effect: NoSchedule根据您所需的容错配置替换tolerations键值对。
5.1.12。秘密参考
可以引用秘密,并且可以将其整个数据内容解码并作为单独的变量插入到 pod 环境中。有关更多信息,请参阅 Kubernetes 参考的将 Secret 中的所有键值对配置为容器环境变量部分。
以下示例显示了如何单独配置应用程序:
deployer.<application>.kubernetes.secretRefs=testsecret您还可以指定多个机密,如下所示:
deployer.<application>.kubernetes.secretRefs=[testsecret,anothersecret]替换<application>为您的应用程序的名称,并将secretRefs属性替换为您的应用程序环境和密码的适当值。
您也可以在全局服务器级别配置秘密引用。
以下示例显示了如何对流执行此操作:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
secretRefs:
- testsecret
- anothersecret以下示例显示了如何对任务执行此操作:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
secretRefs:
- testsecret
- anothersecretsecretRefs用一个或多个秘密名称替换 的项目。
5.1.13。密钥参考
可以引用秘密并将其解码值插入到 pod 环境中。有关更多信息,请参阅 Kubernetes 参考的使用 Secrets 作为环境变量部分。
以下示例显示了如何单独配置应用程序:
deployer.<application>.kubernetes.secretKeyRefs=[{envVarName: 'MY_SECRET', secretName: 'testsecret', dataKey: 'password'}]<application>用您的应用程序的名称和envVarName、secretName和属性替换dataKey为您的应用程序环境和密码的适当值。
您也可以在全局服务器级别配置密钥引用。
以下示例显示了如何对流执行此操作:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
secretKeyRefs:
- envVarName: MY_SECRET
secretName: testsecret
dataKey: password以下示例显示了如何对任务执行此操作:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
secretKeyRefs:
- envVarName: MY_SECRET
secretName: testsecret
dataKey: password将envVarName、secretName和dataKey属性替换为您的密钥的适当值。
5.1.14。ConfigMap 参考
一个 ConfigMap 可以被引用,它的整个数据内容可以被解码并作为单独的变量插入到 pod 环境中。有关详细信息,请参阅Kubernetes 参考的将 ConfigMap 中的所有键值对配置为容器环境变量部分。
以下示例显示了如何单独配置应用程序:
deployer.<application>.kubernetes.configMapRefs=testcm您还可以指定多个 ConfigMap 实例,如下所示:
deployer.<application>.kubernetes.configMapRefs=[testcm,anothercm]替换<application>为您的应用程序的名称,并将configMapRefs属性替换为您的应用程序环境和 ConfigMap 的适当值。
您也可以在全局服务器级别配置 ConfigMap 引用。
以下示例显示了如何对流执行此操作。编辑适当的skipper-config-(binder).yaml,替换(binder)为使用中的相应活页夹:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
configMapRefs:
- testcm
- anothercm以下示例显示如何通过编辑server-config.yaml文件对任务执行此操作:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
configMapRefs:
- testcm
- anothercmconfigMapRefs用一个或多个秘密名称替换 的项目。
5.1.15。ConfigMap 关键参考
可以引用 ConfigMap 并将其关联的键值插入到 pod 环境中。有关更多信息,请参阅 Kubernetes 参考的使用 ConfigMap 数据定义容器环境变量部分。
以下示例显示了如何单独配置应用程序:
deployer.<application>.kubernetes.configMapKeyRefs=[{envVarName: 'MY_CM', configMapName: 'testcm', dataKey: 'platform'}]<application>用您的应用程序的名称和envVarName、configMapName和属性替换dataKey为您的应用程序环境和 ConfigMap 的适当值。
您也可以在全局服务器级别配置 ConfigMap 引用。
以下示例显示了如何对流执行此操作。编辑适当的skipper-config-(binder).yaml,替换(binder)为使用中的相应活页夹:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
configMapKeyRefs:
- envVarName: MY_CM
configMapName: testcm
dataKey: platform以下示例显示如何通过编辑server-config.yaml文件对任务执行此操作:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
configMapKeyRefs:
- envVarName: MY_CM
configMapName: testcm
dataKey: platform将envVarName、configMapName和dataKey属性替换为 ConfigMap 的适当值。
5.1.16。Pod 安全上下文
您可以配置 pod 安全上下文以在指定的 UID(用户 ID)或 GID(组 ID)下运行进程。当您不想在默认rootUID 和 GID 下运行进程时,这很有用。您可以定义runAsUser(UID) 或fsGroup(GID),并且可以将它们配置为一起工作。有关更多信息,请参阅 Kubernetes 参考的安全上下文部分。
以下示例显示了如何单独配置应用程序 pod:
deployer.<application>.kubernetes.podSecurityContext={runAsUser: 65534, fsGroup: 65534}<application>用您的应用程序的名称和runAsUser和/或属性替换fsGroup为您的容器环境的适当值。
您也可以在全局服务器级别配置 pod 安全上下文。
以下示例显示了如何对流执行此操作。编辑适当的skipper-config-(binder).yaml,替换(binder)为使用中的相应活页夹:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
podSecurityContext:
runAsUser: 65534
fsGroup: 65534以下示例显示如何通过编辑server-config.yaml文件对任务执行此操作:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
podSecurityContext:
runAsUser: 65534
fsGroup: 65534将runAsUserand/orfsGroup属性替换为适合您的容器环境的值。
5.1.17。服务端口
部署应用程序时,会创建一个 Kubernetes Service 对象,其默认端口为8080. 如果server.port设置了该属性,它将覆盖默认端口值。您可以基于每个应用程序向 Service 对象添加其他端口。您可以使用逗号分隔符添加多个端口。
以下示例显示了如何在应用程序的服务对象上配置其他端口:
deployer.<application>.kubernetes.servicePorts=5000
deployer.<application>.kubernetes.servicePorts=5000,9000替换<application>为您的应用程序的名称和端口的值。
5.1.18。StatefulSet 初始化容器
使用 StatefulSet 部署应用程序时,会使用 Init Container 来设置 Pod 中的实例索引。默认情况下,使用的图像是busybox,您可以自定义。
以下示例显示了如何单独配置应用程序 pod:
deployer.<application>.kubernetes.statefulSetInitContainerImageName=myimage:mylabel替换<application>为您的应用程序的名称,并将statefulSetInitContainerImageName属性替换为适合您环境的值。
您也可以在全局服务器级别配置 StatefulSet Init Container。
以下示例显示了如何对流执行此操作。编辑适当的skipper-config-(binder).yaml,替换(binder)为使用中的相应活页夹:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
statefulSetInitContainerImageName: myimage:mylabel以下示例显示如何通过编辑server-config.yaml文件对任务执行此操作:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
statefulSetInitContainerImageName: myimage:mylabel将statefulSetInitContainerImageName属性替换为适合您环境的值。
5.1.19。初始化容器
部署应用程序时,您可以基于每个应用程序设置自定义 Init Container。有关更多信息,请参阅 Kubernetes 参考的Init Containers部分。
以下示例显示了如何为应用程序配置 Init 容器:
deployer.<application>.kubernetes.initContainer={containerName: 'test', imageName: 'busybox:latest', commands: ['sh', '-c', 'echo hello']}替换<application>为您的应用程序的名称并设置initContainer适合您的 Init 容器的属性值。
5.1.20。生命周期支持
当您部署应用程序时,您可以附加postStart生命preStop 周期处理程序来执行命令。Kubernetes API 支持除exec. 此功能可能会扩展以支持未来版本中的其他操作。要配置如上面链接页面中所示的生命周期处理程序,请使用以下属性键将每个命令指定为逗号分隔的列表:
deployer.<application>.kubernetes.lifecycle.postStart.exec.command=/bin/sh,-c,'echo Hello from the postStart handler > /usr/share/message'
deployer.<application>.kubernetes.lifecycle.preStop.exec.command=/bin/sh,-c,'nginx -s quit; while killall -0 nginx; do sleep 1; done'5.1.21。额外的容器
部署应用程序时,您可能需要与主容器一起部署一个或多个容器。这将允许您在多容器 pod 设置的情况下调整一些部署模式,例如边车、适配器。
以下示例显示了如何为应用程序配置其他容器:
deployer.<application>.kubernetes.additionalContainers=[{name: 'c1', image: 'busybox:latest', command: ['sh', '-c', 'echo hello1'], volumeMounts: [{name: 'test-volume', mountPath: '/tmp', readOnly: true}]},{name: 'c2', image: 'busybox:1.26.1', command: ['sh', '-c', 'echo hello2']}]应用
6. 可用的应用程序
| 资源 | 处理器 | 下沉 | 任务 |
|---|---|---|---|
建筑学
七、简介
Spring Cloud Data Flow 简化了专注于数据处理用例的应用程序的开发和部署。
微型网站的架构部分描述了数据流的架构。
配置
8.Maven
如果要覆盖特定的 Maven 配置属性(远程存储库、代理和其他)或在代理后运行数据流服务器,则需要在启动数据流服务器时将这些属性指定为命令行参数,如以下示例:
$ java -jar spring-cloud-dataflow-server-2.9.4.jar --spring.config.additional-location=/home/joe/maven.yml上述命令假定maven.yaml类似于以下内容:
maven:
localRepository: mylocal
remote-repositories:
repo1:
url: https://repo1
auth:
username: user1
password: pass1
snapshot-policy:
update-policy: daily
checksum-policy: warn
release-policy:
update-policy: never
checksum-policy: fail
repo2:
url: https://repo2
policy:
update-policy: always
checksum-policy: fail
proxy:
host: proxy1
port: "9010"
auth:
username: proxyuser1
password: proxypass1默认情况下,协议设置为http. 如果代理不需要用户名和密码,您可以省略 auth 属性。此外,默认情况下,mavenlocalRepository设置为${user.home}/.m2/repository/. 如前面的示例所示,您可以指定远程存储库及其身份验证(如果需要)。如果远程存储库位于代理之后,您可以指定代理属性,如前面的示例所示。
您可以为每个远程存储库配置指定存储库策略,如前面的示例所示。该密钥policy适用于存储库策略snapshot和release存储库策略。
有关受支持的存储库策略列表,请参阅存储库策略主题。
由于这些是 Spring Boot @ConfigurationProperties,您需要通过将它们添加到SPRING_APPLICATION_JSON环境变量中来指定它们。以下示例显示了 JSON 的结构:
$ SPRING_APPLICATION_JSON='
{
"maven": {
"local-repository": null,
"remote-repositories": {
"repo1": {
"url": "https://repo1",
"auth": {
"username": "repo1user",
"password": "repo1pass"
}
},
"repo2": {
"url": "https://repo2"
}
},
"proxy": {
"host": "proxyhost",
"port": 9018,
"auth": {
"username": "proxyuser",
"password": "proxypass"
}
}
}
}
'8.1。车皮
Wagon对Maven使用传输的支持有限。目前,它的存在是为了支持基于 - 的存储库的抢占式身份验证,http并且需要手动启用。
通过将属性设置为 启用基于 Wagon 的http运输。然后,您可以为每个远程存储库启用抢先式身份验证。配置大致遵循HttpClient HTTP Wagon中的类似模式
。在撰写本文时,Maven 自己站点中的文档有点误导,并且缺少大多数可能的配置选项。maven.use-wagontrue
maven.remote-repositories.<repo>.wagon.http命名空间包含所有与 Wagon
http相关的设置,并且直接在它下面的键映射到支持的方法http——即 、all和,put就像在 Maven 自己的配置中一样。在这些方法配置下,您可以设置各种选项,例如
. 将带有所有请求的 auth 标头发送到指定远程存储库的简单抢占式配置如下例所示:getheaduse-preemptive
maven:
use-wagon: true
remote-repositories:
springRepo:
url: https://repo.example.org
wagon:
http:
all:
use-preemptive: true
auth:
username: user
password: password
您可以仅调整和请求all的设置,而不是配置方法,如下所示:gethead
maven:
use-wagon: true
remote-repositories:
springRepo:
url: https://repo.example.org
wagon:
http:
get:
use-preemptive: true
head:
use-preemptive: true
use-default-headers: true
connection-timeout: 1000
read-timeout: 1000
headers:
sample1: sample2
params:
http.socket.timeout: 1000
http.connection.stalecheck: true
auth:
username: user
password: password有use-default-headers, connection-timeout,
read-timeout, requestheaders和 HttpClient的设置params。有关参数的更多信息,请参阅Wagon ConfigurationUtils。
9. 安全
默认情况下,数据流服务器是不安全的,并在未加密的 HTTP 连接上运行。您可以通过启用 HTTPS 并要求客户端使用OAuth 2.0进行身份验证来保护您的 REST 端点以及数据流仪表板。
|
附录Azure包含如何设置Azure Active Directory集成的更多信息。 |
|
默认情况下,REST 端点(管理、管理和运行状况)以及仪表板 UI 不需要经过身份验证的访问。 |
虽然理论上您可以选择任何 OAuth 提供者与 Spring Cloud Data Flow 结合使用,但我们建议使用 CloudFoundry 用户帐户和身份验证 (UAA) 服务器。
UAA OpenID 不仅经过认证并被 Cloud Foundry 使用,您还可以在本地单机部署场景中使用它。此外,UAA 不仅提供自己的用户存储,还提供全面的 LDAP 集成。
9.1。启用 HTTPS
默认情况下,仪表板、管理和运行状况端点使用 HTTP 作为传输。您可以通过在配置中添加证书来切换到 HTTPS
application.yml,如以下示例所示:
server:
port: 8443 (1)
ssl:
key-alias: yourKeyAlias (2)
key-store: path/to/keystore (3)
key-store-password: yourKeyStorePassword (4)
key-password: yourKeyPassword (5)
trust-store: path/to/trust-store (6)
trust-store-password: yourTrustStorePassword (7)| 1 | 由于默认端口是9393,您可以选择将端口更改为更常见的 HTTPs 典型端口。 |
| 2 | 密钥存储在密钥库中的别名(或名称)。 |
| 3 | 密钥库文件的路径。您还可以通过使用类路径前缀来指定类路径资源 - 例如:classpath:path/to/keystore. |
| 4 | 密钥库的密码。 |
| 5 | 密钥的密码。 |
| 6 | 信任库文件的路径。您还可以使用类路径前缀指定类路径资源 - 例如:classpath:path/to/trust-store |
| 7 | 信任库的密码。 |
| 如果启用 HTTPS,它将完全取代 HTTP 作为 REST 端点和数据流仪表板交互的协议。普通 HTTP 请求失败。因此,请确保相应地配置您的 Shell。 |
使用自签名证书
出于测试目的或在开发过程中,创建自签名证书可能会很方便。首先,执行以下命令来创建证书:
$ keytool -genkey -alias dataflow -keyalg RSA -keystore dataflow.keystore \
-validity 3650 -storetype JKS \
-dname "CN=localhost, OU=Spring, O=Pivotal, L=Kailua-Kona, ST=HI, C=US" (1)
-keypass dataflow -storepass dataflow| 1 | CN是这里的重要参数。它应该与您尝试访问的域匹配 - 例如,localhost. |
然后将以下行添加到您的application.yml文件中:
server:
port: 8443
ssl:
enabled: true
key-alias: dataflow
key-store: "/your/path/to/dataflow.keystore"
key-store-type: jks
key-store-password: dataflow
key-password: dataflow这就是您需要为数据流服务器做的所有事情。启动服务器后,您应该可以在localhost:8443/. 由于这是一个自签名证书,您应该在浏览器中点击一个警告,您需要忽略它。
| 切勿在生产中使用自签名证书。 |
自签名证书和外壳
默认情况下,自签名证书是 shell 的一个问题,需要额外的步骤才能使 shell 与自签名证书一起工作。有两种选择:
-
将自签名证书添加到 JVM 信任库。
-
跳过证书验证。
将自签名证书添加到 JVM 信任库
为了使用 JVM 信任库选项,您需要从密钥库中导出之前创建的证书,如下所示:
$ keytool -export -alias dataflow -keystore dataflow.keystore -file dataflow_cert -storepass dataflow接下来,您需要创建一个 shell 可以使用的信任库,如下所示:
$ keytool -importcert -keystore dataflow.truststore -alias dataflow -storepass dataflow -file dataflow_cert -noprompt现在您可以使用以下 JVM 参数启动 Data Flow Shell:
$ java -Djavax.net.ssl.trustStorePassword=dataflow \
-Djavax.net.ssl.trustStore=/path/to/dataflow.truststore \
-Djavax.net.ssl.trustStoreType=jks \
-jar spring-cloud-dataflow-shell-2.9.4.jar|
如果您在通过 SSL 建立连接时遇到问题,您可以通过使用 |
不要忘记使用以下命令定位数据流服务器:
dataflow:> dataflow config server https://localhost:8443/跳过证书验证
或者,您也可以通过提供可选的--dataflow.skip-ssl-validation=true命令行参数来绕过认证验证。
如果设置此命令行参数,shell 将接受任何(自签名)SSL 证书。
|
如果可能,您应该避免使用此选项。禁用信任管理器会破坏 SSL 的目的,并使您的应用程序容易受到中间人攻击。 |
9.2. 使用 OAuth 2.0 进行身份验证
为了支持身份验证和授权,Spring Cloud Data Flow 使用OAuth 2.0。它允许您将 Spring Cloud Data Flow 集成到单点登录 (SSO) 环境中。
| 从 Spring Cloud Data Flow 2.0 开始,OAuth2 是提供身份验证和授权的唯一机制。 |
使用了以下 OAuth2 授权类型:
-
授权码:用于 GUI(浏览器)集成。访问者被重定向到您的 OAuth 服务进行身份验证
-
密码:由 shell(和 REST 集成)使用,因此访问者可以使用用户名和密码登录
-
客户端凭据:直接从您的 OAuth 提供程序检索访问令牌,并使用授权 HTTP 标头将其传递给数据流服务器
| 目前,Spring Cloud Data Flow 使用不透明令牌而不是透明令牌 (JWT)。 |
您可以通过两种方式访问 REST 端点:
-
基本身份验证,它使用密码授予类型对您的 OAuth2 服务进行身份验证
-
访问令牌,它使用客户端凭据授予类型
| 当您设置身份验证时,您确实也应该启用 HTTPS,尤其是在生产环境中。 |
application.yml您可以通过添加以下内容或设置环境变量来打开 OAuth2 身份验证。以下示例显示了
CloudFoundry 用户帐户和身份验证 (UAA) 服务器所需的最小设置:
spring:
security:
oauth2: (1)
client:
registration:
uaa: (2)
client-id: myclient
client-secret: mysecret
redirect-uri: '{baseUrl}/login/oauth2/code/{registrationId}'
authorization-grant-type: authorization_code
scope:
- openid (3)
provider:
uaa:
jwk-set-uri: http://uaa.local:8080/uaa/token_keys
token-uri: http://uaa.local:8080/uaa/oauth/token
user-info-uri: http://uaa.local:8080/uaa/userinfo (4)
user-name-attribute: user_name (5)
authorization-uri: http://uaa.local:8080/uaa/oauth/authorize
resourceserver:
opaquetoken:
introspection-uri: http://uaa.local:8080/uaa/introspect (6)
client-id: dataflow
client-secret: dataflow| 1 | 提供此属性会激活 OAuth2 安全性。 |
| 2 | 提供者 ID。您可以指定多个提供者。 |
| 3 | 由于 UAA 是一个 OpenID 提供程序,因此您至少必须指定openid范围。如果您的提供者还提供了额外的范围来控制角色分配,那么您也必须在此处指定这些范围。 |
| 4 | OpenID 端点。用于检索用户信息,例如用户名。强制的。 |
| 5 | 包含用户名的响应的 JSON 属性。 |
| 6 | 用于自省和验证直接传入的令牌。强制的。 |
您可以使用 curl 验证基本身份验证是否正常工作,如下所示:
curl -u myusername:mypassword http://localhost:9393/ -H 'Accept: application/json'因此,您应该会看到可用 REST 端点的列表。
当您在 Web 浏览器和启用安全性的情况下访问根 URL 时,您将被重定向到仪表板 UI。要查看 REST 端点列表,请指定application/json Accept标头。还要确保使用Postman (Chrome) 或RESTClient (Firefox)
Accept等工具添加标头
。 |
除了基本身份验证之外,您还可以提供访问令牌来访问 REST API。为此,请从您的 OAuth2 提供程序检索 OAuth2 访问令牌,并使用Authorization HTTP 标头将该访问令牌传递给 REST Api,如下所示:
$ curl -H "Authorization: Bearer <ACCESS_TOKEN>" http://localhost:9393/ -H 'Accept: application/json'9.3. 自定义授权
前面的内容主要涉及身份验证——即如何评估用户的身份。在本节中,我们将讨论可用的 授权选项——即谁可以做什么。
授权规则在dataflow-server-defaults.yml(Spring Cloud Data Flow Core 模块的一部分)中定义。
由于安全角色的确定是特定于环境的,因此 Spring Cloud Data Flow 默认将所有角色分配给经过身份验证的 OAuth2 用户。该类DefaultDataflowAuthoritiesExtractor用于此目的。
map-oauth-scopes或者,您可以通过将您的提供者的布尔属性设置为true(默认值为false),让 Spring Cloud Data Flow 将 OAuth2 范围映射到 Data Flow 角色。例如,如果您的提供商的 ID 为uaa,则属性将为
spring.cloud.dataflow.security.authorization.provider-role-mappings.uaa.map-oauth-scopes。
有关更多详细信息,请参阅角色映射一章。
您还可以通过提供您自己的扩展 Spring Cloud Data FlowAuthorityMapper接口的 Spring bean 定义来自定义角色映射行为。在这种情况下,自定义 bean 定义优先于 Spring Cloud Data Flow 提供的默认定义。
默认方案使用七个角色来保护 Spring Cloud Data Flow 公开的REST 端点 :
-
ROLE_CREATE:用于任何涉及创建的事情,例如创建流或任务
-
ROLE_DEPLOY:用于部署流或启动任务
-
ROLE_DESTROY:用于涉及删除流、任务等的任何内容。
-
ROLE_MANAGE:用于引导管理端点
-
ROLE_MODIFY:对于任何涉及改变系统状态的事情
-
ROLE_SCHEDULE:用于调度相关的操作(比如调度一个任务)
-
ROLE_VIEW:用于与检索状态相关的任何内容
如本节前面所述,所有与授权相关的默认设置都在dataflow-server-defaults.ymlSpring Cloud Data Flow Core Module 的一部分中指定。尽管如此,如果需要,您可以覆盖这些设置 - 例如,在application.yml. 配置采用 YAML 列表的形式(因为某些规则可能优先于其他规则)。因此,您需要复制和粘贴整个列表并根据您的需要对其进行调整(因为无法合并列表)。
始终参考您的application.yml文件版本,因为以下代码段可能已过时。
|
默认规则如下:
spring:
cloud:
dataflow:
security:
authorization:
enabled: true
loginUrl: "/"
permit-all-paths: "/authenticate,/security/info,/assets/**,/dashboard/logout-success-oauth.html,/favicon.ico"
rules:
# About
- GET /about => hasRole('ROLE_VIEW')
# Audit
- GET /audit-records => hasRole('ROLE_VIEW')
- GET /audit-records/** => hasRole('ROLE_VIEW')
# Boot Endpoints
- GET /management/** => hasRole('ROLE_MANAGE')
# Apps
- GET /apps => hasRole('ROLE_VIEW')
- GET /apps/** => hasRole('ROLE_VIEW')
- DELETE /apps/** => hasRole('ROLE_DESTROY')
- POST /apps => hasRole('ROLE_CREATE')
- POST /apps/** => hasRole('ROLE_CREATE')
- PUT /apps/** => hasRole('ROLE_MODIFY')
# Completions
- GET /completions/** => hasRole('ROLE_VIEW')
# Job Executions & Batch Job Execution Steps && Job Step Execution Progress
- GET /jobs/executions => hasRole('ROLE_VIEW')
- PUT /jobs/executions/** => hasRole('ROLE_MODIFY')
- GET /jobs/executions/** => hasRole('ROLE_VIEW')
- GET /jobs/thinexecutions => hasRole('ROLE_VIEW')
# Batch Job Instances
- GET /jobs/instances => hasRole('ROLE_VIEW')
- GET /jobs/instances/* => hasRole('ROLE_VIEW')
# Running Applications
- GET /runtime/streams => hasRole('ROLE_VIEW')
- GET /runtime/streams/** => hasRole('ROLE_VIEW')
- GET /runtime/apps => hasRole('ROLE_VIEW')
- GET /runtime/apps/** => hasRole('ROLE_VIEW')
# Stream Definitions
- GET /streams/definitions => hasRole('ROLE_VIEW')
- GET /streams/definitions/* => hasRole('ROLE_VIEW')
- GET /streams/definitions/*/related => hasRole('ROLE_VIEW')
- POST /streams/definitions => hasRole('ROLE_CREATE')
- DELETE /streams/definitions/* => hasRole('ROLE_DESTROY')
- DELETE /streams/definitions => hasRole('ROLE_DESTROY')
# Stream Deployments
- DELETE /streams/deployments/* => hasRole('ROLE_DEPLOY')
- DELETE /streams/deployments => hasRole('ROLE_DEPLOY')
- POST /streams/deployments/** => hasRole('ROLE_MODIFY')
- GET /streams/deployments/** => hasRole('ROLE_VIEW')
# Stream Validations
- GET /streams/validation/ => hasRole('ROLE_VIEW')
- GET /streams/validation/* => hasRole('ROLE_VIEW')
# Stream Logs
- GET /streams/logs/* => hasRole('ROLE_VIEW')
# Task Definitions
- POST /tasks/definitions => hasRole('ROLE_CREATE')
- DELETE /tasks/definitions/* => hasRole('ROLE_DESTROY')
- GET /tasks/definitions => hasRole('ROLE_VIEW')
- GET /tasks/definitions/* => hasRole('ROLE_VIEW')
# Task Executions
- GET /tasks/executions => hasRole('ROLE_VIEW')
- GET /tasks/executions/* => hasRole('ROLE_VIEW')
- POST /tasks/executions => hasRole('ROLE_DEPLOY')
- POST /tasks/executions/* => hasRole('ROLE_DEPLOY')
- DELETE /tasks/executions/* => hasRole('ROLE_DESTROY')
# Task Schedules
- GET /tasks/schedules => hasRole('ROLE_VIEW')
- GET /tasks/schedules/* => hasRole('ROLE_VIEW')
- GET /tasks/schedules/instances => hasRole('ROLE_VIEW')
- GET /tasks/schedules/instances/* => hasRole('ROLE_VIEW')
- POST /tasks/schedules => hasRole('ROLE_SCHEDULE')
- DELETE /tasks/schedules/* => hasRole('ROLE_SCHEDULE')
# Task Platform Account List */
- GET /tasks/platforms => hasRole('ROLE_VIEW')
# Task Validations
- GET /tasks/validation/ => hasRole('ROLE_VIEW')
- GET /tasks/validation/* => hasRole('ROLE_VIEW')
# Task Logs
- GET /tasks/logs/* => hasRole('ROLE_VIEW')
# Tools
- POST /tools/** => hasRole('ROLE_VIEW')每一行的格式如下:
HTTP_METHOD URL_PATTERN '=>' SECURITY_ATTRIBUTE
在哪里:
-
HTTP_METHOD 是一种 HTTP 方法(例如 PUT 或 GET),大写。
-
URL_PATTERN 是一种 Ant 风格的 URL 模式。
-
SECURITY_ATTRIBUTE 是一个 SpEL 表达式。请参阅基于表达式的访问控制。
-
其中每一个都由一个或空白字符(空格、制表符等)分隔。
请注意,上面是一个 YAML 列表,而不是位于键下的映射(因此在每行的开头使用“-”破折号)spring.cloud.dataflow.security.authorization.rules。
授权 - 外壳和仪表板行为
启用安全性后,仪表板和外壳可以识别角色,这意味着根据分配的角色,并非所有功能都可见。
例如,用户没有必要角色的 shell 命令被标记为不可用。
|
目前,shell 的 |
相反,对于仪表板,UI 不会显示用户未授权的页面或页面元素。
保护 Spring Boot 管理端点
启用安全性后,
Spring Boot HTTP 管理端点
的安全方式与其他 REST 端点相同。管理 REST 端点在角色下可用/management并且需要MANAGEMENT角色。
中的默认配置dataflow-server-defaults.yml如下:
management:
endpoints:
web:
base-path: /management
security:
roles: MANAGE| 目前,您不应自定义默认管理路径。 |
9.4。设置 UAA 身份验证
对于本地部署场景,我们建议使用 OpenID 认证的CloudFoundry用户帐户和身份验证 (UAA) 服务器。虽然Cloud Foundry使用 UAA ,但它也是一个功能齐全的独立 OAuth2 服务器,具有企业功能,例如 LDAP 集成。
要求
您需要检查、构建和运行 UAA。为此,请确保您:
-
使用 Java 8。
-
已安装Git。
-
安装CloudFoundry UAA 命令行客户端。
-
在同一台机器上运行时,为 UAA 使用不同的主机名 - 例如,
uaa/.
如果您在安装uaac时遇到问题,您可能需要设置GEM_HOME环境变量:
export GEM_HOME="$HOME/.gem"您还应该确保~/.gem/gems/cf-uaac-4.2.0/bin已将其添加到您的路径中。
为 JWT 准备 UAA
由于 UAA 是一个 OpenID 提供者并使用 JSON Web 令牌 (JWT),因此它需要一个私钥来签署这些 JWT:
openssl genrsa -out signingkey.pem 2048
openssl rsa -in signingkey.pem -pubout -out verificationkey.pem
export JWT_TOKEN_SIGNING_KEY=$(cat signingkey.pem)
export JWT_TOKEN_VERIFICATION_KEY=$(cat verificationkey.pem)稍后,一旦启动 UAA,您可以在访问时看到密钥uaa:8080/uaa/token_keys。
这里,uaaURLuaa:8080/uaa/token_keys中的 是主机名。
|
下载并启动 UAA
要下载并安装 UAA,请运行以下命令:
git clone https://github.com/pivotal/uaa-bundled.git
cd uaa-bundled
./mvnw clean install
java -jar target/uaa-bundled-1.0.0.BUILD-SNAPSHOT.jarUAA 的配置由 YAML 文件驱动uaa.yml,或者您可以使用 UAA 命令行客户端编写配置脚本:
uaac target http://uaa:8080/uaa
uaac token client get admin -s adminsecret
uaac client add dataflow \
--name dataflow \
--secret dataflow \
--scope cloud_controller.read,cloud_controller.write,openid,password.write,scim.userids,sample.create,sample.view,dataflow.create,dataflow.deploy,dataflow.destroy,dataflow.manage,dataflow.modify,dataflow.schedule,dataflow.view \
--authorized_grant_types password,authorization_code,client_credentials,refresh_token \
--authorities uaa.resource,dataflow.create,dataflow.deploy,dataflow.destroy,dataflow.manage,dataflow.modify,dataflow.schedule,dataflow.view,sample.view,sample.create\
--redirect_uri http://localhost:9393/login \
--autoapprove openid
uaac group add "sample.view"
uaac group add "sample.create"
uaac group add "dataflow.view"
uaac group add "dataflow.create"
uaac user add springrocks -p mysecret --emails springrocks@someplace.com
uaac user add vieweronly -p mysecret --emails mrviewer@someplace.com
uaac member add "sample.view" springrocks
uaac member add "sample.create" springrocks
uaac member add "dataflow.view" springrocks
uaac member add "dataflow.create" springrocks
uaac member add "sample.view" vieweronly前面的脚本设置了数据流客户端以及两个用户:
-
用户springrocks有两个范围:
sample.view和sample.create. -
User vieweronly只有一个范围:
sample.view.
添加后,您可以快速仔细检查 UAA 是否已创建用户:
curl -v -d"username=springrocks&password=mysecret&client_id=dataflow&grant_type=password" -u "dataflow:dataflow" http://uaa:8080/uaa/oauth/token -d 'token_format=opaque'上述命令应产生类似于以下内容的输出:
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to uaa (127.0.0.1) port 8080 (#0)
* Server auth using Basic with user 'dataflow'
> POST /uaa/oauth/token HTTP/1.1
> Host: uaa:8080
> Authorization: Basic ZGF0YWZsb3c6ZGF0YWZsb3c=
> User-Agent: curl/7.54.0
> Accept: */*
> Content-Length: 97
> Content-Type: application/x-www-form-urlencoded
>
* upload completely sent off: 97 out of 97 bytes
< HTTP/1.1 200
< Cache-Control: no-store
< Pragma: no-cache
< X-XSS-Protection: 1; mode=block
< X-Frame-Options: DENY
< X-Content-Type-Options: nosniff
< Content-Type: application/json;charset=UTF-8
< Transfer-Encoding: chunked
< Date: Thu, 31 Oct 2019 21:22:59 GMT
<
* Connection #0 to host uaa left intact
{"access_token":"0329c8ecdf594ee78c271e022138be9d","token_type":"bearer","id_token":"eyJhbGciOiJSUzI1NiIsImprdSI6Imh0dHBzOi8vbG9jYWxob3N0OjgwODAvdWFhL3Rva2VuX2tleXMiLCJraWQiOiJsZWdhY3ktdG9rZW4ta2V5IiwidHlwIjoiSldUIn0.eyJzdWIiOiJlZTg4MDg4Ny00MWM2LTRkMWQtYjcyZC1hOTQ4MmFmNGViYTQiLCJhdWQiOlsiZGF0YWZsb3ciXSwiaXNzIjoiaHR0cDovL2xvY2FsaG9zdDo4MDkwL3VhYS9vYXV0aC90b2tlbiIsImV4cCI6MTU3MjYwMDE3OSwiaWF0IjoxNTcyNTU2OTc5LCJhbXIiOlsicHdkIl0sImF6cCI6ImRhdGFmbG93Iiwic2NvcGUiOlsib3BlbmlkIl0sImVtYWlsIjoic3ByaW5ncm9ja3NAc29tZXBsYWNlLmNvbSIsInppZCI6InVhYSIsIm9yaWdpbiI6InVhYSIsImp0aSI6IjAzMjljOGVjZGY1OTRlZTc4YzI3MWUwMjIxMzhiZTlkIiwiZW1haWxfdmVyaWZpZWQiOnRydWUsImNsaWVudF9pZCI6ImRhdGFmbG93IiwiY2lkIjoiZGF0YWZsb3ciLCJncmFudF90eXBlIjoicGFzc3dvcmQiLCJ1c2VyX25hbWUiOiJzcHJpbmdyb2NrcyIsInJldl9zaWciOiJlOTkyMDQxNSIsInVzZXJfaWQiOiJlZTg4MDg4Ny00MWM2LTRkMWQtYjcyZC1hOTQ4MmFmNGViYTQiLCJhdXRoX3RpbWUiOjE1NzI1NTY5Nzl9.bqYvicyCPB5cIIu_2HEe5_c7nSGXKw7B8-reTvyYjOQ2qXSMq7gzS4LCCQ-CMcb4IirlDaFlQtZJSDE-_UsM33-ThmtFdx--TujvTR1u2nzot4Pq5A_ThmhhcCB21x6-RNNAJl9X9uUcT3gKfKVs3gjE0tm2K1vZfOkiGhjseIbwht2vBx0MnHteJpVW6U0pyCWG_tpBjrNBSj9yLoQZcqrtxYrWvPHaa9ljxfvaIsOnCZBGT7I552O1VRHWMj1lwNmRNZy5koJFPF7SbhiTM8eLkZVNdR3GEiofpzLCfoQXrr52YbiqjkYT94t3wz5C6u1JtBtgc2vq60HmR45bvg","refresh_token":"6ee95d017ada408697f2d19b04f7aa6c-r","expires_in":43199,"scope":"scim.userids openid sample.create cloud_controller.read password.write cloud_controller.write sample.view","jti":"0329c8ecdf594ee78c271e022138be9d"}通过使用该token_format参数,您可以请求令牌为:
-
不透明
-
jwt
10. 配置 - 本地
10.1。功能切换
Spring Cloud Data Flow Server 提供了一组特定的功能,可以在启动时启用/禁用。这些功能包括所有生命周期操作和 REST 端点(服务器和客户端实现,包括 shell 和 UI),用于:
-
流(需要船长)
-
任务
-
任务计划程序
在启动数据流服务器时,可以通过设置以下布尔属性来启用和禁用这些功能:
-
spring.cloud.dataflow.features.streams-enabled -
spring.cloud.dataflow.features.tasks-enabled -
spring.cloud.dataflow.features.schedules-enabled
默认情况下,流(需要 Skipper)和任务是启用的,而任务计划程序默认是禁用的。
REST/about端点提供有关已启用和禁用的功能的信息。
10.2. 数据库
关系数据库用于存储流和任务定义以及已执行任务的状态。Spring Cloud Data Flow 为H2、MySQL、Oracle、PostgreSQL、Db2和SQL Server提供模式。服务器启动时会自动创建模式。
默认情况下,Spring Cloud Data Flow 提供了H2数据库的嵌入式实例。H2数据库适用于开发目的,但不建议用于生产用途。
| 不支持H2数据库作为外部模式。 |
MySQL(通过 MariaDB 驱动程序)、PostgreSQL、SQL Server和嵌入式H2的 JDBC 驱动程序无需额外配置即可使用。如果您使用任何其他数据库,则需要将相应的 JDBC 驱动程序 jar 放在服务器的类路径中。
数据库属性可以作为环境变量或命令行参数传递给数据流服务器。
10.2.1. MySQL
以下示例显示如何使用 MariaDB 驱动程序定义 MySQL 数据库连接。
java -jar spring-cloud-dataflow-server/target/spring-cloud-dataflow-server-2.9.4.jar \
--spring.datasource.url=jdbc:mysql://localhost:3306/mydb \
--spring.datasource.username= \
--spring.datasource.password= \
--spring.datasource.driver-class-name=org.mariadb.jdbc.Driver 最高5.7的MySQL 版本可以与 MariaDB 驱动程序一起使用。从版本8.0开始,必须使用 MySQL 自己的驱动程序。
java -jar spring-cloud-dataflow-server/target/spring-cloud-dataflow-server-2.9.4.jar \
--spring.datasource.url=jdbc:mysql://localhost:3306/mydb \
--spring.datasource.username= \
--spring.datasource.password= \
--spring.datasource.driver-class-name=com.mysql.jdbc.Driver | 由于许可限制,我们无法捆绑 MySQL 驱动程序。您需要自己将其添加到服务器的类路径中。 |
10.2.2. 玛丽亚数据库
以下示例显示如何使用命令行参数定义 MariaDB 数据库连接
java -jar spring-cloud-dataflow-server/target/spring-cloud-dataflow-server-2.9.4.jar \
--spring.datasource.url=jdbc:mariadb://localhost:3306/mydb?useMysqlMetadata=true \
--spring.datasource.username= \
--spring.datasource.password= \
--spring.datasource.driver-class-name=org.mariadb.jdbc.Driver 从 MariaDB v2.4.1 连接器版本开始,还需要添加useMysqlMetadata=true
到 JDBC URL。在 MySQL 和 MariaDB 完全切换为两个不同的数据库之前,这是一个必需的解决方法。
MariaDB 10.3版引入了对真实数据库序列的支持,这是另一个重大变化,而围绕这些数据库的工具完全支持 MySQL 和 MariaDB 作为单独的数据库类型。解决方法是使用不尝试使用序列的较旧的休眠方言。
java -jar spring-cloud-dataflow-server/target/spring-cloud-dataflow-server-2.9.4.jar \
--spring.datasource.url=jdbc:mariadb://localhost:3306/mydb?useMysqlMetadata=true \
--spring.datasource.username= \
--spring.datasource.password= \
--spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MariaDB102Dialect \
--spring.datasource.driver-class-name=org.mariadb.jdbc.Driver 10.2.3. PostgreSQL
以下示例显示如何使用命令行参数定义 PostgreSQL 数据库连接:
java -jar spring-cloud-dataflow-server/target/spring-cloud-dataflow-server-2.9.4.jar \
--spring.datasource.url=jdbc:postgresql://localhost:5432/mydb \
--spring.datasource.username= \
--spring.datasource.password= \
--spring.datasource.driver-class-name=org.postgresql.Driver 10.2.4. SQL 服务器
以下示例显示如何使用命令行参数定义 SQL Server 数据库连接:
java -jar spring-cloud-dataflow-server/target/spring-cloud-dataflow-server-2.9.4.jar \
--spring.datasource.url='jdbc:sqlserver://localhost:1433;databaseName=mydb' \
--spring.datasource.username= \
--spring.datasource.password= \
--spring.datasource.driver-class-name=com.microsoft.sqlserver.jdbc.SQLServerDriver 10.2.5。数据库2
以下示例显示如何使用命令行参数定义 Db2 数据库连接:
java -jar spring-cloud-dataflow-server/target/spring-cloud-dataflow-server-2.9.4.jar \
--spring.datasource.url=jdbc:db2://localhost:50000/mydb \
--spring.datasource.username= \
--spring.datasource.password= \
--spring.datasource.driver-class-name=com.ibm.db2.jcc.DB2Driver | 由于许可限制,我们无法捆绑 Db2 驱动程序。您需要自己将其添加到服务器的类路径中。 |
10.2.6。甲骨文
以下示例显示如何使用命令行参数定义 Oracle 数据库连接:
java -jar spring-cloud-dataflow-server/target/spring-cloud-dataflow-server-2.9.4.jar \
--spring.datasource.url=jdbc:oracle:thin:@localhost:1521/MYDB \
--spring.datasource.username= \
--spring.datasource.password= \
--spring.datasource.driver-class-name=oracle.jdbc.OracleDriver | 由于许可限制,我们无法捆绑 Oracle 驱动程序。您需要自己将其添加到服务器的类路径中。 |
10.2.7. 添加自定义 JDBC 驱动程序
要为数据库(例如 Oracle)添加自定义驱动程序,您应该重建数据流服务器并将依赖项添加到 Mavenpom.xml文件。您需要修改模块的maven pom.xml。spring-cloud-dataflow-serverGitHub 存储库中有 GA 发布标签,因此您可以切换到所需的 GA 标签以在生产就绪代码库中添加驱动程序。
为 Spring Cloud Data Flow 服务器添加自定义 JDBC 驱动程序依赖项:
-
选择与您要重建的服务器版本相对应的标签并克隆 github 存储库。
-
编辑 spring-cloud-dataflow-server/pom.xml 并在该
dependencies部分中添加所需数据库驱动程序的依赖项。在以下示例中,选择了 Oracle 驱动程序:
<dependencies>
...
<dependency>
<groupId>com.oracle.jdbc</groupId>
<artifactId>ojdbc8</artifactId>
<version>12.2.0.1</version>
</dependency>
...
</dependencies>-
按照构建 Spring Cloud 数据流中的描述构建应用程序
您还可以通过将必要的属性添加到 dataflow-server.yml 文件来在重建服务器时提供默认值,如以下 PostgreSQL 示例所示:
spring:
datasource:
url: jdbc:postgresql://localhost:5432/mydb
username: myuser
password: mypass
driver-class-name:org.postgresql.Driver-
或者,您可以使用构建文件构建自定义 Spring Cloud Data Flow 服务器。如果需要添加驱动程序 jar ,我们的示例存储库中有自定义服务器构建的示例。
10.2.8. 模式处理
默认数据库模式由Flyway管理,如果可以为数据库用户提供足够的权限,这很方便。
以下是Skipper服务器启动时发生的情况的描述:
-
Flyway 检查
flyway_schema_history表是否存在。 -
如果架构不为空,是否有基线(到版本 1),因为如果使用共享数据库,数据流表可能就位。
-
如果 schema 为空,则 flyway 假定从头开始。
-
完成所有需要的模式迁移。
以下是启动Dataflow服务器时发生的情况的描述:
-
Flyway 检查
flyway_schema_history_dataflow表是否存在。 -
如果架构不为空,是否有基线(到版本 1),因为如果使用共享数据库,可能存在船长表。
-
如果 schema 为空,则 flyway 假定从头开始。
-
完成所有需要的模式迁移。
-
由于历史原因,如果我们检测到架构来自1.7.x行,我们会将它们转换为从2.0.x开始所需的结构,并完全继续使用 flyway。
|
我们的源代码
模式中有模式 ddl,如果使用配置禁用
Flyway
,则可以手动使用 |
10.3. 部署者属性
您可以使用Local deployer的以下配置属性来自定义 Streams 和 Tasks 的部署方式。使用 Data Flow shell 进行部署时,您可以使用语法deployer.<appName>.local.<deployerPropertyName>. 有关 shell 用法的示例,请参见下文。当在数据流服务器中配置本地任务平台和在 Skipper 中配置本地平台以部署流时,也会使用这些属性。
| 部署者属性名称 | 描述 | 默认值 |
|---|---|---|
工作目录根 |
所有创建的进程将在其中运行并创建日志文件的目录。 |
java.io.tmpdir |
envVarsToInherit |
传递给已启动应用程序的环境变量的正则表达式模式数组。 |
<"TMP", "LANG", "LANGUAGE", "LC_.*", "PATH", "SPRING_APPLICATION_JSON"> 和 <"TMP", "LANG", "LANGUAGE", "LC_.*", " Unix 上的 PATH"> |
deleteFilesOnExit |
是否在 JVM 退出时删除创建的文件和目录。 |
真的 |
javaCmd |
运行java的命令 |
java |
关机超时 |
等待应用关闭的最大秒数。 |
30 |
javaOpts |
传递给 JVM 的 Java 选项,例如 -Dtest=foo |
<无> |
继承记录 |
允许将日志记录重定向到触发子进程的进程的输出流。 |
错误的 |
调试端口 |
远程调试端口 |
<无> |
例如,要为ticktock流中的时间应用程序设置 Java 选项,请使用以下流部署属性。
dataflow:> stream create --name ticktock --definition "time --server.port=9000 | log"
dataflow:> stream deploy --name ticktock --properties "deployer.time.local.javaOpts=-Xmx2048m -Dtest=foo"为方便起见,您可以设置deployer.memory属性来设置 Java 选项-Xmx,如下例所示:
dataflow:> stream deploy --name ticktock --properties "deployer.time.memory=2048m"在部署时,如果您-Xmx在deployer.<app>.local.javaOpts属性中指定除了选项值之外的deployer.<app>.local.memory选项,则属性中的值javaOpts具有优先权。此外,javaOpts部署应用程序时设置的属性优先于数据流服务器的spring.cloud.deployer.local.javaOpts属性。
10.4. 日志记录
Spring Cloud Data Flowlocal服务器自动配置为RollingFileAppender用于日志记录。日志记录配置位于名为logback-spring.xml.
默认情况下,日志文件配置为使用:
<property name="LOG_FILE" value="${LOG_FILE:-${LOG_PATH:-${LOG_TEMP:-${java.io.tmpdir:-/tmp}}}/spring-cloud-dataflow-server}"/>使用 logback 配置RollingPolicy:
<附加程序名称="文件"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}.log</file>
<滚动策略
class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- 每日滚动 -->
<fileNamePattern>${LOG_FILE}.${LOG_FILE_ROLLING_FILE_NAME_PATTERN:-%d{yyyy-MM-dd}}.%i.gz</fileNamePattern>
<maxFileSize>${LOG_FILE_MAX_SIZE:-100MB}</maxFileSize>
<maxHistory>${LOG_FILE_MAX_HISTORY:-30}</maxHistory>
<totalSizeCap>${LOG_FILE_TOTAL_SIZE_CAP:-500MB}</totalSizeCap>
</rollingPolicy>
<编码器>
<pattern>${FILE_LOG_PATTERN}</pattern>
</编码器>
</appender>
要检查java.io.tmpdir当前的 Spring Cloud Data Flow Serverlocal服务器,
jinfo <pid> | grep "java.io.tmpdir"如果您想更改或覆盖任何属性LOG_FILE、LOG_PATH、LOG_TEMP、和LOG_FILE_MAX_SIZE,请将它们设置为系统属性。LOG_FILE_MAX_HISTORYLOG_FILE_TOTAL_SIZE_CAP
10.5。流
Data Flow Server 将 Stream 生命周期的管理委托给 Skipper 服务器。将配置属性设置spring.cloud.skipper.client.serverUri为 Skipper 的位置,例如
$ java -jar spring-cloud-dataflow-server-2.9.4.jar --spring.cloud.skipper.client.serverUri=https://192.51.100.1:7577/api节目流的配置和部署到哪些平台,是通过platform accounts在 Skipper 服务器上的配置来完成的。有关更多信息,请参阅平台上的文档。
10.6。任务
数据流服务器负责部署任务。数据流启动的任务将其状态写入数据流服务器使用的同一数据库。对于作为 Spring Batch 作业的任务,作业和步骤执行数据也存储在此数据库中。与 Skipper 启动的流一样,任务可以启动到多个平台。如果未定义平台,则使用类LocalDeployerPropertiesdefault的默认值创建一个名为的平台,该类在Local Deployer Properties表中进行了汇总
要为本地平台配置新平台帐户,spring.cloud.dataflow.task.platform.local请在文件中的部分下提供一个条目,application.yaml以通过另一个 Spring Boot 支持的机制。在以下示例中,创建了两个名为localDev和localDevDebug的本地平台帐户。shutdownTimeout和等键javaOpts是本地部署程序属性。
spring:
cloud:
dataflow:
task:
platform:
local:
accounts:
localDev:
shutdownTimeout: 60
javaOpts: "-Dtest=foo -Xmx1024m"
localDevDebug:
javaOpts: "-Xdebug -Xmx2048m"
通过将一个平台定义为default允许您跳过platformName在其他情况下需要使用它的地方。
|
启动任务时,使用任务启动选项传递平台帐户名称的值--platformName如果不传递 的值,将使用platformName该值。default
| 将一个任务部署到多个平台时,该任务的配置需要和Data Flow Server连接同一个数据库。 |
您可以配置在本地运行的数据流服务器以将任务部署到 Cloud Foundry 或 Kubernetes。有关更多信息,请参阅Cloud Foundry 任务平台配置和Kubernetes 任务平台配置部分。
跨多个平台启动和调度任务的详细示例,请参阅 dataflow.spring.io上的多平台支持任务部分。
开始船长
git clone https://github.com/spring-cloud/spring-cloud-skipper.git
cd spring-cloud/spring-cloud-skipper
./mvnw clean package -DskipTests=true
java -jar spring-cloud-skipper-server/target/spring-cloud-skipper-server-2.2.0.BUILD-SNAPSHOT.jar启动 Spring Cloud 数据流
git clone https://github.com/spring-cloud/spring-cloud-dataflow.git
cd spring-cloud-dataflow
./mvnw clean package -DskipTests=true
cd ..创建一个包含以下内容的 yaml 文件 scdf.yml:
spring:
cloud:
dataflow:
security:
authorization:
provider-role-mappings:
uaa:
map-oauth-scopes: true
role-mappings:
ROLE_CREATE: foo.create
ROLE_DEPLOY: foo.create
ROLE_DESTROY: foo.create
ROLE_MANAGE: foo.create
ROLE_MODIFY: foo.create
ROLE_SCHEDULE: foo.create
ROLE_VIEW: foo.view
security:
oauth2:
client:
registration:
uaa:
redirect-uri: '{baseUrl}/login/oauth2/code/{registrationId}'
authorization-grant-type: authorization_code
client-id: dataflow
client-secret: dataflow
scope: (1)
- openid
- foo.create
- foo.view
provider:
uaa:
jwk-set-uri: http://uaa:8080/uaa/token_keys
token-uri: http://uaa:8080/uaa/oauth/token
user-info-uri: http://uaa:8080/uaa/userinfo (2)
user-name-attribute: user_name
authorization-uri: http://uaa:8080/uaa/oauth/authorize
resourceserver:
opaquetoken: (3)
introspection-uri: http://uaa:8080/uaa/introspect
client-id: dataflow
client-secret: dataflow| 1 | 如果您使用范围来识别角色,请确保同时请求相关范围,例如dataflow.view,dataflow.create并且不要忘记请求openid范围 |
| 2 | 用于检索配置文件信息,例如用于显示目的的用户名(强制) |
| 3 | 用于令牌自省和验证(强制) |
introspection-uri在将外部检索的(不透明的)OAuth 访问令牌传递给 Spring Cloud Data Flow 时,该属性尤其重要。在这种情况下,Spring Cloud Data Flow 将采用 OAuth 访问,并使用 UAA 的Introspect Token Endpoint
不仅检查令牌的有效性,还从 UAA 检索关联的 OAuth 范围
最后启动 Spring Cloud Data Flow:
java -jar spring-cloud-dataflow/spring-cloud-dataflow-server/target/spring-cloud-dataflow-server-2.4.0.BUILD-SNAPSHOT.jar --spring.config.additional-location=scdf.yml角色映射
默认情况下,所有角色都分配给登录 Spring Cloud Data Flow 的用户。但是,您可以设置属性:
spring.cloud.dataflow.security.authorization.provider-role-mappings.uaa.map-oauth-scopes: true
这将指示底层DefaultAuthoritiesExtractor将 OAuth 范围映射到相应的权限。支持以下范围:
-
范围
dataflow.create映射到CREATE角色 -
范围
dataflow.deploy映射到DEPLOY角色 -
范围
dataflow.destroy映射到DESTROY角色 -
范围
dataflow.manage映射到MANAGE角色 -
范围
dataflow.modify映射到MODIFY角色 -
范围
dataflow.schedule映射到SCHEDULE角色 -
范围
dataflow.view映射到VIEW角色
此外,您还可以将任意范围映射到每个数据流角色:
spring:
cloud:
dataflow:
security:
authorization:
provider-role-mappings:
uaa:
map-oauth-scopes: true (1)
role-mappings:
ROLE_CREATE: dataflow.create (2)
ROLE_DEPLOY: dataflow.deploy
ROLE_DESTROY: dataflow.destoy
ROLE_MANAGE: dataflow.manage
ROLE_MODIFY: dataflow.modify
ROLE_SCHEDULE: dataflow.schedule
ROLE_VIEW: dataflow.view| 1 | 启用从 OAuth 范围到数据流角色的显式映射支持 |
| 2 | 启用角色映射支持后,您必须为所有 7 个 Spring Cloud Data Flow 角色ROLE_CREATE、ROLE_DEPLOY、ROLE_DESTROY、ROLE_MANAGE、ROLE_MODIFY、ROLE_SCHEDULE、ROLE_VIEW提供映射。 |
|
您可以将 OAuth 范围分配给多个 Spring Cloud Data Flow 角色,从而使您可以灵活地考虑授权配置的粒度。 |
10.6.4. LDAP 身份验证
LDAP 身份验证(轻量级目录访问协议)由 Spring Cloud Data Flow 使用 UAA 间接提供。UAA 本身提供 全面的 LDAP 支持。
|
虽然您可以使用自己的 OAuth2 身份验证服务器,但此处记录的 LDAP 支持需要使用 UAA 作为身份验证服务器。对于任何其他提供商,请查阅该特定提供商的文档。 |
UAA 支持使用以下模式对 LDAP(轻量级目录访问协议)服务器进行身份验证:
|
当与 LDAP 等外部身份提供者集成时,UAA 中的身份验证变为链式。UAA 首先尝试在外部提供程序 LDAP 之前针对 UAA 用户存储使用用户凭据进行身份验证。有关更多信息,请参阅 用户帐户和身份验证 LDAP 集成GitHub 文档 中的链式身份验证。 |
LDAP 角色映射
存在以下选项:
-
ldap/ldap-groups-null.xml不会映射任何组 -
ldap/ldap-groups-as-scopes.xml组名将从 LDAP 属性中检索。例如CN -
ldap/ldap-groups-map-to-scopes.xml组将使用 external_group_mapping 表映射到 UAA 组
这些值是通过配置属性指定的ldap.groups.file controls。在幕后,这些值引用了 Spring XML 配置文件。
|
在测试和开发期间,可能需要对 LDAP 组和用户进行频繁更改,并查看 UAA 中反映的内容。但是,在登录期间会缓存用户信息。以下脚本有助于快速检索更新的信息: |
LDAP 安全性和 UAA 示例应用程序
为了快速启动和运行并帮助您了解安全架构,我们 在 GitHub 上提供了LDAP 安全和 UAA 示例。
|
这只是一个演示/示例应用程序,不得用于生产。 |
设置包括:
-
Spring Cloud 数据流服务器
-
船长服务器
-
CloudFoundry 用户帐户和身份验证 (UAA) 服务器
-
轻量级目录访问协议 (LDAP) 服务器(由Apache Directory Server (ApacheDS) 提供)
最后,作为本示例的一部分,您将学习如何使用此安全设置配置和启动组合任务。
10.6.5。Spring Security OAuth2 资源/授权服务器示例
对于本地测试和开发,您还可以使用 Spring Security OAuth提供的 Resource and Authorization Server 支持。它允许您使用以下简单注释轻松创建自己的(非常基本的)OAuth2 服务器:
-
@EnableResourceServer -
@EnableAuthorizationServer
| 事实上,UAA 在后台使用 Spring Security OAuth2,因此基本端点是相同的。 |
可以在以下位置找到一个工作示例应用程序: https ://github.com/ghillert/oauth-test-server/
克隆项目并使用各自的 Client ID 和 Client Secret 配置 Spring Cloud Data Flow:
security:
oauth2:
client:
client-id: myclient
client-secret: mysecret
access-token-uri: http://127.0.0.1:9999/oauth/token
user-authorization-uri: http://127.0.0.1:9999/oauth/authorize
resource:
user-info-uri: http://127.0.0.1:9999/me
token-info-uri: http://127.0.0.1:9999/oauth/check_token| 此示例应用程序不适用于生产用途 |
10.6.6。数据流外壳认证
使用 Shell 时,可以通过用户名和密码或通过指定credentials-provider命令来提供凭据。如果您的 OAuth2 提供者支持密码授予类型,您可以使用以下命令启动数据流外壳:
$ java -jar spring-cloud-dataflow-shell-2.9.4.jar \
--dataflow.uri=http://localhost:9393 \ (1)
--dataflow.username=my_username \ (2)
--dataflow.password=my_password \ (3)
--skip-ssl-validation true \ (4)| 1 | 可选,默认为localhost:9393。 |
| 2 | 强制的。 |
| 3 | 如果未提供密码,则会提示用户输入密码。 |
| 4 | 可选,默认为false,忽略证书错误(使用自签名证书时)。谨慎使用! |
| 请记住,启用 Spring Cloud Data Flow 的身份验证后,如果您想通过用户名/密码身份验证使用 Shell ,则底层 OAuth2 提供程序必须支持Password OAuth2 Grant Type。 |
在 Data Flow Shell 中,您还可以使用以下命令提供凭据:
server-unknown:>dataflow config server \
--uri http://localhost:9393 \ (1)
--username myuser \ (2)
--password mysecret \ (3)
--skip-ssl-validation true \ (4)| 1 | 可选,默认为localhost:9393。 |
| 2 | 强制的.. |
| 3 | 如果启用了安全性,但未提供密码,则会提示用户输入密码。 |
| 4 | 可选,忽略证书错误(使用自签名证书时)。谨慎使用! |
下图显示了用于连接数据流服务器并对其进行身份验证的典型 shell 命令:

成功定位后,您应该会看到以下输出:
dataflow:>dataflow config info
dataflow config info
╔═══════════╤═══════════════════════════════════════╗
║Credentials│[username='my_username, password=****']║
╠═══════════╪═══════════════════════════════════════╣
║Result │ ║
║Target │http://localhost:9393 ║
╚═══════════╧═══════════════════════════════════════╝或者,您可以指定credentials-provider命令以直接传入不记名令牌,而不是提供用户名和密码。这可以在 shell 内工作,也可以在启动 shell 时提供
--dataflow.credentials-provider-command命令行参数。
|
使用credentials-provider命令时,请注意您指定的命令必须返回一个Bearer 令牌(Access Token 前缀为Bearer)。例如,在 Unix 环境中,可以使用以下简单命令: |
10.7。关于配置
Spring Cloud Data Flow About Restful API 结果包含一个显示名称、版本,以及(如果指定)组成 Spring Cloud Data Flow 的每个主要依赖项的 URL。结果(如果启用)还包含 shell 依赖项的 sha1 和/或 sha256 校验和值。通过设置以下属性可以配置为每个依赖项返回的信息:
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-core.name:用于核心的名称。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-core.version:用于核心的版本。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-dashboard.name:用于仪表板的名称。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-dashboard.version:用于仪表板的版本。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-implementation.name:用于实现的名称。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-implementation.version:用于实现的版本。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.name:用于外壳的名称。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.version:用于shell的版本。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.url:用于下载shell依赖的URL。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.checksum-sha1:与shell依赖信息一起返回的sha1校验和值。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.checksum-sha256:与shell依赖信息一起返回的sha256校验和值。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.checksum-sha1-url:如果
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.checksum-sha1未指定,SCDF 使用此 URL 指定的文件内容进行校验和。 -
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.checksum-sha256-url:如果
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.checksum-sha256未指定,SCDF 使用此 URL 指定的文件内容进行校验和。
10.7.1. 启用 Shell 校验和值
默认情况下,不显示 shell 依赖项的校验和值。如果您需要启用此功能,请将
spring.cloud.dataflow.version-info.dependency-fetch.enabled属性设置为 true。
10.7.2. URL 的保留值
您可以将保留值(用大括号括起来)插入到 URL 中,以确保链接是最新的:
-
存储库:如果使用数据流的构建快照、里程碑或发布候选,存储库指的是 repo-spring-io 存储库。否则,它指的是 Maven Central。
-
version:插入 jar/pom 的版本。
例如,
如果您使用 Spring Cloud Data Flow Shell 的 1.2.3.RELEASE 版本,则myrepository/org/springframework/cloud/spring-cloud-dataflow-shell/{version}/spring-cloud-dataflow-shell-{version}.jar
生成
myrepository/org/springframework/cloud/spring-cloud-dataflow-shell/1.2.3.RELEASE/spring-cloud-dataflow-shell-1.2.3.RELEASE.jar
11. 配置 - Cloud Foundry
本节介绍如何配置 Spring Cloud Data Flow 服务器的功能,例如安全性和使用哪个关系数据库。它还描述了如何配置 Spring Cloud Data Flow shell 的功能。
11.1。功能切换
数据流服务器提供了一组特定的功能,您可以在启动时启用或禁用这些功能。这些功能包括所有生命周期操作和 REST 端点(服务器、客户端实现,包括 Shell 和 UI):
-
流
-
任务
您可以在启动数据流服务器时通过设置以下布尔属性来启用或禁用这些功能:
-
spring.cloud.dataflow.features.streams-enabled -
spring.cloud.dataflow.features.tasks-enabled
默认情况下,所有功能都已启用。
REST 端点 ( /features) 提供有关启用和禁用功能的信息。
11.2. 部署者属性
您可以使用 Data Flow 服务器的Cloud Foundry 部署程序的以下配置属性来自定义应用程序的部署方式。使用 Data Flow shell 进行部署时,您可以使用语法deployer.<appName>.cloudfoundry.<deployerPropertyName>. 有关 shell 用法的示例,请参见下文。这些属性也用于在 Data Flow 服务器中配置Cloud Foundry Task 平台和在 Skipper 中配置 Kubernetes 平台以部署 Streams。
| 部署者属性名称 | 描述 | 默认值 |
|---|---|---|
服务 |
要绑定到已部署应用程序的服务的名称。 |
<无> |
主持人 |
用作路由一部分的主机名。 |
由 Cloud Foundry 派生的主机名 |
领域 |
为应用程序映射路由时要使用的域。 |
<无> |
路线 |
应用程序应绑定到的路由列表。与主机和域互斥。 |
<无> |
构建包 |
用于部署应用程序的 buildpack。不推荐使用构建包。 |
|
构建包 |
用于部署应用程序的构建包列表。 |
|
记忆 |
要分配的内存量。默认单位是兆字节,支持“M”和“G”后缀 |
1024米 |
磁盘 |
要分配的磁盘空间量。默认单位是兆字节,支持“M”和“G”后缀。 |
1024米 |
健康检查 |
对部署的应用程序执行的健康检查类型。值可以是 HTTP、NONE、PROCESS 和 PORT |
港口 |
健康检查HttpEndpoint |
http 健康检查将使用的路径, |
/健康 |
健康检查超时 |
运行状况检查的超时值(以秒为单位)。 |
120 |
实例 |
要运行的实例数。 |
1 |
enableRandomAppNamePrefix |
标记以启用使用随机前缀为应用程序名称添加前缀。 |
真的 |
api超时 |
阻塞 API 调用的超时时间,以秒为单位。 |
360 |
状态超时 |
状态 API 操作的超时时间(以毫秒为单位) |
5000 |
使用SpringApplicationJson |
标志以指示应用程序属性是馈入 |
真的 |
暂存超时 |
为暂存应用程序分配的超时。 |
15分钟 |
启动超时 |
为启动应用程序分配的超时。 |
5分钟 |
应用名称前缀 |
用作已部署应用程序名称前缀的字符串 |
|
删除路由 |
取消部署应用程序时是否也删除路由。 |
真的 |
javaOpts |
传递给 JVM 的 Java 选项,例如 -Dtest=foo |
<无> |
pushTasksEnabled |
是推送任务应用程序还是假设应用程序在启动时已经存在。 |
真的 |
autoDeleteMavenArtifacts |
部署时是否自动从本地存储库中删除 Maven 工件。 |
真的 |
环境。<键> |
定义顶级环境变量。这对于自定义Java 构建包配置很有用,因为 Java 构建包无法识别,所以必须将其作为顶级环境变量包含在应用程序清单中 |
部署程序确定应用程序的类路径中是否包含Java CfEnv。如果是这样,它会应用所需的配置。 |
以下是一些使用 Cloud Foundry 部署属性的示例:
-
您可以设置用于部署每个应用程序的 buildpack。例如,要使用 Java 离线构建,请设置以下环境变量:
cf set-env dataflow-server SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_BUILDPACKS java_buildpack_offline-
设置
buildpack现在已被弃用,buildpacks它允许您在需要时传递多个。可以从Buildpacks 的工作原理中找到有关此内容的更多信息。 -
您可以自定义 Cloud Foundry 使用的运行状况检查机制,以使用
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_HEALTH_CHECK环境变量来断言应用程序是否正在运行。当前支持的选项是http(默认)port、 和none。
您还可以设置环境变量,分别指定基于 HTTP 的健康检查端点和 timeout:SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_HEALTH_CHECK_ENDPOINT和SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_HEALTH_CHECK_TIMEOUT。这些默认为/health(Spring Boot 默认位置)和120秒。
-
您还可以使用 DSL 指定部署属性。例如,如果要将
http应用程序分配的内存设置为 512m,并将 mysql 服务绑定到jdbc应用程序,则可以运行以下命令:
dataflow:> stream create --name mysqlstream --definition "http | jdbc --tableName=names --columns=name"
dataflow:> stream deploy --name mysqlstream --properties "deployer.http.memory=512, deployer.jdbc.cloudfoundry.services=mysql"|
您可以为流应用程序和任务应用程序单独配置这些设置。要更改任务的设置,请替换 |
11.3. 任务
数据流服务器负责部署任务。数据流启动的任务将其状态写入数据流服务器使用的同一数据库。对于作为 Spring Batch 作业的任务,作业和步骤执行数据也存储在此数据库中。与 Skipper 一样,任务可以启动到多个平台。当 Data Flow 在 Cloud Foundry 上运行时,必须定义一个任务平台。要配置以 Cloud Foundry 为目标的新平台帐户,spring.cloud.dataflow.task.platform.cloudfoundry请在文件的部分下提供一个条目,application.yaml以通过另一个 Spring Boot 支持的机制。在以下示例中,创建了两个名为dev和qa的 Cloud Foundry 平台帐户。memory和之类的键disk是Cloud Foundry Deployer Properties。
spring:
cloud:
dataflow:
task:
platform:
cloudfoundry:
accounts:
dev:
connection:
url: https://api.run.pivotal.io
org: myOrg
space: mySpace
domain: cfapps.io
username: user@example.com
password: drowssap
skipSslValidation: false
deployment:
memory: 512m
disk: 2048m
instances: 4
services: rabbit,mysql
appNamePrefix: dev1
qa:
connection:
url: https://api.run.pivotal.io
org: myOrgQA
space: mySpaceQA
domain: cfapps.io
username: user@example.com
password: drowssap
skipSslValidation: true
deployment:
memory: 756m
disk: 724m
instances: 2
services: rabbitQA,mysqlQA
appNamePrefix: qa1
通过将一个平台定义为default允许您跳过platformName在其他情况下需要使用它的地方。
|
启动任务时,使用任务启动选项传递平台帐户名称的值--platformName如果不传递 的值,将使用platformName该值。default
| 将一个任务部署到多个平台时,该任务的配置需要和Data Flow Server连接同一个数据库。 |
您可以配置 Cloud Foundry 上的 Data Flow 服务器以将任务部署到 Cloud Foundry 或 Kubernetes。有关更多信息,请参阅Kubernetes 任务平台配置部分。
跨多个平台启动和调度任务的详细示例,请参阅 dataflow.spring.io上的多平台支持任务部分。
11.4. 应用程序名称和前缀
为了帮助避免与 Cloud Foundry 中跨空间的路由发生冲突,可以使用一种命名策略,该策略为已部署的应用程序提供随机前缀,并且默认情况下已启用。
您可以使用命令覆盖默认配置并设置相应的属性。cf set-env
例如,如果要禁用随机化,可以使用以下命令覆盖它:
cf set-env dataflow-server SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_ENABLE_RANDOM_APP_NAME_PREFIX false11.5。自定义路线
作为随机名称的替代方案,或者为了更好地控制已部署应用程序使用的主机名,您可以使用自定义部署属性,如以下示例所示:
dataflow:>stream create foo --definition "http | log"
sdataflow:>stream deploy foo --properties "deployer.http.cloudfoundry.domain=mydomain.com,
deployer.http.cloudfoundry.host=myhost,
deployer.http.cloudfoundry.route-path=my-path"前面的示例将http应用程序绑定到myhost.mydomain.com/my-pathURL。请注意,此示例显示了所有可用的自定义选项。在实践中,您只能使用三种中的一种或两种。
11.6。码头工人应用
从 1.2 版开始,可以使用 Data Flow for Cloud Foundry 将基于 Docker 的应用程序注册和部署为流和任务的一部分。
如果你使用 Spring Boot 和基于 RabbitMQ 的 Docker 镜像,你可以提供一个通用的部署属性来方便将应用绑定到 RabbitMQ 服务。假设您的 RabbitMQ 服务名为rabbit,您可以提供以下内容:
cf set-env dataflow-server SPRING_APPLICATION_JSON '{"spring.cloud.dataflow.applicationProperties.stream.spring.rabbitmq.addresses": "${vcap.services.rabbit.credentials.protocols.amqp.uris}"}'对于 Spring Cloud Task 应用程序,如果您使用名为的数据库服务实例,则可以使用类似于以下内容的内容mysql:
cf set-env SPRING_DATASOURCE_URL '${vcap.services.mysql.credentials.jdbcUrl}'
cf set-env SPRING_DATASOURCE_USERNAME '${vcap.services.mysql.credentials.username}'
cf set-env SPRING_DATASOURCE_PASSWORD '${vcap.services.mysql.credentials.password}'
cf set-env SPRING_DATASOURCE_DRIVER_CLASS_NAME 'org.mariadb.jdbc.Driver'对于非 Java 或非 Boot 应用程序,您的 Docker 应用程序必须解析VCAP_SERVICES变量才能绑定到任何可用服务。
|
传递应用程序属性
使用非引导应用程序时,您可能希望通过使用传统环境变量而不是使用特殊 |
11.7。应用程序级服务绑定
在 Cloud Foundry 中部署流时,您可以利用特定于应用程序的服务绑定,因此并非所有服务都是为 Spring Cloud Data Flow 编排的所有应用程序全局配置的。
例如,如果您只想为以下流定义中mysql的应用程序提供服务绑定jdbc,则可以将服务绑定作为部署属性传递:
dataflow:>stream create --name httptojdbc --definition "http | jdbc"
dataflow:>stream deploy --name httptojdbc --properties "deployer.jdbc.cloudfoundry.services=mysqlService"其中mysqlService是专门绑定到jdbc应用程序的服务的名称,并且http
应用程序不会通过此方法获得绑定。
如果您有多个要绑定的服务,它们可以作为逗号分隔的项目传递(例如:deployer.jdbc.cloudfoundry.services=mysqlService,someService)。
11.8。配置服务绑定参数
CloudFoundry API 支持在绑定服务实例时提供配置参数。一些服务代理需要或推荐绑定配置。例如,使用 CF CLI 绑定Google Cloud Platform 服务如下所示:
cf bind-service my-app my-google-bigquery-example -c '{"role":"bigquery.user"}'同样,NFS 卷服务支持绑定配置,例如:
cf bind-service my-app nfs_service_instance -c '{"uid":"1000","gid":"1000","mount":"/var/volume1","readonly":true}'从 2.0 版开始,Data Flow for Cloud Foundry 允许您提供绑定配置参数,这些参数可以在应用程序级别或服务器级别cloudfoundry.services部署属性中提供。例如,要绑定到 nfs 服务,如上:
dataflow:> stream deploy --name mystream --properties "deployer.<app>.cloudfoundry.services='nfs_service_instance uid:1000,gid:1000,mount:/var/volume1,readonly:true'"该格式旨在与数据流 DSL 解析器兼容。通常,cloudfoundry.services部署属性接受逗号分隔的值。由于逗号也用于分隔配置参数,为了避免空格问题,包括配置参数在内的任何项目都必须用单引号括起来。有效值包括以下内容:
rabbitmq,'nfs_service_instance uid:1000,gid:1000,mount:/var/volume1,readonly:true',mysql,'my-google-bigquery-example role:bigquery.user'
单引号中允许使用空格,并且=可以使用空格代替:分隔键值对。
|
11.9。用户提供的服务
除了市场服务,Cloud Foundry 还支持 用户提供的服务(UPS)。在整个参考手册中,都提到了常规服务,但也没有排除使用用户提供的服务,无论是用作消息传递中间件(例如,如果您想使用外部 Apache Kafka 安装)还是用于由某些流应用程序(例如,Oracle 数据库)使用。
现在我们回顾一个从 UPS 提取和提供连接凭证的示例。
以下示例显示了 Apache Kafka 的示例 UPS 设置:
cf create-user-provided-service kafkacups -p '{”brokers":"HOST:PORT","zkNodes":"HOST:PORT"}'UPS 凭证包含在VCAP_SERVICES中,它们可以直接在流定义中提供,如下例所示。
stream create fooz --definition "time | log"
stream deploy fooz --properties "app.time.spring.cloud.stream.kafka.binder.brokers=${vcap.services.kafkacups.credentials.brokers},app.time.spring.cloud.stream.kafka.binder.zkNodes=${vcap.services.kafkacups.credentials.zkNodes},app.log.spring.cloud.stream.kafka.binder.brokers=${vcap.services.kafkacups.credentials.brokers},app.log.spring.cloud.stream.kafka.binder.zkNodes=${vcap.services.kafkacups.credentials.zkNodes}"11.10。数据库连接池
从 Data Flow 2.0 开始,不再使用 Spring Cloud Connector 库来创建 DataSource。现在使用库java-cfenv,它允许您设置Spring Boot 属性以配置连接池。
11.11。最大磁盘配额
默认情况下,Cloud Foundry 中的每个应用程序都以 1G 磁盘配额开始,并且可以将其调整为默认最大值 2G。使用 Pivotal Cloud Foundry (PCF) Ops Manager GUI 也可以覆盖默认最大值,最高可达 10G。
此配置与 Spring Cloud Data Flow 相关,因为每个任务部署都由应用程序(通常是 Spring Boot uber-jar)组成,并且这些应用程序是从远程 maven 存储库中解析的。解析后,应用程序工件被下载到本地 Maven 存储库以进行缓存和重用。在后台发生这种情况时,默认磁盘配额 (1G) 可能会迅速填满,尤其是当我们对由独特应用程序组成的流进行试验时。为了克服此磁盘限制并根据您的扩展要求,您可能需要将默认最大值从 2G 更改为 10G。让我们回顾一下更改默认最大磁盘配额分配的步骤。
11.11.1。PCF 运营经理
从 PCF 的 Ops Manager 中,选择“Pivotal Elastic Runtime”磁贴并导航到“Application Developer Controls”选项卡。将“每个应用程序的最大磁盘配额 (MB)”设置从 2048 (2G) 更改为 10240 (10G)。保存磁盘配额更新并单击“应用更改”以完成配置覆盖。
11.12。规模应用
成功应用磁盘配额更改并假设您有一个正在运行的应用程序,您可以通过 CF CLI 使用新的应用程序扩展应用程序disk_limit,如以下示例所示:
→ cf scale dataflow-server -k 10GB
Scaling app dataflow-server in org ORG / space SPACE as user...
OK
....
....
....
....
state since cpu memory disk details
#0 running 2016-10-31 03:07:23 PM 1.8% 497.9M of 1.1G 193.9M of 10G然后,您可以列出应用程序并查看新的最大磁盘空间,如以下示例所示:
→ cf apps
Getting apps in org ORG / space SPACE as user...
OK
name requested state instances memory disk urls
dataflow-server started 1/1 1.1G 10G dataflow-server.apps.io11.13。管理磁盘使用
即使将数据流服务器配置为使用 10G 的空间,也有可能耗尽本地磁盘上的可用空间。为了防止这种情况,无论部署请求是否成功,每当部署应用程序时,都会自动删除jar从外部源(即注册为http或资源的应用程序)下载的工件。maven对于容器运行时稳定性比部署期间产生的 I/O 延迟更重要的生产环境,此行为是最佳的。在开发环境中,部署发生得更频繁。此外,jar神器(或打火机metadatajar)包含描述应用程序配置属性的元数据,这些属性由与应用程序配置相关的各种操作使用,在预生产活动期间更频繁地执行(有关详细信息,请参阅应用程序元数据)。为了在预生产环境中以更多磁盘使用为代价提供响应更快的交互式开发人员体验,您可以将 CloudFoundry 部署程序属性设置autoDeleteMavenArtifacts为false.
如果使用默认port健康检查类型部署数据流服务器,则必须显式监控服务器上的磁盘空间以避免空间不足。如果您使用http运行状况检查类型部署服务器(请参见下一个示例),则在磁盘空间不足时会重新启动数据流服务器。这是由于 Spring Boot 的Disk Space Health Indicator。您可以使用带有前缀的属性来配置磁盘空间运行状况指示器的设置。management.health.diskspace
对于 1.7 版,我们正在研究使用数据流服务器的卷服务来存储.jar工件,然后再将它们推送到 Cloud Foundry。
以下示例显示如何将http运行状况检查类型部署到名为 的端点/management/health:
---
...
health-check-type: http
health-check-http-endpoint: /management/health11.14。应用程序解决方案
尽管我们建议使用 Maven Artifactory 为应用程序注册一个流应用程序,但在某些情况下,以下替代方法之一可能会有意义。
-
我们已经定制并维护了一个SCDF APP Tool ,它可以作为 Cloud Foundry 中的常规 Spring Boot 应用程序运行,但它又会在运行时为 SCDF 托管和提供应用程序 JAR。
-
借助 Spring Boot,我们可以 在 Cloud Foundry中提供静态内容。一个简单的 Spring Boot 应用程序可以捆绑所有需要的流和任务应用程序。通过在 Cloud Foundry 上运行,静态应用程序可以为 über-jar 提供服务。例如,在 shell 中,您可以
http-source.jar使用--uri=http://<Route-To-StaticApp>/http-source.jar. -
über-jar 可以托管在可通过 HTTP 访问的任何外部服务器上。它们也可以从原始 GitHub URI 中解析。例如,在 shell 中,您可以
http-source.jar使用--uri=http://<Raw_GitHub_URI>/http-source.jar. -
Cloud Foundry 中的静态 Buildpack支持是另一种选择。类似的 HTTP 解析也适用于此模型。
-
批量服务是另一个不错的选择。所需的 über-jar 可以托管在外部文件系统中。例如,借助卷服务,您可以
http-source.jar使用--uri=file://<Path-To-FileSystem>/http-source.jar.
11.15。安全
默认情况下,数据流服务器是不安全的,并在未加密的 HTTP 连接上运行。您可以通过启用 HTTPS 并要求客户端进行身份验证来保护您的 REST 端点(以及数据流仪表板)。有关保护 REST 端点和配置以针对 OAUTH 后端(在 Cloud Foundry 上运行的 UAA 和 SSO)进行身份验证的更多详细信息,请参阅核心[configuration-local-security]中的安全部分。您可以通过命令配置安全详细信息dataflow-server.yml或将它们作为环境变量传递cf set-env。
11.15.1。验证
Spring Cloud Data Flow 可以与 Pivotal Single Sign-On Service(例如,在 PWS 上)或 Cloud Foundry 用户帐户和身份验证 (UAA) 服务器集成。
Pivotal 单点登录服务
将 Spring Cloud Data Flow 部署到 Cloud Foundry 时,您可以将应用程序绑定到 Pivotal Single Sign-On Service。通过这样做,Spring Cloud Data Flow 利用了 Java CFEnv,它为 OAuth 2.0 提供了 Cloud Foundry 特定的自动配置支持。
为此,请将 Pivotal Single Sign-On Service 绑定到您的 Data Flow Server 应用程序并提供以下属性:
SPRING_CLOUD_DATAFLOW_SECURITY_CFUSEUAA: false (1)
SECURITY_OAUTH2_CLIENT_CLIENTID: "${security.oauth2.client.clientId}"
SECURITY_OAUTH2_CLIENT_CLIENTSECRET: "${security.oauth2.client.clientSecret}"
SECURITY_OAUTH2_CLIENT_ACCESSTOKENURI: "${security.oauth2.client.accessTokenUri}"
SECURITY_OAUTH2_CLIENT_USERAUTHORIZATIONURI: "${security.oauth2.client.userAuthorizationUri}"
SECURITY_OAUTH2_RESOURCE_USERINFOURI: "${security.oauth2.resource.userInfoUri}"| 1 | 将属性spring.cloud.dataflow.security.cf-use-uaa设置为false |
非 Cloud Foundry 安全场景同样支持授权。请参阅核心数据流[configuration-local-security]中的安全部分。
由于角色的配置在不同环境中可能会有很大差异,我们默认将所有 Spring Cloud Data Flow 角色分配给用户。
您可以通过提供自己的AuthoritiesExtractor.
以下示例显示了在 上设置自定义AuthoritiesExtractor的一种可能方法UserInfoTokenServices:
public class MyUserInfoTokenServicesPostProcessor
implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) {
if (bean instanceof UserInfoTokenServices) {
final UserInfoTokenServices userInfoTokenServices == (UserInfoTokenServices) bean;
userInfoTokenServices.setAuthoritiesExtractor(ctx.getBean(AuthoritiesExtractor.class));
}
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) {
return bean;
}
}然后你可以在你的配置类中声明它,如下所示:
@Bean
public BeanPostProcessor myUserInfoTokenServicesPostProcessor() {
BeanPostProcessor postProcessor == new MyUserInfoTokenServicesPostProcessor();
return postProcessor;
}Cloud Foundry UAA
Cloud Foundry 用户帐户和身份验证 (UAA) 的可用性取决于 Cloud Foundry 环境。为了提供 UAA 集成,您必须提供必要的 OAuth2 配置属性(例如,通过设置SPRING_APPLICATION_JSON
属性)。
以下 JSON 示例展示了如何创建安全配置:
{
"security.oauth2.client.client-id": "scdf",
"security.oauth2.client.client-secret": "scdf-secret",
"security.oauth2.client.access-token-uri": "https://login.cf.myhost.com/oauth/token",
"security.oauth2.client.user-authorization-uri": "https://login.cf.myhost.com/oauth/authorize",
"security.oauth2.resource.user-info-uri": "https://login.cf.myhost.com/userinfo"
}默认情况下,该spring.cloud.dataflow.security.cf-use-uaa属性设置为true。此属性激活一个特殊的
AuthoritiesExtractor称为CloudFoundryDataflowAuthoritiesExtractor.
如果您不使用 CloudFoundry UAA,则应设置spring.cloud.dataflow.security.cf-use-uaa为false.
在幕后,这AuthoritiesExtractor调用了
Cloud Foundry Apps API并确保用户实际上是 Space Developers。
如果经过身份验证的用户被验证为 Space Developer,则分配所有角色。
11.16。配置参考
您必须提供几项配置。这些是 Spring Boot @ConfigurationProperties,因此您可以将它们设置为环境变量或通过 Spring Boot 支持的任何其他方式。以下清单采用环境变量格式,因为这是开始在 Cloud Foundry 中配置引导应用程序的简单方法。请注意,将来您将能够将任务部署到多个平台,但对于 2.0.0.M1,您只能部署到单个平台,并且名称必须是default.
# Default values appear after the equal signs.
# Example values, typical for Pivotal Web Services, are included as comments.
# URL of the CF API (used when using cf login -a for example) - for example, https://api.run.pivotal.io
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_URL=
# The name of the organization that owns the space above - for example, youruser-org
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_ORG=
# The name of the space into which modules will be deployed - for example, development
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SPACE=
# The root domain to use when mapping routes - for example, cfapps.io
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_DOMAIN=
# The user name and password of the user to use to create applications
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_USERNAME=
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_PASSWORD
# The identity provider to be used when accessing the Cloud Foundry API (optional).
# The passed string has to be a URL-Encoded JSON Object, containing the field origin with value as origin_key of an identity provider - for example, {"origin":"uaa"}
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_LOGIN_HINT=
# Whether to allow self-signed certificates during SSL validation (you should NOT do so in production)
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SKIP_SSL_VALIDATION
# A comma-separated set of service instance names to bind to every deployed task application.
# Among other things, this should include an RDBMS service that is used
# for Spring Cloud Task execution reporting, such as my_postgres
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_SERVICES
spring.cloud.deployer.cloudfoundry.task.services=
# Timeout, in seconds, to use when doing blocking API calls to Cloud Foundry
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_API_TIMEOUT=
# Timeout, in milliseconds, to use when querying the Cloud Foundry API to compute app status
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_STATUS_TIMEOUT请注意,您可以使用快捷方式设置spring.cloud.deployer.cloudfoundry.services、
spring.cloud.deployer.cloudfoundry.buildpacks或 Spring Cloud Deployer-standard
spring.cloud.deployer.memory并spring.cloud.deployer.disk
作为单个部署请求的一部分deployer.<app-name>,如以下示例所示:
stream create --name ticktock --definition "time | log"
stream deploy --name ticktock --properties "deployer.time.memory=2g"上例中的命令使用 2048MB 内存部署时间源,而日志接收器使用默认的 1024MB。
部署流时,还可以JAVA_OPTS作为部署属性传递,如以下示例所示:
stream deploy --name ticktock --properties "deployer.time.cloudfoundry.javaOpts=-Duser.timezone=America/New_York"11.17。调试
如果您想更好地了解部署流和任务时发生的情况,您可能需要打开以下功能:
-
反应堆“堆栈跟踪”,显示在发生错误之前涉及哪些操作员。此功能很有帮助,因为部署者依赖于项目反应器,并且常规堆栈跟踪可能并不总是允许在错误发生之前了解流程。请注意,这会带来性能损失,因此默认情况下它是禁用的。
spring.cloud.dataflow.server.cloudfoundry.debugReactor == true-
部署程序和 Cloud Foundry 客户端库请求和响应日志。此功能允许查看数据流服务器和 Cloud Foundry 云控制器之间的详细对话。
logging.level.cloudfoundry-client == DEBUG11.18。Spring Cloud 配置服务器
您可以使用 Spring Cloud Config Server 来集中 Spring Boot 应用程序的配置属性。同样,Spring Cloud Data Flow 和 Spring Cloud Data Flow 编排的应用程序都可以与配置服务器集成以使用相同的功能。
11.18.1。流、任务和 Spring Cloud 配置服务器
与 Spring Cloud Data Flow 服务器类似,您可以配置流和任务应用程序以从配置服务器解析集中属性。为已部署的应用程序设置spring.cloud.config.uri属性是绑定到配置服务器的常用方法。有关更多信息,请参阅Spring Cloud Config Client参考指南。由于该属性可能会在数据流服务器部署的所有应用程序中使用,因此数据流服务器的spring.cloud.dataflow.applicationProperties.stream流应用程序spring.cloud.dataflow.applicationProperties.task属性和任务应用程序属性可用于将uri配置服务器的属性传递给每个部署的流或任务应用程序。有关详细信息,请参阅通用应用程序属性部分。
请注意,如果您使用App Starters 项目中的应用程序,这些应用程序已经嵌入了spring-cloud-services-starter-config-client依赖项。如果您从头开始构建应用程序并希望为配置服务器添加客户端支持,您可以添加对配置服务器客户端库的依赖项引用。以下片段显示了一个 Maven 示例:
...
<dependency>
<groupId>io.pivotal.spring.cloud</groupId>
<artifactId>spring-cloud-services-starter-config-client</artifactId>
<version>CONFIG_CLIENT_VERSION</version>
</dependency>
...哪里CONFIG_CLIENT_VERSION可以是
Pivotal Cloud Foundry的Spring Cloud Config Server客户端的最新版本。
如果使用此库的应用程序在应用程序启动和访问端点WARN时无法连接到配置服务器,
您可能会看到一条日志消息。/health如果您知道您没有使用配置服务器功能,您可以通过将
SPRING_CLOUD_CONFIG_ENABLED环境变量设置为 来禁用客户端库false。
|
11.18.2。样品清单模板
以下 SCDF 和 Skippermanifest.yml模板包括 Skipper 和 Spring Cloud Data Flow 服务器所需的环境变量以及部署的应用程序和任务,以便在 Cloud Foundry 上成功运行并my-config-server在运行时自动解析集中属性:
---
applications:
- name: data-flow-server
host: data-flow-server
memory: 2G
disk_quota: 2G
instances: 1
path: {PATH TO SERVER UBER-JAR}
env:
SPRING_APPLICATION_NAME: data-flow-server
MAVEN_REMOTE_REPOSITORIES_REPO1_URL: https://repo.spring.io/libs-snapshot
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_URL: https://api.sys.huron.cf-app.com
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_ORG: sabby20
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SPACE: sabby20
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_DOMAIN: apps.huron.cf-app.com
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_USERNAME: admin
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_PASSWORD: ***
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SKIP_SSL_VALIDATION: true
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_SERVICES: mysql
SPRING_CLOUD_SKIPPER_CLIENT_SERVER_URI: https://<skipper-host-name>/api
services:
- mysql
- my-config-server
---
applications:
- name: skipper-server
host: skipper-server
memory: 1G
disk_quota: 1G
instances: 1
timeout: 180
buildpack: java_buildpack
path: <PATH TO THE DOWNLOADED SKIPPER SERVER UBER-JAR>
env:
SPRING_APPLICATION_NAME: skipper-server
SPRING_CLOUD_SKIPPER_SERVER_ENABLE_LOCAL_PLATFORM: false
SPRING_CLOUD_SKIPPER_SERVER_STRATEGIES_HEALTHCHECK_TIMEOUTINMILLIS: 300000
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_URL: https://api.local.pcfdev.io
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_ORG: pcfdev-org
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SPACE: pcfdev-space
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_DOMAIN: cfapps.io
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_USERNAME: admin
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_PASSWORD: admin
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SKIP_SSL_VALIDATION: false
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_DELETE_ROUTES: false
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_SERVICES: rabbit, my-config-server
services:
- mysql
my-config-server其中my-config-server是 Cloud Foundry 上运行的 Spring Cloud Config Service 实例的名称。
通过将服务分别绑定到 Spring Cloud Data Flow 服务器、Spring Cloud Task 和通过 Skipper 到所有 Spring Cloud Stream 应用程序,我们现在可以解析由该服务支持的集中属性。
11.18.3。自签名 SSL 证书和 Spring Cloud Config Server
通常,在开发环境中,我们可能没有有效的证书来启用客户端和后端服务之间的 SSL 通信。但是,Pivotal Cloud Foundry 的配置服务器使用 HTTPS 进行所有客户端到服务的通信,因此我们需要在没有有效证书的环境中添加自签名 SSL 证书。
通过使用manifest.yml上一节中列出的用于服务器的相同模板,我们可以通过设置来提供自签名 SSL 证书TRUST_CERTS: <API_ENDPOINT>。
但是,部署的应用程序还需要TRUST_CERTS一个平面环境变量(而不是被包裹在里面SPRING_APPLICATION_JSON),所以我们必须用另一组令牌(SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_USE_SPRING_APPLICATION_JSON: false)来指示服务器执行任务。通过此设置,应用程序将其应用程序属性作为常规环境变量接收。
以下清单显示了manifest.yml所需更改的更新。Data Flow 服务器和部署的应用程序都从my-config-serverCloud Config 服务器(部署为 Cloud Foundry 服务)获取配置。
---
applications:
- name: test-server
host: test-server
memory: 1G
disk_quota: 1G
instances: 1
path: spring-cloud-dataflow-server-VERSION.jar
env:
SPRING_APPLICATION_NAME: test-server
MAVEN_REMOTE_REPOSITORIES_REPO1_URL: https://repo.spring.io/libs-snapshot
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_URL: https://api.sys.huron.cf-app.com
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_ORG: sabby20
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SPACE: sabby20
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_DOMAIN: apps.huron.cf-app.com
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_USERNAME: admin
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_PASSWORD: ***
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SKIP_SSL_VALIDATION: true
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_SERVICES: mysql, config-server
SPRING_CLOUD_SKIPPER_CLIENT_SERVER_URI: https://<skipper-host-name>/api
TRUST_CERTS: <API_ENDPOINT> #this is for the server
SPRING_CLOUD_DATAFLOW_APPLICATION_PROPERTIES_TASK_TRUST_CERTS: <API_ENDPOINT> #this propagates to all tasks
services:
- mysql
- my-config-server #this is for the server还将服务添加my-config-server到船长的清单环境中
---
applications:
- name: skipper-server
host: skipper-server
memory: 1G
disk_quota: 1G
instances: 1
timeout: 180
buildpack: java_buildpack
path: <PATH TO THE DOWNLOADED SKIPPER SERVER UBER-JAR>
env:
SPRING_APPLICATION_NAME: skipper-server
SPRING_CLOUD_SKIPPER_SERVER_ENABLE_LOCAL_PLATFORM: false
SPRING_CLOUD_SKIPPER_SERVER_STRATEGIES_HEALTHCHECK_TIMEOUTINMILLIS: 300000
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_URL: <URL>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_ORG: <ORG>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SPACE: <SPACE>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_DOMAIN: <DOMAIN>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_USERNAME: <USER>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_PASSWORD: <PASSWORD>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_SERVICES: rabbit, my-config-server #this is so all stream applications bind to my-config-server
services:
- mysql
my-config-server11.19。配置调度
本节讨论如何配置 Spring Cloud Data Flow 以连接到PCF-Scheduler作为其代理来执行任务。
|
在遵循这些说明之前,请确保在您的 Cloud Foundry 空间中运行 PCF-Scheduler 服务的实例。要在您的空间中创建 PCF 调度程序(假设它在您的市场中),请从 CF CLI 执行以下命令 |
对于调度,您必须在您的环境中添加(或更新)以下环境变量:
-
spring.cloud.dataflow.features.schedules-enabled通过设置为Spring Cloud Data Flow 启用调度true。 -
通过将 PCF-Scheduler 服务名称添加到
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_SERVICES环境变量,将任务部署程序绑定到您的 PCF-Scheduler 实例。 -
通过设置
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_SCHEDULER_SCHEDULER_URL环境变量来建立 PCF 调度程序的 URL。
|
创建上述配置后,您必须创建任何需要调度的任务定义。 |
以下示例清单显示了已配置的两个环境属性(假设您有一个可用的 PCF-Scheduler 服务,名称为myscheduler):
---
applications:
- name: data-flow-server
host: data-flow-server
memory: 2G
disk_quota: 2G
instances: 1
path: {PATH TO SERVER UBER-JAR}
env:
SPRING_APPLICATION_NAME: data-flow-server
SPRING_CLOUD_SKIPPER_SERVER_ENABLE_LOCAL_PLATFORM: false
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_URL: <URL>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_ORG: <ORG>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SPACE: <SPACE>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_DOMAIN: <DOMAIN>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_USERNAME: <USER>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_PASSWORD: <PASSWORD>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_SERVICES: rabbit, myscheduler
SPRING_CLOUD_DATAFLOW_FEATURES_SCHEDULES_ENABLED: true
SPRING_CLOUD_SKIPPER_CLIENT_SERVER_URI: https://<skipper-host-name>/api
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_SCHEDULER_SCHEDULER_URL: https://scheduler.local.pcfdev.io
services:
- mysql其中具有以下格式:(例如,)。检查 _PCF环境中的实际地址。SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]SCHEDULER_SCHEDULER_URLscheduler.<Domain-Name>scheduler.local.pcfdev.io
| 跨多个平台启动和调度任务的详细示例,请参阅 dataflow.spring.io上的多平台支持任务部分。 |
12. 配置 - Kubernetes
本节介绍如何配置 Spring Cloud Data Flow 特性,例如部署者属性、任务以及使用哪个关系数据库。
12.1. 功能切换
数据流服务器提供了一组特定的功能,可以在启动时启用或禁用。这些功能包括所有生命周期操作、REST 端点(服务器和客户端实现,包括 Shell 和 UI):
-
流
-
任务
-
时间表
您可以通过在启动数据流服务器时设置以下布尔环境变量来启用或禁用这些功能:
-
SPRING_CLOUD_DATAFLOW_FEATURES_STREAMS_ENABLED -
SPRING_CLOUD_DATAFLOW_FEATURES_TASKS_ENABLED -
SPRING_CLOUD_DATAFLOW_FEATURES_SCHEDULES_ENABLED
默认情况下,所有功能都已启用。
/featuresREST 端点提供有关已启用和禁用的功能的信息。
12.2. 部署者属性
您可以使用Kubernetes 部署程序的以下配置属性来自定义 Streams 和 Tasks 的部署方式。使用 Data Flow shell 进行部署时,您可以使用语法deployer.<appName>.kubernetes.<deployerPropertyName>. 当在数据流服务器中配置Kubernetes 任务平台和在 Skipper 中配置 Kubernetes 平台以部署 Streams时,也会使用这些属性。
| 部署者属性名称 | 描述 | 默认值 |
|---|---|---|
命名空间 |
要使用的命名空间 |
环境变量 |
部署.nodeSelector |
|
<无> |
imagePullSecret |
访问私有注册表以提取图像的秘密。 |
<无> |
imagePullPolicy |
拉取图像时应用的图像拉取策略。有效选项是 |
如果不存在 |
livenessProbeDelay |
应用程序容器的 Kubernetes 活性检查应开始检查其健康状态时的延迟(以秒为单位)。 |
10 |
livenessProbePeriod |
执行应用程序容器的 Kubernetes 活性检查的周期(以秒为单位)。 |
60 |
livenessProbeTimeout |
应用程序容器的 Kubernetes 活性检查超时(以秒为单位)。如果运行状况检查的返回时间超过此值,则假定为“不可用”。 |
2 |
livenessProbePath |
应用程序容器必须响应以进行活性检查的路径。 |
<无> |
livenessProbePort |
应用程序容器必须响应以进行活动检查的端口。 |
<无> |
就绪探测延迟 |
应用程序容器的就绪检查应开始检查模块是否完全启动并运行时的延迟(以秒为单位)。 |
10 |
准备调查期 |
执行应用程序容器就绪检查的时间(以秒为单位)。 |
10 |
就绪探测超时 |
应用程序容器在就绪检查期间必须响应其健康状态的超时(以秒为单位)。 |
2 |
就绪探测路径 |
应用程序容器必须响应以进行就绪检查的路径。 |
<无> |
就绪探针端口 |
应用程序容器必须响应的端口以进行就绪检查。 |
<无> |
probeCredentialsSecret |
包含访问安全探测端点时要使用的凭据的密钥名称。 |
<无> |
限制.内存 |
内存限制,分配 Pod 所需的最大值,默认单位是兆字节,支持“M”和“G”后缀 |
<无> |
限制.cpu |
CPU 限制,分配 pod 所需的最大值 |
<无> |
请求.内存 |
内存请求,保证分配 pod 所需的值。 |
<无> |
请求.cpu |
CPU 请求,保证分配 pod 所需的值。 |
<无> |
statefulSet.volumeClaimTemplate.storageClassName |
有状态集的存储类的名称 |
<无> |
statefulSet.volumeClaimTemplate.storage |
存储量。默认单位是兆字节,支持“M”和“G”后缀 |
<无> |
环境变量 |
为任何已部署的应用程序容器设置的环境变量列表 |
<无> |
入口点样式 |
用于 Docker 映像的入口点样式。用于确定如何传入属性。可以是 |
|
创建负载均衡器 |
为为每个应用程序创建的服务创建一个“LoadBalancer”。这有助于将外部 IP 分配给应用程序。 |
错误的 |
服务注解 |
为每个应用程序创建的服务设置的服务注释。格式字符串 |
<无> |
pod注解 |
为每个部署创建的 pod 设置的 pod 注释。格式字符串 |
<无> |
工作注释 |
为 pod 或为作业创建的作业设置作业注释。格式字符串 |
<无> |
minutesToWaitForLoadBalancer |
在尝试删除服务之前等待负载平衡器可用的时间(以分钟为单位)。 |
5 |
maxTerminatedErrorRestarts |
由于错误或资源使用过多而失败的应用程序允许的最大重启次数。 |
2 |
maxCrashLoopBackOffRestarts |
CrashLoopBackOff 中的应用程序允许的最大重启次数。值为 |
|
卷装 |
以 YAML 格式表示的卷挂载。例如 |
<无> |
卷 |
Kubernetes 实例支持的卷以 YAML 格式指定。例如 |
<无> |
主机网络 |
部署的 hostNetwork 设置,请参阅kubernetes.io/docs/api-reference/v1/definitions/#_v1_podspec |
错误的 |
创建部署 |
使用“副本集”而不是“复制控制器”创建“部署”。 |
真的 |
创建工作 |
在启动任务时创建一个“作业”而不是仅仅一个“Pod”。 |
错误的 |
容器命令 |
使用提供的命令和参数覆盖默认入口点命令。 |
<无> |
容器端口 |
添加其他端口以在容器上公开。 |
<无> |
创建节点端口 |
要使用的显式端口 when |
<无> |
部署服务帐户名称 |
应用部署中使用的服务帐户名称。注意:用于应用程序部署的服务帐户名称派生自数据流服务器部署。 |
<无> |
部署标签 |
|
<无> |
bootMajor版本 |
要使用的 Spring Boot 主要版本。目前仅用于自动配置 Spring Boot 版本特定的探测路径。有效选项是 |
2 |
tolerations.key |
用于容忍的关键。 |
<无> |
容忍度.效果 |
耐受效应。有关有效选项,请参阅kubernetes.io/docs/concepts/configuration/taint-and-toleration。 |
<无> |
tolerations.operator |
容差运算符。有关有效选项,请参阅kubernetes.io/docs/concepts/configuration/taint-and-toleration/。 |
<无> |
tolerations.tolerationSeconds |
定义在添加污点后 pod 将保持绑定到节点的时间的秒数。 |
<无> |
容差值 |
要应用的容差值,与 |
<无> |
秘密参考 |
将整个数据内容加载到各个环境变量中的密钥名称。多个秘密可以用逗号分隔。 |
<无> |
secretKeyRefs.envVarName |
保存秘密数据的环境变量名称 |
<无> |
secretKeyRefs.secretName |
要访问的秘密名称 |
<无> |
secretKeyRefs.dataKey |
从中获取秘密数据的密钥名称 |
<无> |
configMapRefs |
将整个数据内容加载到各个环境变量中的 ConfigMap(s) 的名称。多个 ConfigMap 用逗号分隔。 |
<无> |
configMapKeyRefs.envVarName |
保存 ConfigMap 数据的环境变量名称 |
<无> |
configMapKeyRefs.configMapName |
要访问的 ConfigMap 名称 |
<无> |
configMapKeyRefs.dataKey |
获取 ConfigMap 数据的键名 |
<无> |
最大并发任务数 |
此平台实例允许的最大并发任务数。 |
20 |
podSecurityContext.runAsUser |
运行 pod 容器进程的数字用户 ID |
<无> |
podSecurityContext.fsGroup |
运行 pod 容器进程的数字组 ID |
<无> |
亲和力.nodeAffinity |
以 YAML 格式表示的节点亲和性。例如 |
<无> |
亲和力.podAffinity |
以 YAML 格式表示的 pod 亲和性。例如 |
<无> |
亲和力.podAntiAffinity |
以 YAML 格式表示的 pod 反亲和性。例如 |
<无> |
statefulSetInitContainerImageName |
用于 StatefulSet Init Container 的自定义图像名称 |
<无> |
初始化容器 |
一个以 YAML 格式表示的 Init Container,将应用于 pod。例如 |
<无> |
附加容器 |
以 YAML 格式表示的附加容器,以应用于 pod。例如 |
<无> |
12.3. 任务
数据流服务器负责部署任务。数据流启动的任务将其状态写入数据流服务器使用的同一数据库。对于作为 Spring Batch 作业的任务,作业和步骤执行数据也存储在此数据库中。与 Skipper 一样,任务可以启动到多个平台。当数据流在 Kubernetes 上运行时,必须定义一个任务平台。要配置以 Kubernetes 为目标的新平台帐户,spring.cloud.dataflow.task.platform.kubernetes请在文件的部分下提供一个条目,application.yaml以通过另一个 Spring Boot 支持的机制。在以下示例中,创建了两个名为dev和qa的 Kubernetes 平台帐户。memory和之类的键disk是Cloud Foundry Deployer Properties。
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
dev:
namespace: devNamespace
imagePullPolicy: Always
entryPointStyle: exec
limits:
cpu: 4
qa:
namespace: qaNamespace
imagePullPolicy: IfNotPresent
entryPointStyle: boot
limits:
memory: 2048m
通过将一个平台定义为default允许您跳过platformName在其他情况下需要使用它的地方。
|
启动任务时,使用任务启动选项传递平台帐户名称的值--platformName如果不传递 的值,将使用platformName该值。default
| 将一个任务部署到多个平台时,该任务的配置需要和Data Flow Server连接同一个数据库。 |
您可以配置 Kubernetes 上的数据流服务器以将任务部署到 Cloud Foundry 和 Kubernetes。有关更多信息,请参阅Cloud Foundry 任务平台配置部分。
跨多个平台启动和调度任务的详细示例,请参阅 dataflow.spring.io上的多平台支持任务部分。
12.4. 常规配置
Kubernetes 的 Spring Cloud Data Flow 服务器使用该spring-cloud-kubernetes模块来处理挂载在/etc/secrets. ConfigMaps 必须安装application.yaml在/configSpring Boot 处理的目录中。为避免访问 Kubernetes API 服务器,将SPRING_CLOUD_KUBERNETES_CONFIG_ENABLE_API和SPRING_CLOUD_KUBERNETES_SECRETS_ENABLE_API设置为false.
12.4.1. 使用 ConfigMap 和 Secret
以下示例显示了一种可能的配置,它启用 MySQL 并设置内存限制:
apiVersion: v1
kind: ConfigMap
metadata:
name: scdf-server
labels:
app: scdf-server
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
limits:
memory: 1024Mi
datasource:
url: jdbc:mysql://${MYSQL_SERVICE_HOST}:${MYSQL_SERVICE_PORT}/mysql
username: root
password: ${mysql-root-password}
driverClassName: org.mariadb.jdbc.Driver
testOnBorrow: true
validationQuery: "SELECT 1"前面的示例假设 MySQL 被部署mysql为服务名称。Kubernetes 将这些服务的主机和端口值发布为环境变量,我们可以在配置我们部署的应用程序时使用它们。
我们更喜欢在 Secrets 文件中提供 MySQL 连接密码,如以下示例所示:
apiVersion: v1
kind: Secret
metadata:
name: mysql
labels:
app: mysql
data:
mysql-root-password: eW91cnBhc3N3b3Jk密码是 base64 编码的值。
12.5。数据库配置
Spring Cloud Data Flow 为 H2、HSQLDB、MySQL、Oracle、PostgreSQL、DB2 和 SQL Server 提供模式。如果正确的数据库驱动程序和适当的凭据位于类路径中,则会在服务器启动时自动创建适当的模式。
MySQL 的 JDBC 驱动程序(通过 MariaDB 驱动程序)、HSQLDB、PostgreSQL 和嵌入式 H2 都是开箱即用的。如果您使用任何其他数据库,则需要将相应的 JDBC 驱动程序 jar 放在服务器的类路径中。
例如,如果您使用 MySQL 和 secrets 文件中的密码,您可以在 ConfigMap 中提供以下属性:
data:
application.yaml: |-
spring:
datasource:
url: jdbc:mysql://${MYSQL_SERVICE_HOST}:${MYSQL_SERVICE_PORT}/mysql
username: root
password: ${mysql-root-password}
driverClassName: org.mariadb.jdbc.Driver
url: jdbc:mysql://${MYSQL_SERVICE_HOST}:${MYSQL_SERVICE_PORT}/test
driverClassName: org.mariadb.jdbc.Driver对于 PostgreSQL,您可以使用以下配置:
data:
application.yaml: |-
spring:
datasource:
url: jdbc:postgresql://${PGSQL_SERVICE_HOST}:${PGSQL_SERVICE_PORT}/database
username: root
password: ${postgres-password}
driverClassName: org.postgresql.Driver对于 HSQLDB,您可以使用以下配置:
data:
application.yaml: |-
spring:
datasource:
url: jdbc:hsqldb:hsql://${HSQLDB_SERVICE_HOST}:${HSQLDB_SERVICE_PORT}/database
username: sa
driverClassName: org.hsqldb.jdbc.JDBCDriver以下来自 Deployment 的 YAML 片段是安装 ConfigMap 的示例,application.yaml在/configSpring Boot 将处理它的位置加上 Secret 安装在其中,由于环境变量设置为/etc/secrets,它将被 spring-cloud-kubernetes 库拾取。SPRING_CLOUD_KUBERNETES_SECRETS_PATHS/etc/secrets
...
containers:
- name: scdf-server
image: springcloud/spring-cloud-dataflow-server:2.5.0.BUILD-SNAPSHOT
imagePullPolicy: Always
volumeMounts:
- name: config
mountPath: /config
readOnly: true
- name: database
mountPath: /etc/secrets/database
readOnly: true
ports:
...
volumes:
- name: config
configMap:
name: scdf-server
items:
- key: application.yaml
path: application.yaml
- name: database
secret:
secretName: mysql您可以在spring-cloud-task存储库中找到特定数据库类型的迁移脚本。
12.6。监控和管理
我们建议使用该kubectl命令对流和任务进行故障排除。
您可以使用以下命令列出所有使用的工件和资源:
kubectl get all,cm,secrets,pvc您可以通过使用标签选择资源来列出特定应用程序或服务使用的所有资源。以下命令列出了mysql服务使用的所有资源:
kubectl get all -l app=mysql您可以通过发出以下命令来获取特定 pod 的日志:
kubectl logs pod <pod-name>如果 pod 不断重启,您可以添加-p选项以查看之前的日志,如下所示:
kubectl logs -p <pod-name>您还可以通过添加-f选项来跟踪或关注日志,如下所示:
kubectl logs -f <pod-name>一个有用的命令有助于解决问题,例如启动时出现致命错误的容器,是使用该describe命令,如以下示例所示:
kubectl describe pod ticktock-log-0-qnk7212.6.1. 检查服务器日志
您可以使用以下命令访问服务器日志:
kubectl get pod -l app=scdf=server
kubectl logs <scdf-server-pod-name>12.6.2. 流
流应用程序使用流名称后跟应用程序名称进行部署。对于处理器和接收器,还附加了一个实例索引。
要查看 Spring Cloud Data Flow 服务器部署的所有 Pod,可以指定role=spring-app标签,如下所示:
kubectl get pod -l role=spring-app要查看特定应用程序部署的详细信息,您可以使用以下命令:
kubectl describe pod <app-pod-name>要查看应用程序日志,可以使用以下命令:
kubectl logs <app-pod-name>如果您想跟踪日志,可以使用以下命令:
kubectl logs -f <app-pod-name>12.6.3. 任务
任务作为没有复制控制器的裸 pod 启动。任务完成后 Pod 仍然存在,这使您有机会查看日志。
要查看特定任务的所有 pod,请使用以下命令:
kubectl get pod -l task-name=<task-name>要查看任务日志,请使用以下命令:
kubectl logs <task-pod-name>您有两个选项可以删除已完成的 pod。一旦不再需要它们,您可以手动删除它们,或者您可以使用 Data Flow shelltask execution cleanup命令删除已完成的 pod 以执行任务。
要手动删除任务 pod,请使用以下命令:
kubectl delete pod <task-pod-name>要使用该task execution cleanup命令,您必须首先确定ID要执行的任务。为此,请使用task execution list命令,如以下示例(带输出)所示:
dataflow:>task execution list
╔═════════╤══╤════════════════════════════╤════════════════════════════╤═════════╗
║Task Name│ID│ Start Time │ End Time │Exit Code║
╠═════════╪══╪════════════════════════════╪════════════════════════════╪═════════╣
║task1 │1 │Fri May 05 18:12:05 EDT 2017│Fri May 05 18:12:05 EDT 2017│0 ║
╚═════════╧══╧════════════════════════════╧════════════════════════════╧═════════╝获得 ID 后,您可以发出命令来清理执行工件(已完成的 pod),如以下示例所示:
dataflow:>task execution cleanup --id 1
Request to clean up resources for task execution 1 has been submitted任务的数据库凭证
默认情况下,Spring Cloud Data Flow 在任务启动时将数据库凭据作为属性传递给 pod。如果使用exec或shell入口点样式,如果用户kubectl describe在任务的 pod 上执行操作,则可以查看数据库凭据。要将 Spring Cloud Data Flow 配置为使用 Kubernetes Secrets:将spring.cloud.dataflow.task.use.kubernetes.secrets.for.db.credentials属性设置为true. 如果使用 Spring Cloud Data Flow 提供的 yaml 文件,请更新 `src/kubernetes/server/server-deployment.yaml 以添加以下环境变量:
- name: SPRING_CLOUD_DATAFLOW_TASK_USE_KUBERNETES_SECRETS_FOR_DB_CREDENTIALS
value: 'true'如果从以前版本的 SCDF 升级,请务必验证server-config.yaml 中spring.datasource.username是否spring.datasource.password存在环境变量。secretKeyRefs如果没有,请按照以下示例添加它:
...
task:
platform:
kubernetes:
accounts:
default:
secretKeyRefs:
- envVarName: "spring.datasource.password"
secretName: mysql
dataKey: mysql-root-password
- envVarName: "spring.datasource.username"
secretName: mysql
dataKey: mysql-root-username
...还要验证相关的 secret(dataKey) 在 secrets 中是否也可用。SCDF 在此处为 MySql 提供了一个示例:src/kubernetes/mysql/mysql-svc.yaml.
| 默认情况下通过属性传递数据库凭据是为了保持向后兼容性。此功能将在未来版本中删除。 |
12.7。调度
本节介绍如何配置计划任务的自定义。Spring Cloud Data Flow Kubernetes Server 中默认启用任务调度。属性用于影响计划任务的设置,并且可以在全局或每个计划的基础上进行配置。
| 除非另有说明,否则按计划设置的属性始终优先于设置为服务器配置的属性。这种安排允许覆盖特定计划的全局服务器级别属性。 |
有关KubernetesSchedulerProperties支持的选项的更多信息,请参阅。
12.7.1. 入口点样式
入口点样式会影响应用程序属性如何传递到要部署的任务容器。目前支持三种样式:
-
exec:(默认)将所有应用程序属性作为命令行参数传递。 -
shell:将所有应用程序属性作为环境变量传递。 -
boot:创建一个名为的环境变量SPRING_APPLICATION_JSON,其中包含所有应用程序属性的 JSON 表示。
您可以按如下方式配置入口点样式:
deployer.kubernetes.entryPointStyle=<Entry Point Style>替换<Entry Point Style>为您想要的入口点样式。
您还可以在env部署 YAML 的容器部分中的服务器级别配置入口点样式,如以下示例所示:
env:
- name: SPRING_CLOUD_SCHEDULER_KUBERNETES_ENTRY_POINT_STYLE
value: entryPointStyle替换entryPointStyle为所需的入口点样式。
您应该选择exec或的入口点样式shell,以对应ENTRYPOINT于容器的Dockerfile. 有关execvs的更多信息和用例shell,请参阅 Docker 文档的ENTRYPOINT部分。
使用boot入口点样式对应于使用exec样式ENTRYPOINT。来自部署请求的命令行参数被传递给容器,并添加了映射到SPRING_APPLICATION_JSON环境变量中的应用程序属性,而不是命令行参数。
12.7.2. 环境变量
要影响给定应用程序的环境设置,您可以利用该spring.cloud.deployer.kubernetes.environmentVariables属性。例如,生产设置中的一个常见要求是影响 JVM 内存参数。您可以通过使用JAVA_TOOL_OPTIONS环境变量来实现这一点,如以下示例所示:
deployer.kubernetes.environmentVariables=JAVA_TOOL_OPTIONS=-Xmx1024m
在部署流应用程序或启动某些属性可能包含敏感信息的任务应用程序时,使用shell或boot作为entryPointStyle. 这是因为exec(默认)将所有属性转换为命令行参数,因此在某些环境中可能不安全。
|
此外,您可以在部署 YAML 的容器部分中的服务器级别配置环境变量env,如以下示例所示:
| 在服务器配置中并按计划指定环境变量时,将合并环境变量。这允许在服务器配置中设置通用环境变量,并且在特定计划级别更具体。 |
env:
- name: SPRING_CLOUD_SCHEDULER_KUBERNETES_ENVIRONMENT_VARIABLES
value: myVar=myVal替换myVar=myVal为您想要的环境变量。
12.7.3. 图像拉取策略
镜像拉取策略定义了何时应该将 Docker 镜像拉取到本地注册表。目前支持三种策略:
-
IfNotPresent:(默认)如果图像已经存在,则不要拉取图像。 -
Always:无论是否已经存在,始终拉取图像。 -
Never:永远不要拉图像。仅使用已存在的图像。
以下示例显示了如何单独配置容器:
deployer.kubernetes.imagePullPolicy=Always替换Always为您想要的图像拉取策略。
env您可以在部署 YAML 的容器部分中在服务器级别配置图像拉取策略,如以下示例所示:
env:
- name: SPRING_CLOUD_SCHEDULER_KUBERNETES_IMAGE_PULL_POLICY
value: Always替换Always为您想要的图像拉取策略。
12.7.4. 私有 Docker 注册表
可以通过配置 Secret 来拉取私有且需要身份验证的 Docker 镜像。首先,您必须在集群中创建一个 Secret。按照从私有注册表中提取图像指南创建秘密。
创建密钥后,使用该imagePullSecret属性设置要使用的密钥,如以下示例所示:
deployer.kubernetes.imagePullSecret=mysecret替换mysecret为您之前创建的密钥的名称。
您还可以在env部署 YAML 的容器部分中的服务器级别配置图像拉取密钥,如以下示例所示:
env:
- name: SPRING_CLOUD_SCHEDULER_KUBERNETES_IMAGE_PULL_SECRET
value: mysecret替换mysecret为您之前创建的密钥的名称。
12.7.5。命名空间
默认情况下,用于计划任务的命名空间是default. 该值可以在env部署 YAML 的容器部分的服务器级别配置中设置,如以下示例所示:
env:
- name: SPRING_CLOUD_SCHEDULER_KUBERNETES_NAMESPACE
value: mynamespace12.7.6。服务帐号
您可以通过属性为计划任务配置自定义服务帐户。可以使用现有服务帐户或创建新服务帐户。创建服务帐户的一种方法是使用kubectl,如以下示例所示:
$ kubectl create serviceaccount myserviceaccountname
serviceaccount "myserviceaccountname" created然后,您可以将服务帐户配置为按计划使用,如下所示:
deployer.kubernetes.taskServiceAccountName=myserviceaccountname替换myserviceaccountname为您的服务帐户名称。
您还可以在env部署 YAML 的容器部分中的服务器级别配置服务帐户名称,如以下示例所示:
env:
- name: SPRING_CLOUD_SCHEDULER_KUBERNETES_TASK_SERVICE_ACCOUNT_NAME
value: myserviceaccountname替换myserviceaccountname为要应用于所有部署的服务帐户名称。
有关计划任务的更多信息,请参阅计划任务。
12.8. 调试支持
通过Java Debug Wire Protocol (JDWP)支持调试 Spring Cloud Data Flow Kubernetes Server 和包含的组件(例如Spring Cloud Kubernetes Deployer ) 。本节概述了一种手动启用调试的方法,以及另一种使用 Spring Cloud Data Flow Server Kubernetes 提供的配置文件来“修补”正在运行的部署的方法。
| JDWP 本身不使用任何身份验证。本节假设在本地开发环境(例如 Minikube)上进行调试,因此不提供有关保护调试端口的指导。 |
12.8.1. 手动启用调试
要手动启用 JDWP,首先在下面编辑src/kubernetes/server/server-deployment.yaml并添加一个附加containerPort条目spec.template.spec.containers.ports,其值为5005. 此外,在下面添加JAVA_TOOL_OPTIONS环境变量spec.template.spec.containers.env,如下例所示:
spec:
...
template:
...
spec:
containers:
- name: scdf-server
...
ports:
...
- containerPort: 5005
env:
- name: JAVA_TOOL_OPTIONS
value: '-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005'
前面的示例使用端口 5005,但它可以是不与另一个端口冲突的任何数字。containerPort所选择的端口号对于添加的值和标志的address参数也必须相同JAVA_TOOL_OPTIONS -agentlib,如前面的示例所示。
|
您现在可以启动 Spring Cloud Data Flow Kubernetes Server。服务器启动后,您可以验证scdf-server部署上的配置更改,如以下示例(带有输出)所示:
kubectl describe deployment/scdf-server
...
...
Pod Template:
...
Containers:
scdf-server:
...
Ports: 80/TCP, 5005/TCP
...
Environment:
JAVA_TOOL_OPTIONS: -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005
...启动服务器并启用 JDWP 后,您需要配置对端口的访问。在本例中,我们使用 的port-forward子命令kubectl。以下示例(带有输出)显示了如何使用以下命令向调试目标公开本地端口port-forward:
$ kubectl get pod -l app=scdf-server
NAME READY STATUS RESTARTS AGE
scdf-server-5b7cfd86f7-d8mj4 1/1 Running 0 10m
$ kubectl port-forward scdf-server-5b7cfd86f7-d8mj4 5005:5005
Forwarding from 127.0.0.1:5005 -> 5005
Forwarding from [::1]:5005 -> 5005您现在可以通过将调试器指向127.0.0.1主机和5005端口来附加调试器。子命令一直运行直到停止(例如,port-forward通过按CTRL+c)。
您可以通过将更改还原为src/kubernetes/server/server-deployment.yaml. 恢复的更改将在 Spring Cloud Data Flow Kubernetes 服务器的下一次部署中获取。当每次部署服务器时都应默认启用调试时,手动向配置添加调试支持很有用。
12.8.2. 通过修补启用调试
与其手动更改server-deployment.yamlKubernetes 对象,不如就地“打补丁”。为方便起见,包含提供与手动方法相同配置的补丁文件。要通过修补启用调试,请使用以下命令:
kubectl patch deployment scdf-server -p "$(cat src/kubernetes/server/server-deployment-debug.yaml)"运行上述命令会自动添加containerPort属性和JAVA_TOOL_OPTIONS环境变量。以下示例(带有输出)显示了如何验证对scdf-server部署的更改:
$ kubectl describe deployment/scdf-server
...
...
Pod Template:
...
Containers:
scdf-server:
...
Ports: 5005/TCP, 80/TCP
...
Environment:
JAVA_TOOL_OPTIONS: -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005
...要启用对调试端口的访问,而不是使用 的port-forward子命令kubectl,您可以修补scdf-serverKubernetes 服务对象。您必须首先确保scdf-serverKubernetes 服务对象具有正确的配置。以下示例(带输出)显示了如何执行此操作:
kubectl describe service/scdf-server
Port: <unset> 80/TCP
TargetPort: 80/TCP
NodePort: <unset> 30784/TCP如果输出包含<unset>,则必须修补服务以为此端口添加名称。以下示例显示了如何执行此操作:
$ kubectl patch service scdf-server -p "$(cat src/kubernetes/server/server-svc.yaml)"
只有在添加调试功能之前已创建目标集群时,才应缺少端口名称。由于向scdf-serverKubernetes 服务对象添加了多个端口,因此每个端口都需要有自己的名称。
|
现在您可以添加调试端口,如以下示例所示:
kubectl patch service scdf-server -p "$(cat src/kubernetes/server/server-svc-debug.yaml)"以下示例(带输出)显示了如何验证映射:
$ kubectl describe service scdf-server
Name: scdf-server
...
...
Port: scdf-server-jdwp 5005/TCP
TargetPort: 5005/TCP
NodePort: scdf-server-jdwp 31339/TCP
...
...
Port: scdf-server 80/TCP
TargetPort: 80/TCP
NodePort: scdf-server 30883/TCP
...
...输出显示容器端口 5005 已映射到 31339 的 NodePort。以下示例(带输出)显示了如何获取 Minikube 节点的 IP 地址:
$ minikube ip
192.168.99.100使用此信息,您可以使用主机 192.168.99.100 和端口 31339 创建调试连接。
以下示例显示了如何禁用 JDWP:
$ kubectl rollout undo deployment/scdf-server
$ kubectl patch service scdf-server --type json -p='[{"op": "remove", "path": "/spec/ports/0"}]'Kubernetes 部署对象会回滚到修补之前的状态。然后使用从列表remove中删除端口 5005的操作修补 Kubernetes 服务对象。containerPorts
kubectl rollout undo强制 pod 重新启动。修补 Kubernetes 服务对象不会重新创建服务,并且到scdf-server部署的端口映射保持不变。
|
有关部署回滚的更多信息,请参阅回滚部署,包括使用 kubectl Patch 管理历史记录和就地更新 API 对象。
壳
本节介绍启动 shell 的选项以及与 shell 如何处理空格、引号和 SpEL 表达式解释相关的更高级功能。Stream DSL和Composed Task DSL的介绍性章节 是开始最常见的 shell 命令用法的好地方。
13. 外壳选项
该外壳基于Spring Shell项目构建。一些命令行选项来自 Spring Shell,还有一些特定于数据流。shell 采用以下命令行选项:
unix:>java -jar spring-cloud-dataflow-shell-2.9.4.jar --help
Data Flow Options:
--dataflow.uri= Address of the Data Flow Server [default: http://localhost:9393].
--dataflow.username= Username of the Data Flow Server [no default].
--dataflow.password= Password of the Data Flow Server [no default].
--dataflow.credentials-provider-command= Accept any SSL certificate (even self-signed) [default: no].
--dataflow.proxy.uri= Address of an optional proxy server to use [no default].
--dataflow.proxy.username= Username of the proxy server (if required by proxy server) [no default].
--dataflow.proxy.password= Password of the proxy server (if required by proxy server) [no default].
--spring.shell.historySize= Default size of the shell log file [default: 3000].
--spring.shell.commandFile= Data Flow Shell executes commands read from the file(s) and then exits.
--help This message. 您可以使用该spring.shell.commandFile选项指向包含所有 shell 命令的现有文件,以部署一个或多个相关的流和任务。还支持运行多个文件。它们应该作为逗号分隔的字符串传递:
--spring.shell.commandFile=file1.txt,file2.txt
此选项在创建一些脚本以帮助自动部署时很有用。
此外,以下 shell 命令有助于将复杂脚本模块化为多个独立文件:
dataflow:>script --file <YOUR_AWESOME_SCRIPT>
14. 列出可用的命令
在命令提示符下键入help会列出所有可用命令。大多数命令用于数据流功能,但少数是通用命令。以下清单显示了help命令的输出:
! - Allows execution of operating system (OS) commands
clear - Clears the console
cls - Clears the console
date - Displays the local date and time
exit - Exits the shell
http get - Make GET request to http endpoint
http post - POST data to http endpoint
quit - Exits the shell
system properties - Shows the shells properties {JB - restore the apostrophe}
version - Displays shell version添加命令名称以help显示有关如何调用命令的其他信息:
dataflow:>help stream create
Keyword: stream create
Description: Create a new stream definition
Keyword: ** default **
Keyword: name
Help: the name to give to the stream
Mandatory: true
Default if specified: '__NULL__'
Default if unspecified: '__NULL__'
Keyword: definition
Help: a stream definition, using the DSL (e.g. "http --port=9000 | hdfs")
Mandatory: true
Default if specified: '__NULL__'
Default if unspecified: '__NULL__'
Keyword: deploy
Help: whether to deploy the stream immediately
Mandatory: false
Default if specified: 'true'
Default if unspecified: 'false'15. 制表符补全
TAB您可以通过按前导后的键来完成shell中的shell命令选项--。例如,按TABafterstream create --会产生以下建议:
dataflow:>stream create --
stream create --definition stream create --name如果您键入--de然后按 Tab,则会--definition展开。
Tab 补全也可在流或组合任务 DSL 表达式中用于应用程序或任务属性。您还可以使用TAB在流 DSL 表达式中获取您可以使用的可用源、处理器或接收器的提示。
16. 空格和引用规则
仅当参数值包含空格或|字符时,才需要引用它们。以下示例将 SpEL 表达式(应用于它遇到的任何数据)传递给转换处理器:
transform --expression='new StringBuilder(payload).reverse()'如果参数值需要嵌入单引号,使用两个单引号,如下:
// Query is: Select * from /Customers where name='Smith'
scan --query='Select * from /Customers where name=''Smith'''16.1. 报价和转义
有一个基于 Spring Shell 的客户端与数据流服务器对话并负责解析DSL。反过来,应用程序可能具有依赖于嵌入式语言的应用程序属性,例如Spring 表达式语言。
Shell、Data Flow DSL 解析器和 SpEL 对它们如何处理引号以及语法转义如何工作都有规则。当组合在一起时,可能会出现混乱。本节解释了适用的规则,并提供了涉及所有三个组件时可能遇到的最复杂情况的示例。
|
它并不总是那么复杂
如果您不使用 Data Flow Shell(例如,如果您直接使用 REST API)或者如果应用程序属性不是 SpEL 表达式,则转义规则会更简单。 |
16.1.1. 壳牌规则
可以说,当涉及到引号时,最复杂的组件是 Shell。不过,规则可以很简单地列出:
-
shell 命令由键 (
--something) 和相应的值组成。但是,有一个特殊的无键映射,稍后将对其进行描述。 -
值通常不能包含空格,因为空格是命令的默认分隔符。
-
但是,可以通过用引号(单引号(
')或双"引号())将值括起来来添加空格。 -
deployment <stream-name> --properties " …"不应再次引用在部署属性中传递的值(例如)。 -
如果用引号括起来,则可以通过在其前面加上反斜杠 (
\) 来嵌入相同类型的文字引号。 -
其他转义可用,例如
\t,\n,\r和\funicode 转义形式\uxxxx。 -
无键映射以特殊方式处理,因此不需要引用来包含空格。
例如,shell 支持!执行本机 shell 命令的命令。!接受单个无键参数。这就是以下示例有效的原因:
dataflow:>! rm something这里的参数是整个rm something字符串,它按原样传递给底层 shell。
再举一个例子,以下命令是严格等价的,参数值为something(不带引号):
dataflow:>stream destroy something
dataflow:>stream destroy --name something
dataflow:>stream destroy "something"
dataflow:>stream destroy --name "something"16.1.2. 属性文件规则
从文件加载属性时,规则会放宽。
-
属性文件(Java 和 YAML)中使用的特殊字符需要转义。例如
\应该替换为\\,\tby\\t等等。 -
对于 Java 属性文件 (
--propertiesFile <FILE_PATH>.properties),属性值不应用引号引起来。即使它们包含空格,也不需要它。filter.expression=payload > 5 -
但是,对于 YAML 属性文件 (
--propertiesFile <FILE_PATH>.yaml),值需要用双引号括起来。app: filter: filter: expression: "payload > 5"
16.1.3. DSL 解析规则
在解析器级别(即在流或任务定义的主体内部),规则如下:
-
选项值通常被解析到第一个空格字符。
-
但是,它们可以由文字字符串组成,用单引号或双引号括起来。
-
要嵌入这样的引用,请使用所需类型的两个连续引用。
因此,--expression过滤器应用程序的选项值在以下示例中在语义上是等效的:
filter --expression=payload>5
filter --expression="payload>5"
filter --expression='payload>5'
filter --expression='payload > 5'可以说,最后一个更具可读性。由于周围的报价,这成为可能。实际的表达是payload > 5。
现在,假设我们要针对字符串消息进行测试。如果我们想将有效负载与 SpEL 文字字符串 进行比较"something",我们可以使用以下内容:
filter --expression=payload=='something' (1)
filter --expression='payload == ''something''' (2)
filter --expression='payload == "something"' (3)| 1 | 这是有效的,因为没有空格。但是,它不是很清晰。 |
| 2 | 这使用单引号来保护整个论点。因此,实际的单引号需要加倍。 |
| 3 | SpEL 可以识别带有单引号或双引号的字符串文字,因此最后一种方法可以说是最易读的。 |
请注意,前面的示例要在 shell 之外考虑(例如,当直接调用 REST API 时)。当在 shell 中输入时,很可能整个流定义本身就在双引号内,这需要被转义。整个例子就变成了下面这样:
dataflow:>stream create something --definition "http | filter --expression=payload='something' | log"
dataflow:>stream create something --definition "http | filter --expression='payload == ''something''' | log"
dataflow:>stream create something --definition "http | filter --expression='payload == \"something\"' | log"16.1.4. SpEL 语法和 SpEL 文字
最后一块拼图是关于 SpEL 表达式。许多应用程序接受将被解释为 SpEL 表达式的选项,并且如前所述,字符串文字也以特殊方式处理。规则如下:
-
文字可以用单引号或双引号括起来。
-
引号需要加倍才能嵌入文字引号。双引号内的单引号不需要特殊处理,反之亦然。
作为最后一个示例,假设您要使用转换处理器。这个处理器接受一个expression选项,它是一个 SpEL 表达式。它将根据传入消息进行评估,默认值为payload(转发消息有效负载不受影响)。
重要的是要理解以下语句是等效的:
transform --expression=payload
transform --expression='payload'但是,它们不同于以下(以及它们的变体):
transform --expression="'payload'"
transform --expression='''payload'''第一个系列评估为消息有效负载,而后面的示例评估为文字字符串payload.
16.1.5。把它们放在一起
作为最后一个完整的示例,考虑如何hello world通过在 Data Flow shell 的上下文中创建流来强制将所有消息转换为字符串文字 :
数据流:> 流创建一些东西 --definition "http | transform --expression='''hello world''' | log"(1) 数据流:> 流创建一些东西 --definition "http | transform --expression='\"hello world\"' | log"(2) 数据流:> 流创建一些东西 --definition "http | transform --expression=\"'hello world'\" | log"(2)
| 1 | 在第一行中,单引号围绕着字符串(在数据流解析器级别),但它们需要加倍,因为它们在字符串文字内(由等号后的第一个单引号开始)。 |
| 2 | 第二行和第三行分别使用单引号和双引号,在数据流解析器级别包含整个字符串。因此,可以在字符串中使用另一种引号。不过,整个事情都在--definitionshell 的参数中,它使用双引号。因此,双引号被转义(在 shell 级别)。 |
流
本节更详细地介绍如何创建 Streams,它是 Spring Cloud Stream应用程序的集合。它涵盖了创建和部署 Streams 等主题。
如果您刚刚开始使用 Spring Cloud Data Flow,您可能应该 在深入了解本节之前阅读入门指南。
17. 简介
Stream 是长期存在的Spring Cloud Stream应用程序的集合,它们通过消息传递中间件相互通信。基于文本的 DSL 定义了应用程序之间的配置和数据流。虽然为您提供了许多应用程序来实现常见用例,但您通常会创建自定义 Spring Cloud Stream 应用程序来实现自定义业务逻辑。
Stream 的一般生命周期是:
-
注册应用程序。
-
创建流定义。
-
部署流。
-
取消部署或销毁 Stream。
-
升级或回滚 Stream 中的应用程序。
为了部署 Streams,必须将 Data Flow Server 配置为将部署委托给 Spring Cloud 生态系统中名为Skipper的新服务器。
此外,您可以配置 Skipper 以将应用程序部署到一个或多个 Cloud Foundry 组织和空间、Kubernetes 集群上的一个或多个命名空间或本地计算机。在 Data Flow 中部署流时,您可以指定在部署时使用哪个平台。Skipper 还为 Data Flow 提供了对已部署的流执行更新的能力。可以通过多种方式更新流中的应用程序,但最常见的示例之一是使用新的自定义业务逻辑升级处理器应用程序,同时保留现有的源和接收器应用程序。
17.1. 流管道 DSL
流是通过使用受 Unix 启发的管道语法定义的。该语法使用竖线(称为“管道”)来连接多个命令。ls -l | grep key | lessUnix 中的命令获取ls -l进程的输出并将其通过管道传输到grep key进程的输入。的输出grep依次发送到less进程的输入。每个|符号将左侧命令的标准输出连接到右侧命令的标准输入。数据从左到右流过管道。
在 Data Flow 中,Unix 命令被Spring Cloud Stream应用程序取代,每个管道符号表示通过消息中间件(例如 RabbitMQ 或 Apache Kafka)连接应用程序的输入和输出。
每个 Spring Cloud Stream 应用程序都以一个简单的名称注册。注册过程指定可以从何处获取应用程序(例如,在 Maven 存储库或 Docker 注册表中)。您可以在本节中了解有关如何注册 Spring Cloud Stream 应用程序的更多信息。在 Data Flow 中,我们将 Spring Cloud Stream 应用程序分类为 Sources、Processor 或 Sinks。
作为一个简单的示例,考虑从 HTTP 源收集数据并写入文件接收器。使用 DSL,流描述为:
http | file
涉及某些处理的流将表示为:
http | filter | transform | file
可以使用 shell 的stream create命令创建流定义,如下例所示:
dataflow:> stream create --name httpIngest --definition "http | file"
Stream DSL 被传递给--definition命令选项。
流定义的部署是通过Shell的stream deploy命令完成的,如下:
dataflow:> stream deploy --name ticktock
入门部分向您展示如何启动服务器以及如何启动和使用 Spring Cloud Data Flow shell。
请注意,shell 调用数据流服务器的 REST API。有关直接向服务器发出 HTTP 请求的更多信息,请参阅REST API 指南。
命名流定义时,请记住流中的每个应用程序都将在平台上创建,名称格式为<stream name>-<app name>. 因此,生成的应用程序名称的总长度不能超过 58 个字符。
|
17.2. 流应用 DSL
您可以使用 Stream Application DSL 为每个 Spring Cloud Stream 应用程序定义自定义绑定属性。有关更多信息,请参阅微型站点的Stream Application DSL部分。
考虑下面的 Java 接口,它定义了一个输入方法和两个输出方法:
public interface Barista {
@Input
SubscribableChannel orders();
@Output
MessageChannel hotDrinks();
@Output
MessageChannel coldDrinks();
}进一步考虑以下 Java 接口,它是创建 Kafka Streams 应用程序的典型接口:
interface KStreamKTableBinding {
@Input
KStream<?, ?> inputStream();
@Input
KTable<?, ?> inputTable();
}在这些具有多个输入和输出绑定的情况下,数据流无法对从一个应用程序到另一个应用程序的数据流做出任何假设。因此,您需要设置绑定属性以“连接”应用程序。Stream Application DSL使用“双管道”而不是“管道符号”来指示数据流不应配置应用程序的绑定属性。认为||是“并行”的意思。以下示例显示了这样一个“并行”定义:
dataflow:> stream create --definition "orderGeneratorApp || baristaApp || hotDrinkDeliveryApp || coldDrinkDeliveryApp" --name myCafeStream
颠覆性变化!SCDF Local、Cloud Foundry 1.7.0 到 1.7.2 和 SCDF Kubernetes 1.7.0 到 1.7.1 的版本使用comma字符作为应用程序之间的分隔符。这导致了传统 Stream DSL 的重大变化。虽然并不理想,但人们认为更改分隔符是对现有用户影响最小的最佳解决方案。
|
此流有四个应用程序。
baristaApp有两个输出目的地hotDrinks和,分别coldDrinks由hotDrinkDeliveryApp和使用coldDrinkDeliveryApp。部署此流时,您需要设置绑定属性,以便baristaApp将热饮消息发送到hotDrinkDeliveryApp目的地,将冷饮消息发送到coldDrinkDeliveryApp目的地。下面的清单就是这样做的:
app.baristaApp.spring.cloud.stream.bindings.hotDrinks.destination=hotDrinksDest
app.baristaApp.spring.cloud.stream.bindings.coldDrinks.destination=coldDrinksDest
app.hotDrinkDeliveryApp.spring.cloud.stream.bindings.input.destination=hotDrinksDest
app.coldDrinkDeliveryApp.spring.cloud.stream.bindings.input.destination=coldDrinksDest如果要使用消费者组,则需要分别在生产者和消费者应用程序上设置 Spring Cloud Stream 应用程序属性,spring.cloud.stream.bindings.<channelName>.producer.requiredGroups和。spring.cloud.stream.bindings.<channelName>.group
Stream Application DSL 的另一个常见用例是部署一个 HTTP 网关应用程序,该应用程序向 Kafka 或 RabbitMQ 应用程序发送同步请求或回复消息。在这种情况下,HTTP 网关应用程序和 Kafka 或 RabbitMQ 应用程序都可以是不使用 Spring Cloud Stream 库的 Spring Integration 应用程序。
也可以使用 Stream 应用程序 DSL 仅部署单个应用程序。
17.3. 应用程序属性
每个应用程序都使用属性来自定义其行为。例如,http源模块公开了一个port设置,允许将数据摄取端口从默认值更改:
dataflow:> stream create --definition "http --port=8090 | log" --name myhttpstream此port属性实际上与标准 Spring Bootserver.port属性相同。数据流增加了使用速记形式port而不是server.port. 您还可以指定速记版本:
dataflow:> stream create --definition "http --server.port=8000 | log" --name myhttpstream这种速记行为在Stream Application Properties一节中有更多讨论。如果您已注册应用程序属性元数据,则可以在键入后在 shell 中使用制表符完成--来获取候选属性名称列表。
shell 为应用程序属性提供选项卡补全。app info --name <appName> --type <appType>shell 命令为所有受支持的属性提供附加文档。
支持的流<appType>可能性有:source、processor和sink。
|
18. 流生命周期
流的生命周期经历以下阶段:
Skipper是一个服务器,可让您发现 Spring Boot 应用程序并在多个云平台上管理它们的生命周期。
Skipper 中的应用程序捆绑为包含应用程序资源位置、应用程序属性和部署属性的包。您可以将 Skipper 包视为类似于工具中的包,例如apt-get或brew.
当 Data Flow 部署 Stream 时,它会生成一个包并将其上传到 Skipper,该包代表 Stream 中的应用程序。用于升级或回滚 Stream 中的应用程序的后续命令将传递给 Skipper。另外,Stream定义是从包逆向工程的,Stream的状态也委托给Skipper。
18.1. 注册一个流应用程序
您可以使用该app register命令注册版本化流应用程序。您必须提供唯一名称、应用程序类型和可解析为应用程序工件的 URI。对于类型,请指定source、processor或sink。版本是从 URI 解析的。这里有一些例子:
dataflow:>app register --name mysource --type source --uri maven://com.example:mysource:0.0.1
dataflow:>app register --name mysource --type source --uri maven://com.example:mysource:0.0.2
dataflow:>app register --name mysource --type source --uri maven://com.example:mysource:0.0.3
dataflow:>app list --id source:mysource
╔═══╤══════════════════╤═════════╤════╤════╗
║app│ source │processor│sink│task║
╠═══╪══════════════════╪═════════╪════╪════╣
║ │> mysource-0.0.1 <│ │ │ ║
║ │mysource-0.0.2 │ │ │ ║
║ │mysource-0.0.3 │ │ │ ║
╚═══╧══════════════════╧═════════╧════╧════╝
dataflow:>app register --name myprocessor --type processor --uri file:///Users/example/myprocessor-1.2.3.jar
dataflow:>app register --name mysink --type sink --uri https://example.com/mysink-2.0.1.jar应用程序 URI 应符合以下模式格式之一:
-
Maven架构:
maven://<groupId>:<artifactId>[:<extension>[:<classifier>]]:<version> -
HTTP 架构:
http://<web-path>/<artifactName>-<version>.jar -
文件架构:
file:///<local-path>/<artifactName>-<version>.jar -
码头工人架构:
docker:<docker-image-path>/<imageName>:<version>
URI<version>部分对于版本化的流应用程序是强制性的。Skipper 使用多版本流应用程序允许通过使用部署属性在运行时升级或回滚这些应用程序。
|
如果您想注册使用 RabbitMQ binder 构建的http和log
应用程序的快照版本,您可以执行以下操作:
dataflow:>app register --name http --type source --uri maven://org.springframework.cloud.stream.app:http-source-rabbit:1.2.1.BUILD-SNAPSHOT
dataflow:>app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.2.1.BUILD-SNAPSHOT如果您想一次注册多个应用程序,可以将它们存储在一个属性文件中,其中键的格式为<type>.<name>,值是 URI。
例如,要注册使用 RabbitMQ binder 构建的http和log
应用程序的快照版本,您可以在属性文件中包含以下内容(例如,stream-apps.properties):
source.http=maven://org.springframework.cloud.stream.app:http-source-rabbit:1.2.1.BUILD-SNAPSHOT
sink.log=maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.2.1.BUILD-SNAPSHOT然后,要批量导入应用程序,请使用app import命令并使用开关提供属性文件的位置--uri,如下所示:
dataflow:>app import --uri file:///<YOUR_FILE_LOCATION>/stream-apps.properties通过 using 注册应用程序与--type app注册 asource或相同。该类型的应用程序只能在Stream Application DSL中使用(在DSL中使用双管道而不是单管道)并指示Data Flow不要配置应用程序的Spring Cloud Stream绑定属性。使用注册的应用程序不必是 Spring Cloud Stream 应用程序。它可以是任何 Spring Boot 应用程序。有关使用此应用程序类型的更多信息,请参阅Stream Application DSL 介绍。processorsinkapp|||--type app
您可以注册相同应用程序的多个版本(例如,相同的名称和类型),但您只能将一个版本设置为默认值。默认版本用于部署 Streams。
首次注册应用程序时,将其标记为默认值。可以使用以下app default命令更改默认应用程序版本:
dataflow:>app default --id source:mysource --version 0.0.2
dataflow:>app list --id source:mysource
╔═══╤══════════════════╤═════════╤════╤════╗
║app│ source │processor│sink│task║
╠═══╪══════════════════╪═════════╪════╪════╣
║ │mysource-0.0.1 │ │ │ ║
║ │> mysource-0.0.2 <│ │ │ ║
║ │mysource-0.0.3 │ │ │ ║
╚═══╧══════════════════╧═════════╧════╧════╝该app list --id <type:name>命令列出给定流应用程序的所有版本。
该app unregister命令有一个可选--version参数来指定要注销的应用程序版本:
dataflow:>app unregister --name mysource --type source --version 0.0.1
dataflow:>app list --id source:mysource
╔═══╤══════════════════╤═════════╤════╤════╗
║app│ source │processor│sink│task║
╠═══╪══════════════════╪═════════╪════╪════╣
║ │> mysource-0.0.2 <│ │ │ ║
║ │mysource-0.0.3 │ │ │ ║
╚═══╧══════════════════╧═════════╧════╧════╝如果--version未指定,则默认版本未注册。
|
流中的所有应用程序都应为要部署的流设置默认版本。否则,在部署期间它们将被视为未注册的应用程序。使用 |
app default --id source:mysource --version 0.0.3
dataflow:>app list --id source:mysource
╔═══╤══════════════════╤═════════╤════╤════╗
║app│ source │processor│sink│task║
╠═══╪══════════════════╪═════════╪════╪════╣
║ │mysource-0.0.2 │ │ │ ║
║ │> mysource-0.0.3 <│ │ │ ║
╚═══╧══════════════════╧═════════╧════╧════╝这stream deploy需要设置默认应用程序版本。但是, stream updateandstream rollback命令可以使用所有(默认和非默认)注册的应用程序版本。
以下命令创建一个使用默认 mysource 版本 (0.0.3) 的流:
dataflow:>stream create foo --definition "mysource | log"然后我们可以将版本更新到 0.0.2:
dataflow:>stream update foo --properties version.mysource=0.0.2
只有预先注册的应用程序才能用于deploy、update或rollbackStream。
|
尝试更新mysource版本0.0.1(未注册)失败。
18.1.1. 注册支持的应用程序和任务
为方便起见,我们为所有开箱即用的流和任务或批处理应用程序启动器提供了带有应用程序 URI(适用于 Maven 和 Docker)的静态文件。您可以指向此文件并批量导入所有应用程序 URI。否则,如前所述,您可以单独注册它们或拥有自己的自定义属性文件,其中仅包含所需的应用程序 URI。但是,我们建议在自定义属性文件中包含所需应用程序 URI 的“集中”列表。
Spring Cloud Stream App Starters
下表包含dataflow.spring.io基于 Spring Cloud Stream 2.1.x 和 Spring Boot 2.1.x 的可用 Stream Application Starter 的链接:
| 工件类型 | 稳定发布 | 快照发布 |
|---|---|---|
RabbitMQ + Maven |
dataflow.spring.io/Einstein-BUILD-SNAPSHOT-stream-applications-rabbit-maven |
|
RabbitMQ + Docker |
dataflow.spring.io/Einstein-BUILD-SNAPSHOT-stream-applications-rabbit-docker |
|
阿帕奇卡夫卡 + Maven |
dataflow.spring.io/Einstein-BUILD-SNAPSHOT-stream-applications-kafka-maven |
|
阿帕奇卡夫卡 + 码头工人 |
dataflow.spring.io/Einstein-BUILD-SNAPSHOT-stream-applications-kafka-docker |
默认情况下,App Starter 执行器端点是安全的。您可以通过使用该属性部署流来禁用安全
app.*.spring.autoconfigure.exclude=org.springframework.boot.autoconfigure.security.servlet.SecurityAutoConfiguration性。在 Kubernetes 上,请参阅Liveness and readiness probes部分,了解如何为执行器端点配置安全性。
|
| 从 Spring Cloud Stream 2.1 GA 版本开始,我们现在与 Spring Cloud Function 编程模型具有强大的互操作性。在此基础上,借助 Einstein 发布系列,现在可以选择几个 Stream App Starter,并使用函数式编程模型将它们组合成一个应用程序。查看 “Spring Cloud Data Flow 中的组合函数支持”博客,通过示例了解更多关于开发人员和编排经验的信息。 |
Spring Cloud 任务应用程序启动器
下表包括基于 Spring Cloud Task 2.1.x 和 Spring Boot 2.1.x 的可用任务应用程序启动器:
| 工件类型 | 稳定发布 | 快照发布 |
|---|---|---|
Maven |
dataflow.spring.io/Elston-BUILD-SNAPSHOT-task-applications-maven |
|
码头工人 |
dataflow.spring.io/Elston-BUILD-SNAPSHOT-task-applications-docker |
您可以在Task App Starters 项目页面和相关参考文档中找到有关可用任务启动器的更多信息。有关可用流启动器的更多信息,请查看Stream App Starters 项目页面 和相关参考文档。
例如,如果您想批量注册使用 Kafka binder 构建的所有开箱即用的流应用程序,可以使用以下命令:
$ dataflow:>app import --uri https://dataflow.spring.io/kafka-maven-latest或者,您可以使用 Rabbit binder 注册所有流应用程序,如下所示:
$ dataflow:>app import --uri https://dataflow.spring.io/rabbitmq-maven-latest您还可以传递--local选项(true默认情况下)以指示是否应在 shell 进程本身内解析属性文件位置。如果应从数据流服务器进程解析位置,请指定--local false.
|
当您使用 但是请注意,一旦下载,应用程序可能会根据资源位置在数据流服务器上本地缓存。如果资源位置没有改变(即使实际的资源字节可能不同),也不会重新下载。 此外,如果流已经部署并使用某个版本的注册应用程序,那么(强制)重新注册不同的应用程序在再次部署流之前无效。 |
| 在某些情况下,资源是在服务器端解析的。在其他情况下,URI 被传递到运行时容器实例,并在其中进行解析。有关详细信息,请参阅每个数据流服务器的特定文档。 |
18.1.2. 创建自定义应用程序
虽然 Data Flow 包括源、处理器、接收器应用程序,但您可以扩展这些应用程序或编写自定义Spring Cloud Stream应用程序。
Spring Cloud Stream文档中详细介绍了使用Spring Initializr创建 Spring Cloud Stream 应用程序的过程。您可以在一个应用程序中包含多个活页夹。如果您这样做,请参阅[passing_producer_consumer_properties]中的说明以了解如何配置它们。
为了支持允许属性,在 Spring Cloud Data Flow 中运行的 Spring Cloud Stream 应用程序可以包含 Spring Bootconfiguration-processor作为可选依赖项,如下例所示:
<dependencies>
<!-- other dependencies -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
</dependencies>注意:确保spring-boot-maven-plugin包含在 POM 中。该插件是创建向 Spring Cloud Data Flow 注册的可执行 jar 所必需的。Spring Initialzr 在生成的 POM 中包含插件。
创建自定义应用程序后,您可以注册它,如注册流应用程序中所述。
18.2. 创建流
Spring Cloud Data Flow Server 公开了一个完整的 RESTful API 来管理流定义的生命周期,但最简单的使用方法是通过 Spring Cloud Data Flow shell。入门部分描述了如何启动 shell。
新流是在流定义的帮助下创建的。这些定义是从一个简单的 DSL 构建的。例如,考虑如果我们运行以下 shell 命令会发生什么:
dataflow:> stream create --definition "time | log" --name ticktockticktock这定义了一个基于 DSL 表达式命名的流time | log。DSL 使用“管道”符号 ( |) 将源连接到接收器。
该stream info命令显示有关流的有用信息,如以下示例中所示(及其输出):
dataflow:>stream info ticktock
╔═══════════╤═════════════════╤══════════╗
║Stream Name│Stream Definition│ Status ║
╠═══════════╪═════════════════╪══════════╣
║ticktock │time | log │undeployed║
╚═══════════╧═════════════════╧══════════╝18.2.1. 流应用程序属性
应用程序属性是与流中的每个应用程序关联的属性。部署应用程序时,应用程序属性通过命令行参数或环境变量应用于应用程序,具体取决于底层部署实现。
以下流可以在创建流时定义应用程序属性:
dataflow:> stream create --definition "time | log" --name ticktockshell 命令显示应用程序的app info --name <appName> --type <appType>公开应用程序属性。有关公开属性的更多信息,请参阅应用程序元数据。
以下清单显示了time应用程序的公开属性:
dataflow:> app info --name time --type source
╔══════════════════════════════╤══════════════════════════════╤══════════════════════════════╤══════════════════════════════╗
║ Option Name │ Description │ Default │ Type ║
╠══════════════════════════════╪══════════════════════════════╪══════════════════════════════╪══════════════════════════════╣
║trigger.time-unit │The TimeUnit to apply to delay│<none> │java.util.concurrent.TimeUnit ║
║ │values. │ │ ║
║trigger.fixed-delay │Fixed delay for periodic │1 │java.lang.Integer ║
║ │triggers. │ │ ║
║trigger.cron │Cron expression value for the │<none> │java.lang.String ║
║ │Cron Trigger. │ │ ║
║trigger.initial-delay │Initial delay for periodic │0 │java.lang.Integer ║
║ │triggers. │ │ ║
║trigger.max-messages │Maximum messages per poll, -1 │1 │java.lang.Long ║
║ │means infinity. │ │ ║
║trigger.date-format │Format for the date value. │<none> │java.lang.String ║
╚══════════════════════════════╧══════════════════════════════╧══════════════════════════════╧══════════════════════════════╝以下清单显示了log应用程序的公开属性:
dataflow:> app info --name log --type sink
╔══════════════════════════════╤══════════════════════════════╤══════════════════════════════╤══════════════════════════════╗
║ Option Name │ Description │ Default │ Type ║
╠══════════════════════════════╪══════════════════════════════╪══════════════════════════════╪══════════════════════════════╣
║log.name │The name of the logger to use.│<none> │java.lang.String ║
║log.level │The level at which to log │<none> │org.springframework.integratio║
║ │messages. │ │n.handler.LoggingHandler$Level║
║log.expression │A SpEL expression (against the│payload │java.lang.String ║
║ │incoming message) to evaluate │ │ ║
║ │as the logged message. │ │ ║
╚══════════════════════════════╧══════════════════════════════╧══════════════════════════════╧══════════════════════════════╝time您可以在创建时为和log应用程序指定应用程序属性stream,如下所示:
dataflow:> stream create --definition "time --fixed-delay=5 | log --level=WARN" --name ticktock请注意,在前面的示例中,为and应用程序定义的fixed-delayand属性是 shell 完成提供的“短格式”属性名称。这些“短格式”属性名称仅适用于公开的属性。在所有其他情况下,您应该只使用完全限定的属性名称。leveltimelog
18.2.2. 通用应用程序属性
除了通过 DSL 进行配置之外,Spring Cloud Data Flow 还提供了一种机制,可以为它启动的所有流式应用程序设置公共属性。这可以通过spring.cloud.dataflow.applicationProperties.stream在启动服务器时添加前缀为的属性来完成。这样做时,服务器会将所有属性(不带前缀)传递给它启动的实例。
例如,通过使用以下选项启动 Data Flow 服务器,可以将所有启动的应用程序配置为使用特定的 Kafka 代理:
--spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.kafka.binder.brokers=192.168.1.100:9092
--spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.kafka.binder.zkNodes=192.168.1.100:2181这样做会导致spring.cloud.stream.kafka.binder.brokers和spring.cloud.stream.kafka.binder.zkNodes属性传递给所有启动的应用程序。
使用此机制配置的属性的优先级低于流部署属性。如果在流部署时指定了具有相同键的属性(例如,
app.http.spring.cloud.stream.kafka.binder.brokers覆盖公共属性),则它们将被覆盖。
|
18.3. 部署流
本节介绍在 Spring Cloud Data Flow 服务器负责部署流时如何部署流。它涵盖了使用 Skipper 服务部署和升级 Streams。如何设置部署属性的描述适用于 Stream 部署的两种方法。
考虑ticktock流定义:
dataflow:> stream create --definition "time | log" --name ticktock要部署流,请使用以下 shell 命令:
dataflow:> stream deploy --name ticktocktime数据流服务器将应用程序的解析和部署委托给 Skipper log。
该stream info命令显示有关流的有用信息,包括部署属性:
dataflow:>stream info --name ticktock
╔═══════════╤═════════════════╤═════════╗
║Stream Name│Stream Definition│ Status ║
╠═══════════╪═════════════════╪═════════╣
║ticktock │time | log │deploying║
╚═══════════╧═════════════════╧═════════╝
Stream Deployment properties: {
"log" : {
"resource" : "maven://org.springframework.cloud.stream.app:log-sink-rabbit",
"spring.cloud.deployer.group" : "ticktock",
"version" : "2.0.1.RELEASE"
},
"time" : {
"resource" : "maven://org.springframework.cloud.stream.app:time-source-rabbit",
"spring.cloud.deployer.group" : "ticktock",
"version" : "2.0.1.RELEASE"
}
}该命令有一个重要的可选命令参数(称为--platformName)stream deploy。Skipper 可以配置为部署到多个平台。Skipper 预先配置了一个名为 的平台default,该平台将应用程序部署到运行 Skipper 的本地机器上。--platformName命令行参数的默认值为default. 如果您通常部署到一个平台,则在安装 Skipper 时,您可以覆盖该default平台的配置。否则,将 指定为命令platformName返回的值之一。stream platform-list
在前面的示例中,时间源每秒以消息的形式发送当前时间,日志接收器使用日志框架将其输出。您可以跟踪stdout日志(具有<instance>后缀)。日志文件位于数据流服务器的日志输出中显示的目录中,如以下清单所示:
$ tail -f /var/folders/wn/8jxm_tbd1vj28c8vj37n900m0000gn/T/spring-cloud-dataflow-912434582726479179/ticktock-1464788481708/ticktock.log/stdout_0.log
2016-06-01 09:45:11.250 INFO 79194 --- [ kafka-binder-] log.sink : 06/01/16 09:45:11
2016-06-01 09:45:12.250 INFO 79194 --- [ kafka-binder-] log.sink : 06/01/16 09:45:12
2016-06-01 09:45:13.251 INFO 79194 --- [ kafka-binder-] log.sink : 06/01/16 09:45:13您还可以通过在创建流时传递标志来一步创建和部署--deploy流,如下所示:
dataflow:> stream create --definition "time | log" --name ticktock --deploy但是,在实际用例中,一步创建和部署流并不常见。原因是当你使用stream deploy命令时,你可以传入定义如何将应用程序映射到平台上的属性(例如,要使用的容器的内存大小是多少,每个应用程序要运行的数量,以及是否启用数据分区功能)。属性还可以覆盖创建流时设置的应用程序属性。下一节将详细介绍此功能。
18.3.1. 部署属性
部署流时,您可以指定可以控制如何部署和配置应用程序的属性。有关详细信息,请参阅微型站点的部署属性部分。
18.4. 销毁流
您可以通过从 shell 发出stream destroy命令来删除流,如下所示:
dataflow:> stream destroy --name ticktock如果流已部署,则在删除流定义之前取消部署。
18.5。取消部署流
通常,您希望停止流但保留名称和定义以供将来使用。在这种情况下,您可以undeploy按名称流:
dataflow:> stream undeploy --name ticktock
dataflow:> stream deploy --name ticktock您可以deploy稍后发出命令以重新启动它:
dataflow:> stream deploy --name ticktock18.6。验证流
有时,流定义中包含的应用程序在其注册中包含无效的 URI。这可能是由于在应用程序注册时输入了无效的 URI,或者应用程序从要从中提取它的存储库中删除。要验证流中包含的所有应用程序是否可解析,用户可以使用以下validate命令:
dataflow:>stream validate ticktock
╔═══════════╤═════════════════╗
║Stream Name│Stream Definition║
╠═══════════╪═════════════════╣
║ticktock │time | log ║
╚═══════════╧═════════════════╝
ticktock is a valid stream.
╔═══════════╤═════════════════╗
║ App Name │Validation Status║
╠═══════════╪═════════════════╣
║source:time│valid ║
║sink:log │valid ║
╚═══════════╧═════════════════╝在前面的示例中,用户验证了他们的 ticktock 流。source:time和都sink:log有效。现在我们可以看到如果我们有一个带有无效 URI 的注册应用程序的流定义会发生什么:
dataflow:>stream validate bad-ticktock
╔════════════╤═════════════════╗
║Stream Name │Stream Definition║
╠════════════╪═════════════════╣
║bad-ticktock│bad-time | log ║
╚════════════╧═════════════════╝
bad-ticktock is an invalid stream.
╔═══════════════╤═════════════════╗
║ App Name │Validation Status║
╠═══════════════╪═════════════════╣
║source:bad-time│invalid ║
║sink:log │valid ║
╚═══════════════╧═════════════════╝在这种情况下,Spring Cloud Data Flow 声明流是无效的,因为source:bad-time有一个无效的 URI。
18.7. 更新流
要更新流,请使用stream update命令,该命令将--properties或--propertiesFile作为命令参数。Skipper 有一个重要的新顶级前缀:version. 以下命令部署http | log流(部署log时注册的版本为1.1.0.RELEASE):
dataflow:> stream create --name httptest --definition "http --server.port=9000 | log"
dataflow:> stream deploy --name httptest
dataflow:>stream info httptest
╔══════════════════════════════╤══════════════════════════════╤════════════════════════════╗
║ Name │ DSL │ Status ║
╠══════════════════════════════╪══════════════════════════════╪════════════════════════════╣
║httptest │http --server.port=9000 | log │deploying ║
╚══════════════════════════════╧══════════════════════════════╧════════════════════════════╝
Stream Deployment properties: {
"log" : {
"spring.cloud.deployer.indexed" : "true",
"spring.cloud.deployer.group" : "httptest",
"maven://org.springframework.cloud.stream.app:log-sink-rabbit" : "1.1.0.RELEASE"
},
"http" : {
"spring.cloud.deployer.group" : "httptest",
"maven://org.springframework.cloud.stream.app:http-source-rabbit" : "1.1.0.RELEASE"
}
}然后以下命令更新流以使用1.2.0.RELEASE日志应用程序的版本。在使用特定版本的应用程序更新流之前,我们需要确保应用程序已使用该版本注册:
dataflow:>app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.2.0.RELEASE
Successfully registered application 'sink:log'然后我们可以更新应用程序:
dataflow:>stream update --name httptest --properties version.log=1.2.0.RELEASE
您只能将预注册的应用程序版本用于deploy、update或rollback流。
|
要验证部署属性和更新的版本,我们可以使用stream info,如以下示例中所示(及其输出):
dataflow:>stream info httptest
╔══════════════════════════════╤══════════════════════════════╤════════════════════════════╗
║ Name │ DSL │ Status ║
╠══════════════════════════════╪══════════════════════════════╪════════════════════════════╣
║httptest │http --server.port=9000 | log │deploying ║
╚══════════════════════════════╧══════════════════════════════╧════════════════════════════╝
Stream Deployment properties: {
"log" : {
"spring.cloud.deployer.indexed" : "true",
"spring.cloud.deployer.count" : "1",
"spring.cloud.deployer.group" : "httptest",
"maven://org.springframework.cloud.stream.app:log-sink-rabbit" : "1.2.0.RELEASE"
},
"http" : {
"spring.cloud.deployer.group" : "httptest",
"maven://org.springframework.cloud.stream.app:http-source-rabbit" : "1.1.0.RELEASE"
}
}18.8. 强制更新流
升级流时,--force即使没有更改应用程序或部署属性,您也可以使用该选项部署当前部署的应用程序的新实例。当应用程序本身在启动时获取配置信息时需要此行为 - 例如,从 Spring Cloud Config Server。--app-names您可以使用该选项指定要强制升级的应用程序。如果您不指定任何应用程序名称,则所有应用程序都将被强制升级。您可以将--forceand--app-names选项与--propertiesor--propertiesFile选项一起指定。
18.9。流版本
Skipper 保留已部署的流的历史记录。更新流后,有第二个版本的流。stream history --name <name-of-stream>您可以使用以下命令查询版本的历史记录:
dataflow:>stream history --name httptest
╔═══════╤════════════════════════════╤════════╤════════════╤═══════════════╤════════════════╗
║Version│ Last updated │ Status │Package Name│Package Version│ Description ║
╠═══════╪════════════════════════════╪════════╪════════════╪═══════════════╪════════════════╣
║2 │Mon Nov 27 22:41:16 EST 2017│DEPLOYED│httptest │1.0.0 │Upgrade complete║
║1 │Mon Nov 27 22:40:41 EST 2017│DELETED │httptest │1.0.0 │Delete complete ║
╚═══════╧════════════════════════════╧════════╧════════════╧═══════════════╧════════════════╝18.10。流清单
在替换所有值后,Skipper 保留所有应用程序、它们的应用程序属性和部署属性的“清单”。这代表了部署到平台的最终状态。您可以使用以下命令查看任何版本的 Stream 的清单:
stream manifest --name <name-of-stream> --releaseVersion <optional-version>如果--releaseVersion未指定,则返回最后一个版本的清单。
以下示例显示了清单的使用:
dataflow:>stream manifest --name httptest使用该命令会产生以下输出:
# Source: log.yml
apiVersion: skipper.spring.io/v1
kind: SpringCloudDeployerApplication
metadata:
name: log
spec:
resource: maven://org.springframework.cloud.stream.app:log-sink-rabbit
version: 1.2.0.RELEASE
applicationProperties:
spring.cloud.dataflow.stream.app.label: log
spring.cloud.stream.bindings.input.group: httptest
spring.cloud.dataflow.stream.name: httptest
spring.cloud.dataflow.stream.app.type: sink
spring.cloud.stream.bindings.input.destination: httptest.http
deploymentProperties:
spring.cloud.deployer.indexed: true
spring.cloud.deployer.group: httptest
spring.cloud.deployer.count: 1
---
# Source: http.yml
apiVersion: skipper.spring.io/v1
kind: SpringCloudDeployerApplication
metadata:
name: http
spec:
resource: maven://org.springframework.cloud.stream.app:http-source-rabbit
version: 1.2.0.RELEASE
applicationProperties:
spring.cloud.dataflow.stream.app.label: http
spring.cloud.stream.bindings.output.producer.requiredGroups: httptest
server.port: 9000
spring.cloud.stream.bindings.output.destination: httptest.http
spring.cloud.dataflow.stream.name: httptest
spring.cloud.dataflow.stream.app.type: source
deploymentProperties:
spring.cloud.deployer.group: httptest大多数部署和应用程序属性由数据流设置,以使应用程序能够相互通信并发送带有标识标签的应用程序指标。
18.11。回滚流
stream rollback您可以使用以下命令回滚到流的先前版本:
dataflow:>stream rollback --name httptest可选的--releaseVersion命令参数添加流的版本。如果未指定,则回滚操作转到先前的流版本。
18.12。应用程序计数
应用程序计数是系统的动态属性,用于指定应用程序实例的数量。有关详细信息,请参阅微型网站的应用程序计数部分。
18.13。船长的升级策略
Skipper 有一个简单的“红/黑”升级策略。它使用与当前运行版本一样多的实例部署新版本的应用程序,并检查/health应用程序的端点。如果新应用程序的运行状况良好,则取消部署之前的应用程序。如果新应用程序的健康状况不佳,则取消部署所有新应用程序,并认为升级不成功。
升级策略不是滚动升级,因此,如果应用程序的五个实例正在运行,那么在晴天场景中,在取消部署旧版本之前,还有五个新应用程序也在运行。
19. 流 DSL
本节介绍Stream DSL 介绍中未涵盖的 Stream DSL 的其他功能。
19.1. 点按流
可以在流中的各个生产者端点创建 Tap。有关更多信息,请参阅微型网站的Tapping a Stream部分。
19.2. 在流中使用标签
当一个流由多个具有相同名称的应用程序组成时,它们必须使用标签进行限定。有关更多信息,请参阅微型网站的标签应用部分。
19.3. 命名目的地
您可以使用命名目标,而不是引用源或接收器应用程序。有关详细信息,请参阅微型网站的命名目的地部分。
19.4. 扇入和扇出
通过使用命名目标,您可以支持扇入和扇出用例。有关详细信息,请参阅微型网站的扇入和扇出部分。
20. 流式 Java DSL
您可以使用spring-cloud-dataflow-rest-client模块提供的基于 Java 的 DSL,而不是使用 shell 创建和部署流。有关更多信息,请参阅微型站点的Java DSL部分。
21. 具有多个 Binder 配置的流应用程序
在某些情况下,当需要连接到不同的消息中间件配置时,流可以将其应用程序绑定到多个 Spring Cloud 流绑定器。在这些情况下,您应该确保应用程序使用它们的活页夹配置进行了适当的配置。例如,支持 Kafka 和 Rabbit 绑定器的多绑定器转换器是以下流中的处理器:
http | multibindertransform --expression=payload.toUpperCase() | log
在前面的示例中,您将编写自己的multibindertransform应用程序。
|
在此流中,每个应用程序以下列方式连接到消息传递中间件:
-
HTTP 源将事件发送到 RabbitMQ (
rabbit1)。 -
Multi-Binder Transform 处理器从 RabbitMQ (
rabbit1) 接收事件并将处理后的事件发送到 Kafka (kafka1)。 -
日志接收器从 Kafka (
kafka1) 接收事件。
这里,rabbit1和kafka1是 Spring Cloud Stream 应用程序属性中给出的绑定器名称。基于此设置,应用程序在其类路径中具有以下具有适当配置的绑定器:
-
HTTP:兔子绑定器
-
转换:Kafka 和 Rabbit 绑定器
-
日志:卡夫卡活页夹
spring-cloud-stream binder可以在应用程序本身内设置配置属性。如果没有,它们可以在deployment部署流时通过属性传递:
dataflow:>stream create --definition "http | multibindertransform --expression=payload.toUpperCase() | log" --name mystream
dataflow:>stream deploy mystream --properties "app.http.spring.cloud.stream.bindings.output.binder=rabbit1,app.multibindertransform.spring.cloud.stream.bindings.input.binder=rabbit1,
app.multibindertransform.spring.cloud.stream.bindings.output.binder=kafka1,app.log.spring.cloud.stream.bindings.input.binder=kafka1"您可以通过部署属性指定它们来覆盖任何绑定器配置属性。
22. 功能组成
函数组合允许您将函数逻辑动态附加到现有事件流应用程序。有关详细信息,请参阅微型网站的功能组合部分。
23. 功能应用
24. 例子
本章包括以下示例:
您可以在“示例”一章中找到更多示例的链接。
24.1. 简单的流处理
作为一个简单处理步骤的示例,我们可以使用以下流定义将 HTTP 发布数据的负载转换为大写:
http | transform --expression=payload.toUpperCase() | log要创建此流,请在 shell 中输入以下命令:
dataflow:> stream create --definition "http --server.port=9000 | transform --expression=payload.toUpperCase() | log" --name mystream --deploy以下示例使用 shell 命令发布一些数据:
dataflow:> http post --target http://localhost:9000 --data "hello"前面的示例在日志中生成大写字母HELLO,如下所示:
2016-06-01 09:54:37.749 INFO 80083 --- [ kafka-binder-] log.sink : HELLO24.2. 有状态的流处理
为了演示数据分区功能,以下清单部署了一个使用 Kafka 作为绑定器的流:
dataflow:>stream create --name words --definition "http --server.port=9900 | splitter --expression=payload.split(' ') | log"
Created new stream 'words'
dataflow:>stream deploy words --properties "app.splitter.producer.partitionKeyExpression=payload,deployer.log.count=2"
Deployed stream 'words'
dataflow:>http post --target http://localhost:9900 --data "How much wood would a woodchuck chuck if a woodchuck could chuck wood"
> POST (text/plain;Charset=UTF-8) http://localhost:9900 How much wood would a woodchuck chuck if a woodchuck could chuck wood
> 202 ACCEPTED
dataflow:>runtime apps
╔════════════════════╤═══════════╤═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╗
║App Id / Instance Id│Unit Status│ No. of Instances / Attributes ║
╠════════════════════╪═══════════╪═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╣
║words.log-v1 │ deployed │ 2 ║
╟┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈╢
║ │ │ guid = 24166 ║
║ │ │ pid = 33097 ║
║ │ │ port = 24166 ║
║words.log-v1-0 │ deployed │ stderr = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461063/words.log-v1/stderr_0.log ║
║ │ │ stdout = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461063/words.log-v1/stdout_0.log ║
║ │ │ url = https://192.168.0.102:24166 ║
║ │ │working.dir = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461063/words.log-v1 ║
╟┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈╢
║ │ │ guid = 41269 ║
║ │ │ pid = 33098 ║
║ │ │ port = 41269 ║
║words.log-v1-1 │ deployed │ stderr = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461063/words.log-v1/stderr_1.log ║
║ │ │ stdout = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461063/words.log-v1/stdout_1.log ║
║ │ │ url = https://192.168.0.102:41269 ║
║ │ │working.dir = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461063/words.log-v1 ║
╟────────────────────┼───────────┼───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╢
║words.http-v1 │ deployed │ 1 ║
╟┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈╢
║ │ │ guid = 9900 ║
║ │ │ pid = 33094 ║
║ │ │ port = 9900 ║
║words.http-v1-0 │ deployed │ stderr = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461054/words.http-v1/stderr_0.log ║
║ │ │ stdout = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461054/words.http-v1/stdout_0.log ║
║ │ │ url = https://192.168.0.102:9900 ║
║ │ │working.dir = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461054/words.http-v1 ║
╟────────────────────┼───────────┼───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╢
║words.splitter-v1 │ deployed │ 1 ║
╟┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈╢
║ │ │ guid = 33963 ║
║ │ │ pid = 33093 ║
║ │ │ port = 33963 ║
║words.splitter-v1-0 │ deployed │ stderr = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803437542/words.splitter-v1/stderr_0.log║
║ │ │ stdout = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803437542/words.splitter-v1/stdout_0.log║
║ │ │ url = https://192.168.0.102:33963 ║
║ │ │working.dir = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803437542/words.splitter-v1 ║
╚════════════════════╧═══════════╧═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╝查看words.log-v1-0日志时,您应该看到以下内容:
2016-06-05 18:35:47.047 INFO 58638 --- [ kafka-binder-] log.sink : How
2016-06-05 18:35:47.066 INFO 58638 --- [ kafka-binder-] log.sink : chuck
2016-06-05 18:35:47.066 INFO 58638 --- [ kafka-binder-] log.sink : chuck查看words.log-v1-1日志时,您应该看到以下内容:
2016-06-05 18:35:47.047 INFO 58639 --- [ kafka-binder-] log.sink : much
2016-06-05 18:35:47.066 INFO 58639 --- [ kafka-binder-] log.sink : wood
2016-06-05 18:35:47.066 INFO 58639 --- [ kafka-binder-] log.sink : would
2016-06-05 18:35:47.066 INFO 58639 --- [ kafka-binder-] log.sink : a
2016-06-05 18:35:47.066 INFO 58639 --- [ kafka-binder-] log.sink : woodchuck
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : if
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : a
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : woodchuck
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : could
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : wood此示例表明,包含相同单词的有效负载拆分被路由到相同的应用程序实例。
24.3. 其他源和接收器应用程序类型
这个例子展示了一些更复杂的东西:将time源换成其他东西。另一个受支持的源类型是http,它接受通过 HTTP POST 请求摄取的数据。请注意,http源在与数据流服务器不同的端口(默认为 8080)上接受数据。默认情况下,端口是随机分配的。
要创建一个使用http源但仍使用相同接收log器的流,我们将简单流处理示例中的原始命令更改为以下内容:
dataflow:> stream create --definition "http | log" --name myhttpstream --deploy请注意,这一次,在我们实际发布一些数据(通过使用 shell 命令)之前,我们看不到任何其他输出。要查看源正在侦听的随机分配的端口http,请运行以下命令:
dataflow:>runtime apps
╔══════════════════════╤═══════════╤═════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╗
║ App Id / Instance Id │Unit Status│ No. of Instances / Attributes ║
╠══════════════════════╪═══════════╪═════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╣
║myhttpstream.log-v1 │ deploying │ 1 ║
╟┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈╢
║ │ │ guid = 39628 ║
║ │ │ pid = 34403 ║
║ │ │ port = 39628 ║
║myhttpstream.log-v1-0 │ deploying │ stderr = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/myhttpstream-1542803867070/myhttpstream.log-v1/stderr_0.log ║
║ │ │ stdout = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/myhttpstream-1542803867070/myhttpstream.log-v1/stdout_0.log ║
║ │ │ url = https://192.168.0.102:39628 ║
║ │ │working.dir = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/myhttpstream-1542803867070/myhttpstream.log-v1 ║
╟──────────────────────┼───────────┼─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╢
║myhttpstream.http-v1 │ deploying │ 1 ║
╟┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈╢
║ │ │ guid = 52143 ║
║ │ │ pid = 34401 ║
║ │ │ port = 52143 ║
║myhttpstream.http-v1-0│ deploying │ stderr = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/myhttpstream-1542803866800/myhttpstream.http-v1/stderr_0.log║
║ │ │ stdout = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/myhttpstream-1542803866800/myhttpstream.http-v1/stdout_0.log║
║ │ │ url = https://192.168.0.102:52143 ║
║ │ │working.dir = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/myhttpstream-1542803866800/myhttpstream.http-v1 ║
╚══════════════════════╧═══════════╧═════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╝您应该看到相应的http源具有一个url属性,该属性包含它正在侦听的主机和端口信息。您现在可以发布到该 url,如以下示例所示:
dataflow:> http post --target http://localhost:1234 --data "hello"
dataflow:> http post --target http://localhost:1234 --data "goodbye"然后流将数据从http源汇集到接收器实现的输出日志log,产生类似于以下内容的输出:
2016-06-01 09:50:22.121 INFO 79654 --- [ kafka-binder-] log.sink : hello
2016-06-01 09:50:26.810 INFO 79654 --- [ kafka-binder-] log.sink : goodbye我们还可以更改接收器的实现。您可以将输出通过管道传输到文件 ( file)、hadoop ( hdfs) 或任何其他可用的接收器应用程序。您还可以定义自己的应用程序。
流开发人员指南
流监控
任务
本节详细介绍如何在 Spring Cloud Data Flow 上编排Spring Cloud Task应用程序。
如果您刚刚开始使用 Spring Cloud Data Flow,您可能应该在深入了解本节之前阅读“ Local ”、“ Cloud Foundry ”或“ Kubernetes ”的入门指南。
25. 简介
任务应用程序是短暂的,这意味着它会故意停止运行,并且可以按需运行或安排在以后运行。一个用例可能是抓取网页并写入数据库。
Spring Cloud Task框架基于Spring Boot,增加了 Boot 应用程序记录短暂应用程序生命周期事件的能力,例如启动时间、结束时间和退出状态。该TaskExecution文档显示了哪些信息存储在数据库中。Spring Cloud Task 应用程序中代码执行的入口点通常是 BootCommandLineRunner接口的实现,如本例所示。
Spring Batch 项目可能是 Spring 开发人员编写短期应用程序时想到的。Spring Batch 提供了比 Spring Cloud Task 更丰富的功能集,在处理大量数据时推荐使用。一个用例可能是读取许多 CSV 文件,转换每一行数据,然后将转换后的每一行写入数据库。Spring Batch 提供了自己的数据库模式,其中包含关于 Spring Batch 作业执行的更丰富的信息集。Spring Cloud Task 与 Spring Batch 集成,因此,如果 Spring Cloud Task 应用程序定义了 Spring Batch Job,则在 Spring Cloud Task 和 Spring Cloud Batch 执行表之间创建链接。
在本地机器上运行数据流时,任务在单独的 JVM 中启动。在 Cloud Foundry 上运行时,使用Cloud Foundry 的任务功能启动任务。在 Kubernetes 上运行时,使用 aPod或Job资源启动任务。
26. 任务的生命周期
在深入了解创建任务的细节之前,您应该了解 Spring Cloud Data Flow 上下文中任务的典型生命周期:
26.1. 创建任务应用程序
虽然 Spring Cloud Task 确实提供了许多开箱即用的应用程序(在spring-cloud-task-app-starters),但大多数任务应用程序都需要自定义开发。要创建自定义任务应用程序:
-
使用Spring Initializer创建一个新项目,确保选择以下启动器:
-
Cloud Task: 这个依赖是spring-cloud-starter-task. -
JDBC: 这个依赖是spring-jdbc启动器。 -
选择您的数据库依赖项:输入数据流当前使用的数据库依赖项。例如:
H2。
-
-
在您的新项目中,创建一个新类作为您的主类,如下所示:
@EnableTask @SpringBootApplication public class MyTask { public static void main(String[] args) { SpringApplication.run(MyTask.class, args); } } -
使用此类,您需要在应用程序中实现一个或多个
CommandLineRunner或多个实现。ApplicationRunner您可以实现自己的,也可以使用 Spring Boot 提供的那些(例如,有一个用于运行批处理作业)。 -
使用 Spring Boot 将您的应用程序打包到一个 über jar 中是通过标准Spring Boot 约定完成的。可以如下所述注册和部署打包的应用程序。
26.1.1. 任务数据库配置
| 启动任务应用程序时,请确保 Spring Cloud Data Flow 使用的数据库驱动程序也是任务应用程序的依赖项。例如,如果您的 Spring Cloud Data Flow 设置为使用 Postgresql,请确保任务应用程序也具有 Postgresql 作为依赖项。 |
| 当您在外部(即从命令行)运行任务并且希望 Spring Cloud Data Flow 在其 UI 中显示 TaskExecutions 时,请确保它们之间共享公共数据源设置。默认情况下,Spring Cloud Task 使用本地 H2 实例,并将执行记录到 Spring Cloud Data Flow 使用的数据库中。 |
26.2. 注册任务应用程序
您可以使用 Spring Cloud Data Flow Shellapp register命令向 App Registry 注册 Task 应用程序。您必须提供一个唯一的名称和一个可以解析为应用程序工件的 URI。对于类型,请指定task。以下清单显示了三个示例:
dataflow:>app register --name task1 --type task --uri maven://com.example:mytask:1.0.2
dataflow:>app register --name task2 --type task --uri file:///Users/example/mytask-1.0.2.jar
dataflow:>app register --name task3 --type task --uri https://example.com/mytask-1.0.2.jar在提供带有maven方案的 URI 时,格式应符合以下要求:
maven://<groupId>:<artifactId>[:<extension>[:<classifier>]]:<version>如果您想一次注册多个应用程序,您可以将它们存储在一个属性文件中,其中键的格式为<type>.<name>,值是 URI。例如,以下清单将是一个有效的属性文件:
task.cat=file:///tmp/cat-1.2.1.BUILD-SNAPSHOT.jar
task.hat=file:///tmp/hat-1.2.1.BUILD-SNAPSHOT.jar然后您可以使用该app import命令并使用选项提供属性文件的位置--uri,如下所示:
app import --uri file:///tmp/task-apps.properties例如,如果您想在单个操作中注册所有随 Data Flow 一起提供的任务应用程序,您可以使用以下命令来完成:
dataflow:>app import --uri https://dataflow.spring.io/task-maven-latest您还可以传递--local选项(TRUE默认情况下)以指示是否应在 shell 进程本身内解析属性文件位置。如果应从数据流服务器进程解析位置,请指定--local false.
使用app register或app import时,如果任务应用程序已使用提供的名称和版本注册,则默认情况下不会覆盖它。如果您想用不同的uri或uri-metadata位置覆盖预先存在的任务应用程序,请包含该--force选项。
| 在某些情况下,资源是在服务器端解析的。在其他情况下,URI 被传递到运行时容器实例,并在其中进行解析。有关详细信息,请参阅每个数据流服务器的特定文档。 |
26.3. 创建任务定义
您可以通过提供定义名称以及适用于任务执行的属性,从任务应用程序创建任务定义。您可以通过 RESTful API 或 shell 创建任务定义。要使用 shell 创建任务定义,请使用
task create命令创建任务定义,如下例所示:
dataflow:>task create mytask --definition "timestamp --format=\"yyyy\""
Created new task 'mytask'您可以通过 RESTful API 或 shell 获取当前任务定义的列表。要使用 shell 获取任务定义列表,请使用task list命令。
26.3.1. 最大任务定义名称长度
任务定义名称的最大字符长度取决于平台。
| 有关资源命名的详细信息,请参阅平台文档。Local 平台将任务定义名称存储在最大大小为 255 的数据库列中。 |
| Kubernetes 裸豆荚 | Kubernetes 工作 | 云铸造 | 当地的 |
|---|---|---|---|
63 |
52 |
63 |
255 |
26.3.2. 自动创建任务定义
从 2.3.0 版开始,您可以将数据流服务器配置为自动创建任务定义,方法是设置spring.cloud.dataflow.task.autocreate-task-definitions为true. 这不是默认行为,而是为了方便而提供的。启用此属性后,任务启动请求可以将注册的任务应用程序名称指定为任务名称。如果任务应用程序已注册,则服务器会根据需要创建一个仅指定应用程序名称的基本任务定义。这消除了类似于以下的手动步骤:
dataflow:>task create mytask --definition "mytask"您仍然可以为每个任务启动请求指定命令行参数和部署属性。
26.4. 启动任务
可以通过 RESTful API 或 shell 启动临时任务。要通过 shell 启动临时任务,请使用task launch命令,如以下示例所示:
dataflow:>task launch mytask
Launched task 'mytask'启动任务时,您可以设置任何需要在启动任务时作为命令行参数传递给任务应用程序的属性,如下所示:
dataflow:>task launch mytask --arguments "--server.port=8080 --custom=value"| 参数需要作为空格分隔的值传递。 |
您可以通过使用该选项传递用于 aTaskLauncher本身的其他属性。--properties此选项的格式是以逗号分隔的属性字符串,前缀为app.<task definition name>.<property>. 属性作为应用程序属性传递TaskLauncher。由实现来选择如何将它们传递到实际的任务应用程序中。deployer如果该属性以而不是为前缀,则将其作为部署属性app传递给,其含义可能是特定于实现的。TaskLauncherTaskLauncher
dataflow:>task launch mytask --properties "deployer.timestamp.custom1=value1,app.timestamp.custom2=value2"26.4.1. 应用程序属性
每个应用程序都使用属性来自定义其行为。例如,timestamp任务format设置建立了不同于默认值的输出格式。
dataflow:> task create --definition "timestamp --format=\"yyyy\"" --name printTimeStamp此属性实际上与时间戳应用程序指定timestamp的属性相同。timestamp.format数据流增加了使用速记形式format而不是timestamp.format. 您还可以指定速记版本,如以下示例所示:
dataflow:> task create --definition "timestamp --timestamp.format=\"yyyy\"" --name printTimeStamp这种速记行为在Stream Application Properties一节中有更多讨论。如果您已注册应用程序属性元数据,则可以在键入后在 shell 中使用制表符完成--来获取候选属性名称列表。
shell 为应用程序属性提供选项卡补全。app info --name <appName> --type <appType>shell 命令为所有受支持的属性提供附加文档。支持的任务<appType>是task。
在 Kubernetes 上重启 Spring Batch Jobs 时,必须使用shell或的入口点boot。
|
Kubernetes 上具有敏感信息的应用程序属性
在启动某些属性可能包含敏感信息的任务应用程序时,使用shell或boot作为entryPointStyle. 这是因为exec(默认)将所有属性转换为命令行参数,因此在某些环境中可能不安全。
26.4.2. 常见的应用程序属性
除了通过 DSL 进行配置之外,Spring Cloud Data Flow 还提供了一种机制来设置由它启动的所有任务应用程序共有的属性。您可以通过spring.cloud.dataflow.applicationProperties.task在启动服务器时添加前缀为的属性来做到这一点。然后,服务器将所有属性(不带前缀)传递给它启动的实例。
例如,您可以通过使用以下选项启动数据流服务器来配置所有已启动的应用程序以使用prop1和属性:prop2
--spring.cloud.dataflow.applicationProperties.task.prop1=value1
--spring.cloud.dataflow.applicationProperties.task.prop2=value2这会导致prop1=value1和prop2=value2属性传递给所有启动的应用程序。
使用此机制配置的属性的优先级低于任务部署属性。如果在任务启动时指定了具有相同键的属性(例如,app.trigger.prop2
覆盖公共属性),它们将被覆盖。
|
26.5。限制并发任务启动的数量
Spring Cloud Data Flow 允许用户限制每个已配置平台的最大并发运行任务数,以防止 IaaS 或硬件资源饱和。默认情况下,20所有受支持平台的限制都设置为。如果平台实例上同时运行的任务数大于或等于限制,则下一个任务启动请求失败,并通过RESTful API、Shell或UI返回错误信息。您可以通过设置相应的部署者属性为平台实例配置此限制spring.cloud.dataflow.task.platform.<platform-type>.accounts[<account-name>].maximumConcurrentTasks,其中<account-name>是已配置平台帐户的名称(default如果没有明确配置帐户)。<platform-type>指的是当前支持的部署者之一:local或kubernetes. 为了cloudfoundry,属性为spring.cloud.dataflow.task.platform.<platform-type>.accounts[<account-name>].deployment.maximumConcurrentTasks。(不同的是deployment已经添加到路径中)。
如果可能,每个受支持平台的TaskLauncher实现通过查询底层平台的运行时状态来确定当前正在运行的任务的数量。识别方法task因平台而异。例如,在本地主机上启动任务使用LocalTaskLauncher.LocalTaskLauncher为每个启动请求运行一个进程并在内存中跟踪这些进程。在这种情况下,我们不查询底层操作系统,因为以这种方式识别任务是不切实际的。对于 Cloud Foundry,任务是其部署模型支持的核心概念。所有任务的状态)可直接通过 API 获得。这意味着帐户的组织和空间中的每个正在运行的任务容器都包含在运行执行计数中,无论它是使用 Spring Cloud Data Flow 启动还是CloudFoundryTaskLauncher直接调用。对于 Kubernetes,通过KubernetesTaskLauncher,如果成功,会产生一个正在运行的 pod,我们预计它最终会完成或失败。在这种环境中,通常没有简单的方法来识别对应于任务的 pod。因此,我们只计算由KubernetesTaskLauncher. 由于任务启动器task-name在 pod 的元数据中提供了标签,因此我们通过该标签的存在来过滤所有正在运行的 pod。
26.6。审查任务执行
启动任务后,任务的状态将存储在关系数据库中。该州包括:
-
任务名称
-
开始时间
-
时间结束
-
退出代码
-
退出消息
-
上次更新时间
-
参数
您可以通过 RESTful API 或 shell 检查任务执行的状态。要通过 shell 显示最新的任务执行,请使用task execution list命令。
要获取仅一个任务定义的任务执行列表,请添加--name任务定义名称 - 例如,task execution list --name foo. 要检索任务执行的完整详细信息,请使用task execution status带有任务执行 ID 的命令,例如task execution status --id 549.
26.7. 销毁任务定义
销毁任务定义会从定义存储库中删除该定义。这可以通过 RESTful API 或 shell 来完成。要通过 shell 销毁任务,请使用task destroy命令,如下例所示:
dataflow:>task destroy mytask
Destroyed task 'mytask'该task destroy命令还有一个选项来cleanup执行被销毁的任务,如以下示例所示:
dataflow:>task destroy mytask --cleanup
Destroyed task 'mytask'默认情况下,该cleanup选项设置为false(即默认情况下,任务销毁时不会清理任务执行)。
要通过 shell 销毁所有任务,请使用task all destroy如下示例所示的命令:
dataflow:>task all destroy
Really destroy all tasks? [y, n]: y
All tasks destroyed如果需要,您可以使用强制开关:
dataflow:>task all destroy --force
All tasks destroyed先前为定义启动的任务的任务执行信息保留在任务存储库中。
| 这不会停止此定义的任何当前正在运行的任务。相反,它会从数据库中删除任务定义。 |
|
+ . 使用 |
26.8. 验证任务
有时,任务定义中包含的应用程序在其注册中具有无效的 URI。这可能是由于在应用程序注册时输入了无效的 URI,或者应用程序从要从中提取它的存储库中删除。要验证任务中包含的所有应用程序是否可解析,请使用以下validate命令:
dataflow:>task validate time-stamp
╔══════════╤═══════════════╗
║Task Name │Task Definition║
╠══════════╪═══════════════╣
║time-stamp│timestamp ║
╚══════════╧═══════════════╝
time-stamp is a valid task.
╔═══════════════╤═════════════════╗
║ App Name │Validation Status║
╠═══════════════╪═════════════════╣
║task:timestamp │valid ║
╚═══════════════╧═════════════════╝在前面的示例中,用户验证了他们的时间戳任务。task:timestamp申请有效。现在我们可以看到如果我们有一个流定义,其中一个注册的应用程序有一个无效的 URI:
dataflow:>task validate bad-timestamp
╔═════════════╤═══════════════╗
║ Task Name │Task Definition║
╠═════════════╪═══════════════╣
║bad-timestamp│badtimestamp ║
╚═════════════╧═══════════════╝
bad-timestamp is an invalid task.
╔══════════════════╤═════════════════╗
║ App Name │Validation Status║
╠══════════════════╪═════════════════╣
║task:badtimestamp │invalid ║
╚══════════════════╧═════════════════╝在这种情况下,Spring Cloud Data Flow 声明该任务无效,因为task:badtimestamp它的 URI 无效。
26.9。停止任务执行
在某些情况下,在平台上运行的任务可能不会因为平台或应用程序业务逻辑本身的问题而停止。对于这种情况,Spring Cloud Data Flow 提供了向平台发送请求以结束任务的能力。为此,请task execution stop为给定的一组任务执行提交一个,如下所示:
task execution stop --ids 5
Request to stop the task execution with id(s): 5 has been submitted使用前面的命令,停止执行的触发器id=5被提交给底层部署器实现。因此,该操作会停止该任务。当我们查看任务执行的结果时,我们看到任务执行以 0 退出代码完成:
dataflow:>task execution list
╔══════════╤══╤════════════════════════════╤════════════════════════════╤═════════╗
║Task Name │ID│ Start Time │ End Time │Exit Code║
╠══════════╪══╪════════════════════════════╪════════════════════════════╪═════════╣
║batch-demo│5 │Mon Jul 15 13:58:41 EDT 2019│Mon Jul 15 13:58:55 EDT 2019│0 ║
║timestamp │1 │Mon Jul 15 09:26:41 EDT 2019│Mon Jul 15 09:26:41 EDT 2019│0 ║
╚══════════╧══╧════════════════════════════╧════════════════════════════╧═════════╝如果您为具有与其关联的子任务执行的任务执行提交停止,例如组合任务,则会为每个子任务执行发送停止请求。
停止具有正在运行的 Spring Batch 作业的任务执行时,该作业的批处理状态为STARTED. 当请求停止时,每个受支持的平台都会向任务应用程序发送一个 SIG-INT。这允许 Spring Cloud Task 捕获应用程序的状态。但是,Spring Batch 不处理 SIG-INT,因此作业会停止但仍处于 STARTED 状态。
|
| 在启动远程分区 Spring Batch Task 应用程序时,Spring Cloud Data Flow 支持直接为 Cloud Foundry 和 Kubernetes 平台停止工作分区任务。本地平台不支持停止 worker 分区任务。 |
26.9.1。停止在 Spring Cloud Data Flow 之外启动的任务执行
您可能希望停止在 Spring Cloud Data Flow 之外启动的任务。这方面的一个例子是远程批处理分区应用程序启动的工作应用程序。在这种情况下,远程批处理分区应用程序存储external-execution-id每个工作应用程序的数据。但是,不存储平台信息。所以当 Spring Cloud Data Flow 不得不停止一个远程批量分区应用程序及其工作应用程序时,需要指定平台名称,如下所示:
dataflow:>task execution stop --ids 1 --platform myplatform
Request to stop the task execution with id(s): 1 for platform myplatform has been submitted27. 订阅任务和批处理事件
您还可以在任务启动时点击各种任务和批处理事件。如果启用任务以生成任务或批处理事件(具有 的附加依赖项spring-cloud-task-stream,在 Kafka 作为活页夹的情况下spring-cloud-stream-binder-kafka,这些事件将在任务生命周期中发布。默认情况下,代理上发布的事件(Rabbit、Kafka 等)的目标名称是事件名称本身(例如:task-events、、job-execution-events等)。
dataflow:>task create myTask --definition "myBatchJob"
dataflow:>stream create task-event-subscriber1 --definition ":task-events > log" --deploy
dataflow:>task launch myTask您可以通过在启动任务时指定显式名称来控制这些事件的目标名称,如下所示:
dataflow:>stream create task-event-subscriber2 --definition ":myTaskEvents > log" --deploy
dataflow:>task launch myTask --properties "app.myBatchJob.spring.cloud.stream.bindings.task-events.destination=myTaskEvents"下表列出了代理上的默认任务和批处理事件以及目标名称:
事件 |
目的地 |
任务事件 |
|
作业执行事件 |
|
步骤执行事件 |
|
项目读取事件 |
|
项目流程事件 |
|
项目写入事件 |
|
跳过事件 |
|
28. 组合任务
Spring Cloud Data Flow 允许您创建有向图,其中图的每个节点都是一个任务应用程序。这是通过将 DSL 用于组合任务来完成的。您可以通过 RESTful API、Spring Cloud Data Flow Shell 或 Spring Cloud Data Flow UI 创建组合任务。
28.1. 组合任务运行器
组合任务通过称为组合任务运行器的任务应用程序运行。Spring Cloud Data Flow 服务器在启动组合任务时会自动部署组合任务运行器。
28.1.1. 配置组合任务运行器
组合任务运行器应用程序具有dataflow-server-uri用于验证和启动子任务的属性。这默认为localhost:9393. 如果您运行分布式 Spring Cloud Data Flow 服务器,就像您在 Cloud Foundry 或 Kubernetes 上部署服务器一样,您需要提供可用于访问服务器的 URI。您可以通过dataflow-server-uri在启动组合任务时设置组合任务运行器应用程序的spring.cloud.dataflow.server.uri属性或在启动时设置 Spring Cloud Data Flow 服务器的属性来提供此功能。对于后一种情况,dataflow-server-uri组合任务运行器应用程序属性会在启动组合任务时自动设置。
配置选项
该ComposedTaskRunner任务具有以下选项:
-
composed-task-arguments用于每个任务的命令行参数。(字符串,默认值:<none>)。 -
increment-instance-enabledComposedTaskRunner允许在不更改参数的情况下再次运行 单个实例,方法是run.id在上一次执行的基础上添加一个递增的作业参数。(布尔值,默认值:)true。ComposedTaskRunner 是使用Spring Batch构建的。因此,一旦成功执行,批处理作业就被认为是完成的。ComposedTaskRunner要多次启动相同的定义,您必须为每次启动设置increment-instance-enabled或uuid-instance-enabled属性true或更改定义的参数。使用此选项时,必须将其应用于所需应用程序的所有任务启动,包括首次启动。 -
uuid-instance-enabled通过将 UUID 添加到作业参数,允许在ComposedTaskRunner不更改参数的情况下再次运行 单个实例。ctr.id(布尔值,默认值:)false。ComposedTaskRunner 是使用Spring Batch构建的。因此,一旦成功执行,批处理作业就被认为是完成的。ComposedTaskRunner要多次启动相同的定义,您必须为每次启动设置increment-instance-enabled或uuid-instance-enabled属性true或更改定义的参数。使用此选项时,必须将其应用于所需应用程序的所有任务启动,包括首次启动。此选项设置为 true 时将覆盖 的值increment-instance-id。将此选项设置为true同时运行同一组合任务定义的多个实例时。 -
interval-time-between-checksComposedTaskRunner在检查数据库以查看任务是否已完成之间等待 的时间量(以毫秒为单位) 。(整数,默认值:)10000。ComposedTaskRunner使用数据存储来确定每个子任务的状态。此间隔指示ComposedTaskRunner它应该多久检查一次其子任务的状态。 -
transaction-isolation-level为 Composed Task Runner 建立事务隔离级别。可以在此处找到可用事务隔离级别的列表。默认为ISOLATION_REPEATABLE_READ。 -
max-wait-time在组合任务执行失败之前单个步骤可以运行的最长时间(以毫秒为单位)(整数,默认值:0)。确定在 CTR 以失败结束之前允许每个子任务运行的最长时间。默认值0表示没有超时。 -
split-thread-allow-core-thread-timeout指定是否允许拆分核心线程超时。(布尔值,默认值false:)设置控制核心线程是否可以超时并在保持活动时间内没有任务到达时终止的策略,如果需要,当新任务到达时被替换。 -
split-thread-core-pool-size拆分的核心池大小。(整数,默认值:)1拆分中包含的每个子任务都需要一个线程才能执行。因此,例如,诸如<AAA || BBB || CCC> && <DDD || EEE>需要 asplit-thread-core-pool-size的定义3。这是因为最大的拆分包含三个子任务。计数2意味着这将并行运行AAA,BBB但 CCC 会等到其中一个AAA或BBB完成才能运行。然后将DDD并行EEE运行。 -
split-thread-keep-alive-seconds斯普利特的线程保持活动秒数。(整数,默认值:)60如果池当前有多个corePoolSize线程,如果多余的线程空闲超过keepAliveTime. -
split-thread-max-pool-size拆分的最大池大小。(整数,默认值:)Integer.MAX_VALUE。建立线程池允许的最大线程数。 -
拆分线程队列 容量的拆分容量
BlockingQueue。(整数,默认值Integer.MAX_VALUE:)-
corePoolSize如果运行的线程数少于此,则Executor总是更喜欢添加新线程而不是排队。 -
如果
corePoolSize或更多线程正在运行,则Executor总是更喜欢排队请求而不是添加新线程。 -
如果请求无法排队,则创建一个新线程,除非超过
maximumPoolSize. 在这种情况下,任务被拒绝。
-
-
split-thread-wait-for-tasks-to-complete-on-shutdown是否在关机时等待计划任务完成,不中断正在运行的任务并运行队列中的所有任务。(布尔值,默认值false:) -
dataflow-server-uri接收任务启动请求的数据流服务器的 URI。(字符串,默认值localhost:9393:) -
dataflow-server-username接收任务启动请求的数据流服务器的可选用户名。用于使用基本身份验证访问数据流服务器。如果dataflow-server-access-token已设置,则不使用。 -
dataflow-server-password接收任务启动请求的数据流服务器的可选密码。用于使用基本身份验证访问数据流服务器。如果dataflow-server-access-token已设置,则不使用。 -
dataflow-server-access-token此属性设置可选的 OAuth2 访问令牌。通常,该值是使用当前登录用户的令牌(如果可用)自动设置的。但是,对于特殊用例,也可以显式设置此值。
dataflow-server-use-user-access-token当您想要使用当前登录用户的访问令牌并将其传播到 Composed Task Runner 时,存在一个特殊的布尔属性。此属性由 Spring Cloud Data Flow 使用,如果设置为true,则自动填充该dataflow-server-access-token属性。使用dataflow-server-use-user-access-token时,必须为每个任务执行传递。在某些情况下,dataflow-server-access-token默认情况下,最好为每个组合任务启动传递用户的。在这种情况下,将 Spring Cloud Data Flowspring.cloud.dataflow.task.useUserAccessToken属性设置为true。
要为 Composed Task Runner 设置属性,您需要在属性前加上app.composed-task-runner.. 例如要设置dataflow-server-uri属性,该属性将如下所示app.composed-task-runner.dataflow-server-uri。
28.2. 组合任务的生命周期
组合任务的生命周期包含三个部分:
28.2.1. 创建组合任务
通过 task create 命令创建任务定义时使用组合任务的 DSL,如下例所示:
dataflow:> app register --name timestamp --type task --uri maven://org.springframework.cloud.task.app:timestamp-task:
dataflow:> app register --name mytaskapp --type task --uri file:///home/tasks/mytask.jar
dataflow:> task create my-composed-task --definition "mytaskapp && timestamp"
dataflow:> task launch my-composed-task 在前面的示例中,我们假设我们的组合任务要使用的应用程序尚未注册。因此,在前两个步骤中,我们注册了两个任务应用程序。然后我们使用task create命令创建我们的组合任务定义。前面示例中的组合任务 DSL 在启动时运行mytaskapp,然后运行时间戳应用程序。
但在我们启动my-composed-task定义之前,我们可以查看 Spring Cloud Data Flow 为我们生成了什么。这可以通过使用任务列表命令来完成,如下例所示(包括其输出):
dataflow:>task list
╔══════════════════════════╤══════════════════════╤═══════════╗
║ Task Name │ Task Definition │Task Status║
╠══════════════════════════╪══════════════════════╪═══════════╣
║my-composed-task │mytaskapp && timestamp│unknown ║
║my-composed-task-mytaskapp│mytaskapp │unknown ║
║my-composed-task-timestamp│timestamp │unknown ║
╚══════════════════════════╧══════════════════════╧═══════════╝在示例中,Spring Cloud Data Flow 创建了三个任务定义,一个用于构成我们的组合任务 (my-composed-task-mytaskapp和my-composed-task-timestamp) 以及组合任务 ( my-composed-task) 定义的每个应用程序。我们还看到,为子任务生成的每个名称都由组合任务的名称和应用程序的名称组成,并用连字符分隔-(如在my-composed-task - mytaskapp 中)。
任务应用参数
构成组合任务定义的任务应用程序也可以包含参数,如下例所示:
dataflow:> task create my-composed-task --definition "mytaskapp --displayMessage=hello && timestamp --format=YYYY"28.2.2. 启动组合任务
启动组合任务的方式与启动独立任务的方式相同,如下所示:
task launch my-composed-task启动任务后,假设所有任务都成功完成,您可以在运行 a 时看到三个任务执行task execution list,如下例所示:
dataflow:>task execution list
╔══════════════════════════╤═══╤════════════════════════════╤════════════════════════════╤═════════╗
║ Task Name │ID │ Start Time │ End Time │Exit Code║
╠══════════════════════════╪═══╪════════════════════════════╪════════════════════════════╪═════════╣
║my-composed-task-timestamp│713│Wed Apr 12 16:43:07 EDT 2017│Wed Apr 12 16:43:07 EDT 2017│0 ║
║my-composed-task-mytaskapp│712│Wed Apr 12 16:42:57 EDT 2017│Wed Apr 12 16:42:57 EDT 2017│0 ║
║my-composed-task │711│Wed Apr 12 16:42:55 EDT 2017│Wed Apr 12 16:43:15 EDT 2017│0 ║
╚══════════════════════════╧═══╧════════════════════════════╧════════════════════════════╧═════════╝在前面的示例中,我们看到已my-compose-task启动,其他任务也按顺序启动。Exit Code他们每个人都以as成功运行0。
将属性传递给子任务
要在任务启动时为组合任务图中的子任务设置属性,请使用以下格式:app.<composed task definition name>.<child task app name>.<property>. 以下清单显示了一个组合任务定义作为示例:
dataflow:> task create my-composed-task --definition "mytaskapp && mytimestamp"要mytaskapp显示“HELLO”并将mytimestamp时间戳格式设置YYYY为组合任务定义,请使用以下任务启动格式:
task launch my-composed-task --properties "app.my-composed-task.mytaskapp.displayMessage=HELLO,app.my-composed-task.mytimestamp.timestamp.format=YYYY"与应用程序属性类似,您还可以deployer使用以下格式设置子任务的属性deployer.<composed task definition name>.<child task app name>.<deployer-property>:
task launch my-composed-task --properties "deployer.my-composed-task.mytaskapp.memory=2048m,app.my-composed-task.mytimestamp.timestamp.format=HH:mm:ss"
Launched task 'a1'将参数传递给组合任务运行器
您可以使用以下--arguments选项为组合任务运行程序传递命令行参数:
dataflow:>task create my-composed-task --definition "<aaa: timestamp || bbb: timestamp>"
Created new task 'my-composed-task'
dataflow:>task launch my-composed-task --arguments "--increment-instance-enabled=true --max-wait-time=50000 --split-thread-core-pool-size=4" --properties "app.my-composed-task.bbb.timestamp.format=dd/MM/yyyy HH:mm:ss"
Launched task 'my-composed-task'退出状态
以下列表显示了如何为每个步骤执行后组合任务中包含的每个步骤(任务)设置退出状态:
-
如果
TaskExecution有ExitMessage,则将其用作ExitStatus。 -
如果不
ExitMessage存在并且ExitCode设置为零,ExitStatus则步骤的 是COMPLETED。 -
如果 no
ExitMessage存在并且ExitCode设置为任何非零数字,ExitStatus则步骤的 是FAILED。
28.2.3. 销毁组合任务
用于销毁独立任务的命令与用于销毁组合任务的命令相同。唯一的区别是销毁组合任务也会销毁与其关联的子任务。以下示例显示了使用该destroy命令之前和之后的任务列表:
dataflow:>task list
╔══════════════════════════╤══════════════════════╤═══════════╗
║ Task Name │ Task Definition │Task Status║
╠══════════════════════════╪══════════════════════╪═══════════╣
║my-composed-task │mytaskapp && timestamp│COMPLETED ║
║my-composed-task-mytaskapp│mytaskapp │COMPLETED ║
║my-composed-task-timestamp│timestamp │COMPLETED ║
╚══════════════════════════╧══════════════════════╧═══════════╝
...
dataflow:>task destroy my-composed-task
dataflow:>task list
╔═════════╤═══════════════╤═══════════╗
║Task Name│Task Definition│Task Status║
╚═════════╧═══════════════╧═══════════╝28.2.4. 停止组合任务
在需要停止组合任务执行的情况下,您可以通过以下方式完成:
-
RESTful API
-
Spring Cloud 数据流仪表板
要通过仪表板停止组合任务,请选择作业选项卡并单击要停止的作业执行旁边的 *Stop() 按钮。
当当前运行的子任务完成时,组合任务的运行将停止。与在组合任务停止时正在运行的子任务关联的步骤STOPPED以及组合任务作业执行被标记。
28.2.5. 重新启动组合任务
如果组合任务在执行过程中失败并且组合任务的状态为FAILED,则可以重新启动该任务。您可以通过以下方式做到这一点:
-
RESTful API
-
贝壳
-
Spring Cloud 数据流仪表板
要通过 shell 重新启动组合任务,请使用相同的参数启动任务。要通过仪表板重新启动组合任务,请选择作业选项卡,然后单击要重新启动的作业执行旁边的重新启动按钮。
重新启动已停止的组合任务作业(通过 Spring Cloud Data Flow Dashboard 或 RESTful API)重新启动STOPPED子任务,然后按指定顺序启动剩余(未启动)的子任务。
|
29. 组合任务 DSL
组合任务可以通过三种方式运行:
29.1. 条件执行
条件执行使用双 & 符号 ( &&) 表示。这使得序列中的每个任务仅在前一个任务成功完成时才启动,如以下示例所示:
task create my-composed-task --definition "task1 && task2"当被调用的组合任务my-composed-task启动时,它会启动被调用的任务task1,如果task1成功完成,则启动被调用的任务task2。如果task1失败,task2则不启动。
您还可以使用 Spring Cloud Data Flow Dashboard 创建条件执行,方法是使用设计器拖放所需的应用程序并将它们连接在一起以创建有向图,如下图所示:
上图是使用 Spring Cloud Data Flow Dashboard 创建的有向图的屏幕截图。您可以看到图中的四个组件组成了一个条件执行:
-
开始图标:所有有向图都以此符号开始。只有一个。
-
任务图标:表示有向图中的每个任务。
-
结束图标:表示有向图的结束。
-
实线箭头:表示之间的流条件执行流程:
-
两种应用。
-
启动控制节点和一个应用程序。
-
一个应用程序和终端控制节点。
-
-
结束图标:所有有向图都以此符号结束。
| 您可以通过单击“定义”选项卡上组合任务定义旁边 的“详细信息”按钮 来查看有向图的图表。 |
29.2. 过渡执行
DSL 支持对有向图执行期间进行的转换进行细粒度控制。通过提供基于前一个任务的退出状态的相等条件来指定转换。任务转换由以下符号表示->。
29.2.1. 基本过渡
基本转换如下所示:
task create my-transition-composed-task --definition "foo 'FAILED' -> bar 'COMPLETED' -> baz"在前面的示例中,foo将启动,如果它的退出状态为FAILED,则bar任务将启动。如果退出状态foo为COMPLETED,baz将启动。返回的所有其他状态cat均无效,任务将正常结束。
使用 Spring Cloud Data Flow Dashboard 创建相同的“基本转换”将类似于下图:
上图是在 Spring Cloud Data Flow Dashboard 中创建的有向图的屏幕截图。请注意,有两种不同类型的连接器:
-
虚线:表示从应用程序到可能的目标应用程序之一的转换。
-
实线:连接条件执行中的应用程序或应用程序与控制节点(开始或结束)之间的连接。
要创建过渡连接器:
-
创建转换时,使用连接器将应用程序链接到每个可能的目标。
-
完成后,转到每个连接并通过单击将其选中。
-
出现一个螺栓图标。
-
单击该图标。
-
输入该连接器所需的退出状态。
-
该连接器的实线变为虚线。
29.2.2. 使用通配符转换
DSL 的转换支持通配符,如下例所示:
task create my-transition-composed-task --definition "foo 'FAILED' -> bar '*' -> baz"在前面的示例中,foo将启动,如果它的退出状态为FAILED,则bar任务将启动。对于cat除 之外的任何退出状态FAILED,baz将启动。
使用 Spring Cloud Data Flow Dashboard 创建相同的“使用通配符的转换”将类似于下图:
29.2.3. 具有以下条件执行的转换
只要不使用通配符,转换之后就可以进行条件执行,如下例所示:
task create my-transition-conditional-execution-task --definition "foo 'FAILED' -> bar 'UNKNOWN' -> baz && qux && quux"在前面的示例中,foo将启动,如果它的退出状态为FAILED,则bar任务将启动。如果foo退出状态为UNKNOWN,baz将启动。对于除orfoo以外的任何退出状态,将启动,并在成功完成后启动。FAILEDUNKNOWNquxquux
使用 Spring Cloud Data Flow Dashboard 创建相同的“带条件执行的转换”将类似于下图:
在此图中,虚线(转换)将foo应用程序连接到目标应用程序,但实线连接 、 和 之间的foo条件qux执行quux。
|
29.3. 拆分执行
拆分让组合任务中的多个任务并行运行。它通过使用尖括号 ( <>) 对要并行运行的任务和流进行分组来表示。这些任务和流由双竖线||符号分隔,如下例所示:
task create my-split-task --definition "<foo || bar || baz>"前面的示例foo并行bar启动任务baz。
使用 Spring Cloud Data Flow Dashboard 创建相同的“拆分执行”将类似于下图:
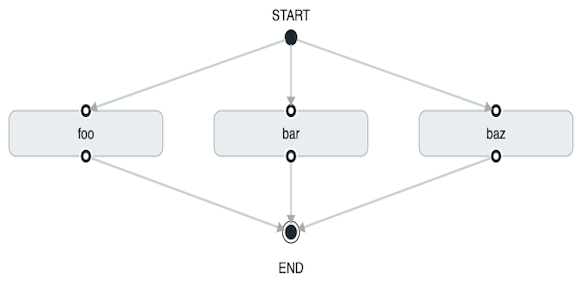
使用任务 DSL,您还可以连续运行多个拆分组,如下例所示:
task create my-split-task --definition "<foo || bar || baz> && <qux || quux>"在前面的示例中,foo并行启动bar、 和任务。baz一旦它们全部完成,则qux和quux任务将并行启动。一旦他们完成,组合的任务就结束了。但是,如果foo、bar或失败,则包含和baz的拆分不会启动。quxquux
使用 Spring Cloud Data Flow Dashboard 创建相同的“多组拆分”将类似于下图:
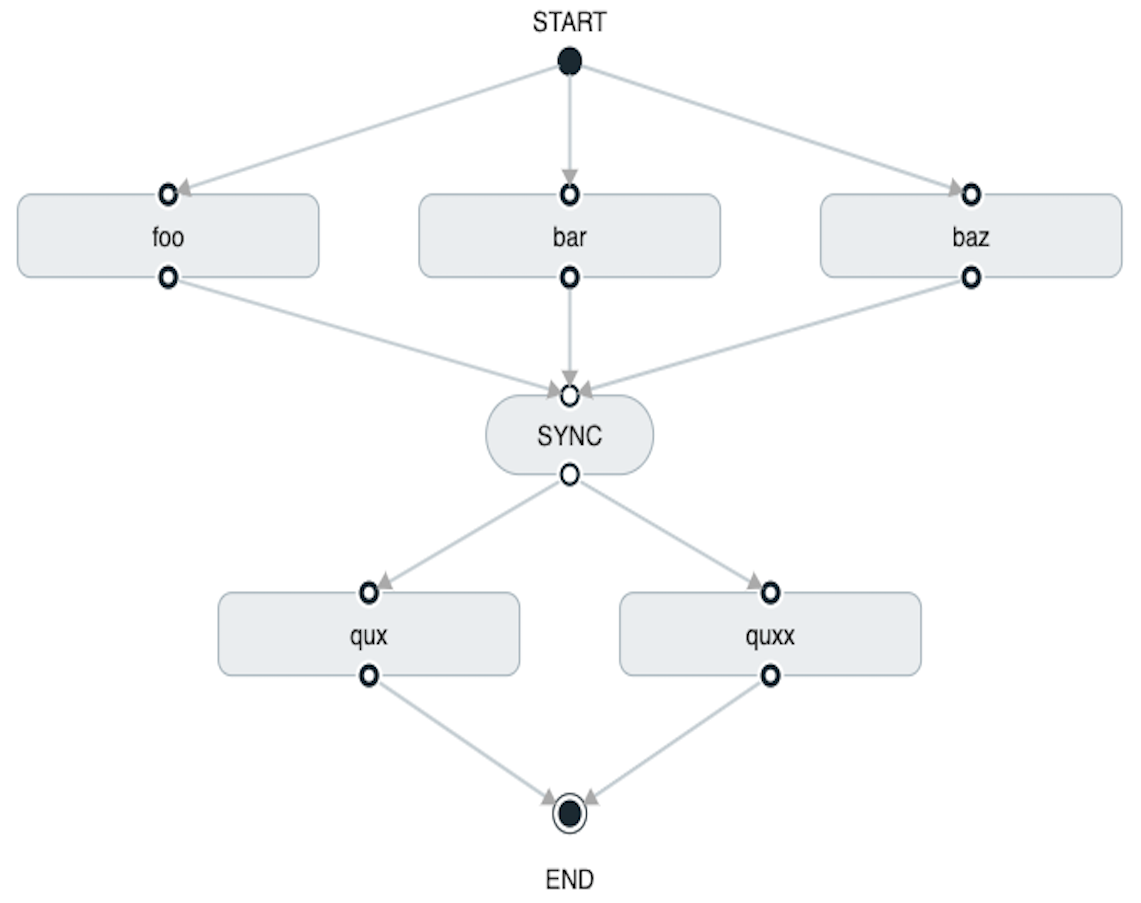
请注意,SYNC在连接两个连续拆分时,设计人员会插入一个控制节点。
拆分中使用的任务不应设置其ExitMessage. 设置ExitMessage仅与转场一起使用。
|
29.3.1. 包含条件执行的拆分
拆分也可以在尖括号内进行条件执行,如下例所示:
task create my-split-task --definition "<foo && bar || baz>"在前面的示例中,我们看到foo并baz并行启动。但是,在成功完成bar之前不会启动foo。
使用 Spring Cloud Data Flow Dashboard 创建相同的“ split containing conditional execution”类似于下图:
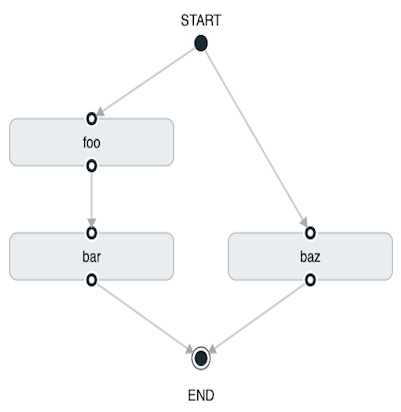
29.3.2. 为拆分建立正确的线程数
拆分中包含的每个子任务都需要一个线程才能运行。要正确设置它,您需要查看图表并找到具有最多子任务数量的拆分。该拆分中的子任务数是您需要的线程数。要设置线程数,请使用split-thread-core-pool-size property(默认为1)。因此,例如,诸如<AAA || BBB || CCC> && <DDD || EEE>requires a split-thread-core-pool-sizeof 之类的定义3。这是因为最大的拆分包含三个子任务。计数为 2 将意味着AAA并行BBB运行,但 CCC 将等待其中一个AAA或BBB完成才能运行。然后将DDD并行EEE运行。
30. 从流中启动任务
您可以使用接收task-launcher-dataflow器从流中启动任务。接收器连接到数据流服务器并使用其 REST API 启动任何定义的任务。接收器接受表示 a的JSON 有效负载task launch request,它提供要启动的任务的名称,并且可能包括命令行参数和部署属性。
该app-starters-task-launch-request-common组件结合 Spring Cloud Stream功能组合,可以将任何源或处理器的输出转换为任务启动请求。
添加依赖项以app-starters-task-launch-request-common自动配置java.util.function.Function实现,通过Spring Cloud Function注册为taskLaunchRequest.
例如,您可以从时间源开始,添加以下依赖项,构建它,并将其注册为自定义源。time-tlr我们在这个例子中称之为:
<dependency>
<groupId>org.springframework.cloud.stream.app</groupId>
<artifactId>app-starters-task-launch-request-common</artifactId>
</dependency>| Spring Cloud Stream Initializr为创建流应用程序提供了一个很好的起点。 |
接下来,注册接收task-launcher-dataflow器并创建一个任务(我们使用提供的时间戳任务):
stream create --name task-every-minute --definition "time-tlr --trigger.fixed-delay=60 --spring.cloud.stream.function.definition=taskLaunchRequest --task.launch.request.task-name=timestamp-task | task-launcher-dataflow" --deploy前面的流每分钟产生一个任务启动请求。该请求提供要启动的任务的名称:{"name":"timestamp-task"}。
以下流定义说明了命令行参数的使用。它生成消息,例如为{"args":["foo=bar","time=12/03/18 17:44:12"],"deploymentProps":{},"name":"timestamp-task"}任务提供命令行参数:
stream create --name task-every-second --definition "time-tlr --spring.cloud.stream.function.definition=taskLaunchRequest --task.launch.request.task-name=timestamp-task --task.launch.request.args=foo=bar --task.launch.request.arg-expressions=time=payload | task-launcher-dataflow" --deploy请注意使用 SpEL 表达式将每个消息负载映射到time命令行参数以及静态参数 ( foo=bar)。
然后,您可以使用 shell 命令查看任务执行列表task execution list,如以下示例中所示(及其输出):
dataflow:>task execution list
╔════════════════════╤══╤════════════════════════════╤════════════════════════════╤═════════╗
║ Task Name │ID│ Start Time │ End Time │Exit Code║
╠════════════════════╪══╪════════════════════════════╪════════════════════════════╪═════════╣
║timestamp-task_26176│4 │Tue May 02 12:13:49 EDT 2017│Tue May 02 12:13:49 EDT 2017│0 ║
║timestamp-task_32996│3 │Tue May 02 12:12:49 EDT 2017│Tue May 02 12:12:49 EDT 2017│0 ║
║timestamp-task_58971│2 │Tue May 02 12:11:50 EDT 2017│Tue May 02 12:11:50 EDT 2017│0 ║
║timestamp-task_13467│1 │Tue May 02 12:10:50 EDT 2017│Tue May 02 12:10:50 EDT 2017│0 ║
╚════════════════════╧══╧════════════════════════════╧════════════════════════════╧═════════╝在此示例中,我们展示了如何使用time源以固定速率启动任务。此模式可应用于任何源以启动任务以响应任何事件。
30.1。从流中启动组合任务
可以使用接收task-launcher-dataflow器启动组合任务,如此处所述。由于我们ComposedTaskRunner直接使用,我们需要在创建组合任务启动流之前为组合任务运行器本身设置任务定义,以及组合任务。假设我们想要创建以下组合任务定义:AAA && BBB. 第一步是创建任务定义,如以下示例所示:
task create composed-task-runner --definition "composed-task-runner"
task create AAA --definition "timestamp"
task create BBB --definition "timestamp"
的版本ComposedTaskRunner可以在
这里找到。
|
现在我们需要组合任务定义的任务定义已经准备就绪,我们需要创建一个可以启动的流ComposedTaskRunner。因此,在这种情况下,我们创建一个流:
-
如前
time所示,定制为发出任务启动请求的源。 -
task-launcher-dataflow启动水槽ComposedTaskRunner
流应类似于以下内容:
stream create ctr-stream --definition "time --fixed-delay=30 --task.launch.request.task-name=composed-task-launcher --task.launch.request.args=--graph=AAA&&BBB,--increment-instance-enabled=true | task-launcher-dataflow"现在,我们专注于启动所需的配置ComposedTaskRunner:
-
graph: 这是要由ComposedTaskRunner. 在这种情况下,它是AAA&&BBB。 -
increment-instance-enabled:这让每次执行ComposedTaskRunner都是独一无二的。ComposedTaskRunner是使用Spring Batch构建的。因此,我们希望每次启动ComposedTaskRunner. 为此,我们设置increment-instance-enabled为true.
31. 与Task共享Spring Cloud Data Flow的Datastore
如Tasks文档中所述,Spring Cloud Data Flow 允许您查看 Spring Cloud Task 应用程序执行。因此,在本节中,我们将讨论任务应用程序和 Spring Cloud Data Flow 共享任务执行信息所需的内容。
31.1。常见的 DataStore 依赖项
Spring Cloud Data Flow 支持许多开箱即用的数据库,因此您通常需要做的就是声明spring_datasource_*环境变量以建立 Spring Cloud Data Flow 需要的数据存储。无论您决定将哪个数据库用于 Spring Cloud Data Flow,请确保您的任务还在其pom.xml或gradle.build文件中包含该数据库依赖项。如果 Spring Cloud Data Flow 使用的数据库依赖项不存在于 Task Application 中,则任务失败并且不会记录任务执行。
31.2. 通用数据存储
Spring Cloud Data Flow 和您的任务应用程序必须访问相同的数据存储实例。这样一来,Spring Cloud Data Flow 可以读取任务应用程序记录的任务执行情况,以在 Shell 和 Dashboard 视图中列出它们。此外,任务应用程序必须对 Spring Cloud Data Flow 使用的任务数据表具有读写权限。
鉴于对 Task 应用程序和 Spring Cloud Data Flow 之间的数据源依赖关系的理解,您现在可以查看如何在各种 Task 编排场景中应用它们。
31.2.1. 简单任务启动
从 Spring Cloud Data Flow 启动任务时,Data Flow 会将其数据源属性(spring.datasource.url、spring.datasource.driverClassName、spring.datasource.username、spring.datasource.password)添加到正在启动的任务的应用程序属性中。因此,任务应用程序将其任务执行信息记录到 Spring Cloud Data Flow 存储库中。
31.2.2. 组合任务运行器
32. 调度任务
Spring Cloud Data Flow 允许您使用cron表达式安排任务的执行。您可以通过 RESTful API 或 Spring Cloud Data Flow UI 创建计划。
32.1。调度器
Spring Cloud Data Flow 通过云平台上可用的调度代理来调度其任务的执行。使用 Cloud Foundry 平台时,Spring Cloud Data Flow 使用PCF Scheduler。使用 Kubernetes 时,将使用CronJob。
| 计划任务不实现持续部署功能。Spring Cloud Data Flow 中任务定义的应用程序版本或属性的任何更改都不会影响计划任务。 |

32.2. 启用调度
默认情况下,Spring Cloud Data Flow 禁用调度功能。要启用调度功能,请将以下功能属性设置为true:
-
spring.cloud.dataflow.features.schedules-enabled -
spring.cloud.dataflow.features.tasks-enabled
32.3. 时间表的生命周期
计划的生命周期包含三个部分:
32.3.1. 调度任务执行
您可以通过以下方式安排任务执行:
-
Spring Cloud 数据流外壳
-
Spring Cloud 数据流仪表板
-
Spring Cloud 数据流 RESTful API
32.3.2. 调度任务
要使用 shell 计划任务,请使用task schedule create命令创建计划,如以下示例所示:
dataflow:>task schedule create --definitionName mytask --name mytaskschedule --expression '*/1 * * * *'
Created schedule 'mytaskschedule'在前面的示例中,我们为名为mytaskschedule的任务定义创建了一个调度mytask。此计划每分钟启动mytask一次。
如果使用 Cloud Foundry,cron上面的表达式将是:*/1 * ? * *. 这是因为 Cloud Foundry 使用 Quartzcron表达式格式。
|
计划名称的最大长度
计划名称的最大字符长度取决于平台。
| Kubernetes | 云铸造 | 当地的 |
|---|---|---|
52 |
63 |
不适用 |
32.3.3. 删除计划
您可以使用以下命令删除计划:
-
Spring Cloud 数据流外壳
-
Spring Cloud 数据流仪表板
-
Spring Cloud 数据流 RESTful API
要使用 shell 删除任务计划,请使用task schedule destroy命令,如以下示例所示:
dataflow:>task schedule destroy --name mytaskschedule
Deleted task schedule 'mytaskschedule'32.3.4. 上市时间表
您可以使用以下方式查看可用的时间表:
-
Spring Cloud 数据流外壳
-
Spring Cloud 数据流仪表板
-
Spring Cloud 数据流 RESTful API
要从 shell 查看您的计划,请使用task schedule list命令,如以下示例所示:
dataflow:>task schedule list
╔══════════════════════════╤════════════════════╤════════════════════════════════════════════════════╗
║ Schedule Name │Task Definition Name│ Properties ║
╠══════════════════════════╪════════════════════╪════════════════════════════════════════════════════╣
║mytaskschedule │mytask │spring.cloud.scheduler.cron.expression = */1 * * * *║
╚══════════════════════════╧════════════════════╧════════════════════════════════════════════════════╝| 可以在此处找到使用 Spring Cloud Data Flow UI 创建、删除和列出计划的说明。 |
33. 持续部署
随着任务应用程序的发展,您希望获得对生产的更新。本节介绍 Spring Cloud Data Flow 围绕能够更新任务应用程序提供的功能。
注册任务应用程序时(请参阅注册任务应用程序),会关联一个版本。一个任务应用程序可以有多个与之关联的版本,其中一个被选为默认版本。下图说明了一个具有多个关联版本的应用程序(请参阅时间戳条目)。
一个应用程序的版本是通过注册多个具有相同名称和坐标的应用程序来管理的,除了版本。例如,如果您要使用以下值注册一个应用程序,您将获得一个注册了两个版本(2.1.0.RELEASE 和 2.1.1.RELEASE)的应用程序:
-
应用 1
-
姓名:
timestamp -
类型:
task -
网址:
maven://org.springframework.cloud.task.app:timestamp-task:2.1.0.RELEASE
-
-
应用 2
-
姓名:
timestamp -
类型:
task -
网址:
maven://org.springframework.cloud.task.app:timestamp-task:2.1.1.RELEASE
-
除了有多个版本之外,Spring Cloud Data Flow 还需要知道下次启动时要运行哪个版本。这通过将版本设置为默认版本来指示。无论任务应用程序的哪个版本被配置为默认版本,都将在下一个启动请求上运行。您可以在 UI 中查看默认版本,如下图所示:
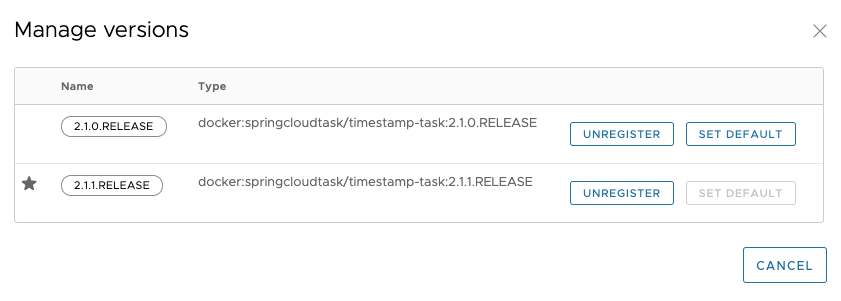
33.1. 任务启动生命周期
在以前的 Spring Cloud Data Flow 版本中,当收到启动任务的请求时,Spring Cloud Data Flow 将部署应用程序(如果需要)并运行它。如果应用程序在不需要每次都部署应用程序的平台上运行(例如 CloudFoundry),则使用之前部署的应用程序。此流程在 2.3 中已更改。下图显示了现在收到任务启动请求时会发生什么:
上图中需要考虑三个主要流程。第一次启动或不更改启动是其中之一。另外两个在有更改但应用程序当前未启动时启动,并在有更改且应用程序正在运行时启动。我们首先查看没有变化的流程。
33.1.1. 启动没有更改的任务
-
启动请求进入数据流。数据流确定不需要升级,因为没有任何变化(自上次执行以来没有任何属性、部署属性或版本发生变化)。
-
在缓存已部署工件的平台上(CloudFoundry,在撰写本文时),Data Flow 会检查应用程序之前是否已部署。
-
如果需要部署应用程序,Data Flow 会部署任务应用程序。
-
数据流启动应用程序。
此流程是默认行为,如果没有任何更改,则在每次请求进入时发生。请注意,这与 Data Flow 始终用于启动任务的流程相同。
33.1.2. 使用当前未运行的更改启动任务
启动任务时要考虑的第二个流程是任务未运行但任务应用程序版本、应用程序属性或部署属性中的任何一个发生更改时。在这种情况下,将执行以下流程:
-
启动请求进入数据流。数据流确定需要升级,因为任务应用程序版本、应用程序属性或部署属性发生了变化。
-
数据流检查任务定义的另一个实例当前是否正在运行。
-
如果当前没有运行任务定义的其他实例,则删除旧部署。
-
在缓存已部署工件的平台上(CloudFoundry,在撰写本文时),数据流检查应用程序是否先前已部署(此检查
false在此流中评估为,因为旧部署已被删除)。 -
数据流使用更新的值(新应用程序版本、新合并属性和新合并部署属性)部署任务应用程序。
-
数据流启动应用程序。
这个流程从根本上实现了 Spring Cloud Data Flow 的持续部署。
33.1.3. 在另一个实例运行时启动具有更改的任务
最后一个主要流程是当启动请求来到 Spring Cloud Data Flow 进行升级但任务定义当前正在运行时。在这种情况下,由于需要删除当前应用程序,启动被阻止。在某些平台上(CloudFoundry,在撰写本文时),删除应用程序会导致所有当前正在运行的应用程序被关闭。此功能可防止这种情况发生。以下过程描述了在另一个实例运行时任务更改时会发生什么:
-
启动请求进入数据流。数据流确定需要升级,因为任务应用程序版本、应用程序属性或部署属性发生了变化。
-
数据流检查任务定义的另一个实例当前是否正在运行。
-
数据流阻止启动发生,因为任务定义的其他实例正在运行。
| 由于需要删除任何当前正在运行的任务,任何需要升级在请求时正在运行的任务定义的启动都会被阻止运行。 |
任务开发者指南
任务监控
仪表板
本节介绍如何使用 Spring Cloud Data Flow 的仪表板。
34. 简介
Spring Cloud Data Flow 提供了一个名为 Dashboard 的基于浏览器的 GUI 来管理以下信息:
-
应用程序:应用程序选项卡列出了所有可用的应用程序,并提供了注册和注销它们的控件。
-
运行时:运行时选项卡提供所有正在运行的应用程序的列表。
-
Streams:Streams选项卡允许您列出、设计、创建、部署和销毁流定义。
-
任务:任务选项卡允许您列出、创建、启动、计划和销毁任务定义。
-
作业:作业选项卡允许您执行与批处理作业相关的功能。
启动 Spring Cloud Data Flow 后,仪表板位于:
例如,如果 Spring Cloud Data Flow 在本地运行,则仪表板位于localhost:9393/dashboard.
如果您已启用 HTTPS,则仪表板位于localhost:9393/dashboard。如果您启用了安全性,登录表单可在localhost:9393/dashboard/#/login.
默认仪表板服务器端口是9393.
|
下图显示了 Spring Cloud Data Flow 仪表板的打开页面:

35. 应用程序
仪表板的应用程序选项卡列出了所有可用的应用程序,并提供了注册和注销它们的控件(如果适用)。您可以使用批量导入应用程序操作一次导入多个应用程序。
下图显示了仪表板中可用应用程序的典型列表:
35.1。批量导入应用程序
可以通过“应用程序”页面上提供的多种方式导入应用程序。对于批量导入,应用程序定义应以属性样式表示,如下所示:
<type>.<name> = <coordinates>以下示例显示了典型的应用程序定义:
task.timestamp=maven://org.springframework.cloud.task.app:timestamp-task:1.2.0.RELEASE
processor.transform=maven://org.springframework.cloud.stream.app:transform-processor-rabbit:1.2.0.RELEASE在“从 HTTP URI 位置导入应用程序坐标”部分中,您可以指定一个指向存储在其他地方的属性文件的 URI,它应该包含格式如上例所示的属性。或者,通过使用“从属性文件导入应用程序坐标”部分中的应用程序作为属性文本框,您可以直接列出每个属性字符串。最后,如果属性存储在本地文件中,“导入文件”选项将打开本地文件浏览器以选择文件。通过这些途径之一设置您的定义后,单击Import Application(s)。
下图显示了批量导入应用程序的一种方法的示例页面:
36. 运行时
仪表板应用程序的运行时选项卡显示所有正在运行的应用程序的列表。对于每个运行时应用程序,会显示部署状态和已部署实例的数量。单击应用程序 ID 可获得所用部署属性的列表。
下图显示了正在使用的运行时选项卡的示例:
37. 流
Streams选项卡有两个子选项卡:Definitions和Create Stream。以下主题描述了如何使用每个主题:
37.1。使用流定义
仪表板的Streams部分包括提供流定义列表的Definitions选项卡。您可以选择部署或取消部署这些流定义。此外,您可以通过单击Destroy删除定义。每行左侧都有一个箭头,您可以单击该箭头来查看定义的可视化表示。将鼠标悬停在可视化表示中的框上会显示有关应用程序的更多详细信息,包括传递给它们的任何选项。
在以下屏幕截图中,timer流已被扩展以显示视觉表示:
如果单击详细信息按钮,视图会更改以显示该流和任何相关流的可视化表示。在前面的例子中,如果你点击timer流的详细信息,视图会变成下面的视图,它清楚地显示了三个流之间的关系(其中两个正在接入timer流):
37.2. 创建流
Dashboard的Streams部分包括Create Stream选项卡,它使Spring Flo设计器可用。设计器是一个画布应用程序,它提供用于创建数据管道的交互式图形界面。
在此选项卡中,您可以:
-
使用 DSL、图形画布或同时使用两者来创建、管理和可视化流管道
-
使用带有内容辅助和自动完成功能的 DSL 编写管道
-
在 GUI 中使用自动调整和网格布局功能,以更简单和交互式地组织管道
下图显示了正在使用的 Flo 设计器:
37.3。部署流
流部署页面包括提供不同方法来设置部署属性和部署流的选项卡。以下屏幕截图显示了foobar( time | log) 的流部署页面。
您可以使用以下方法定义部署属性:
-
表单构建器选项卡:帮助您定义部署属性(部署器、应用程序属性等)的构建器
-
自由文本选项卡:自由文本区域(用于键值对)
您可以在两个视图之间切换。
| 表单构建器对输入提供了更强的验证。 |
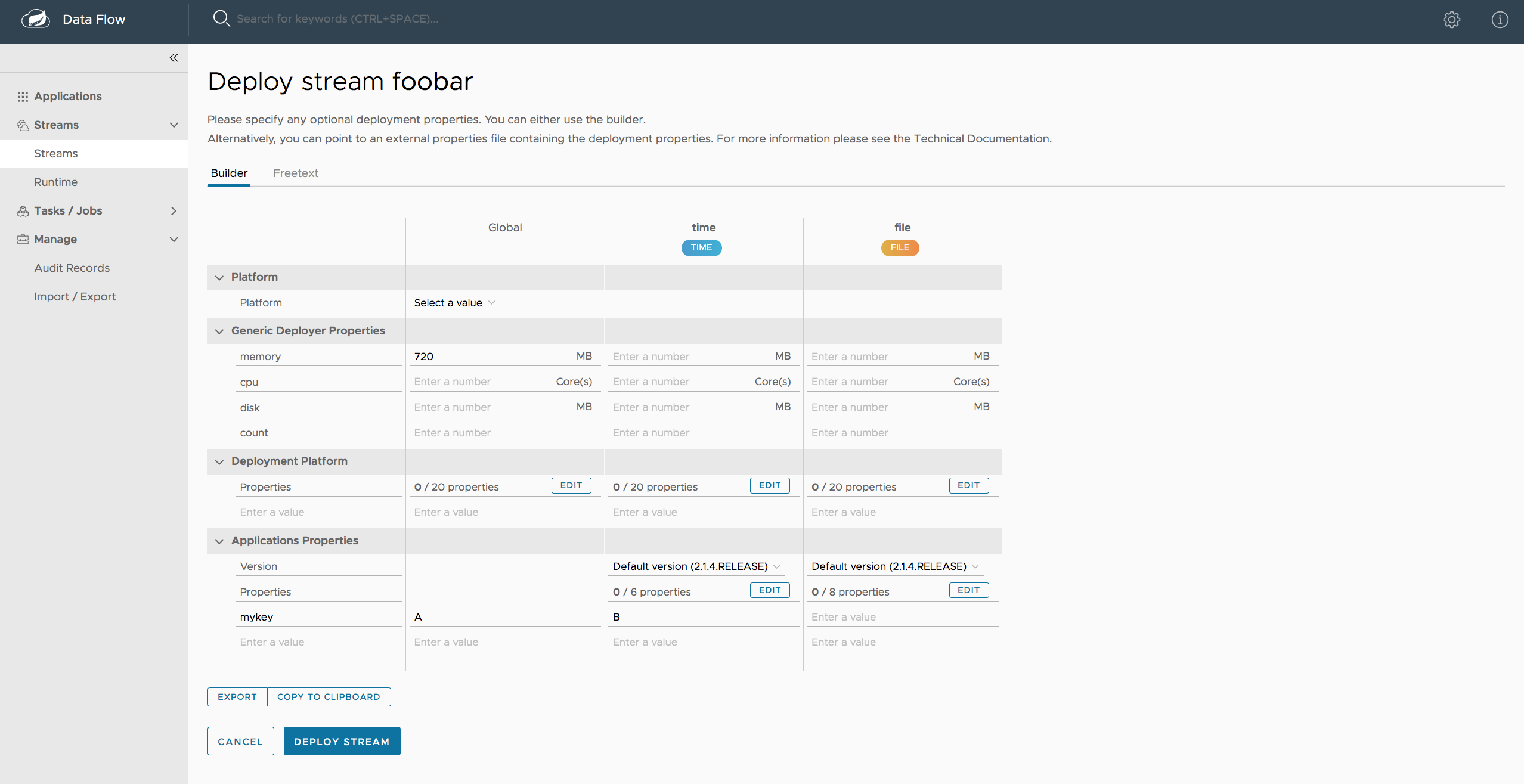
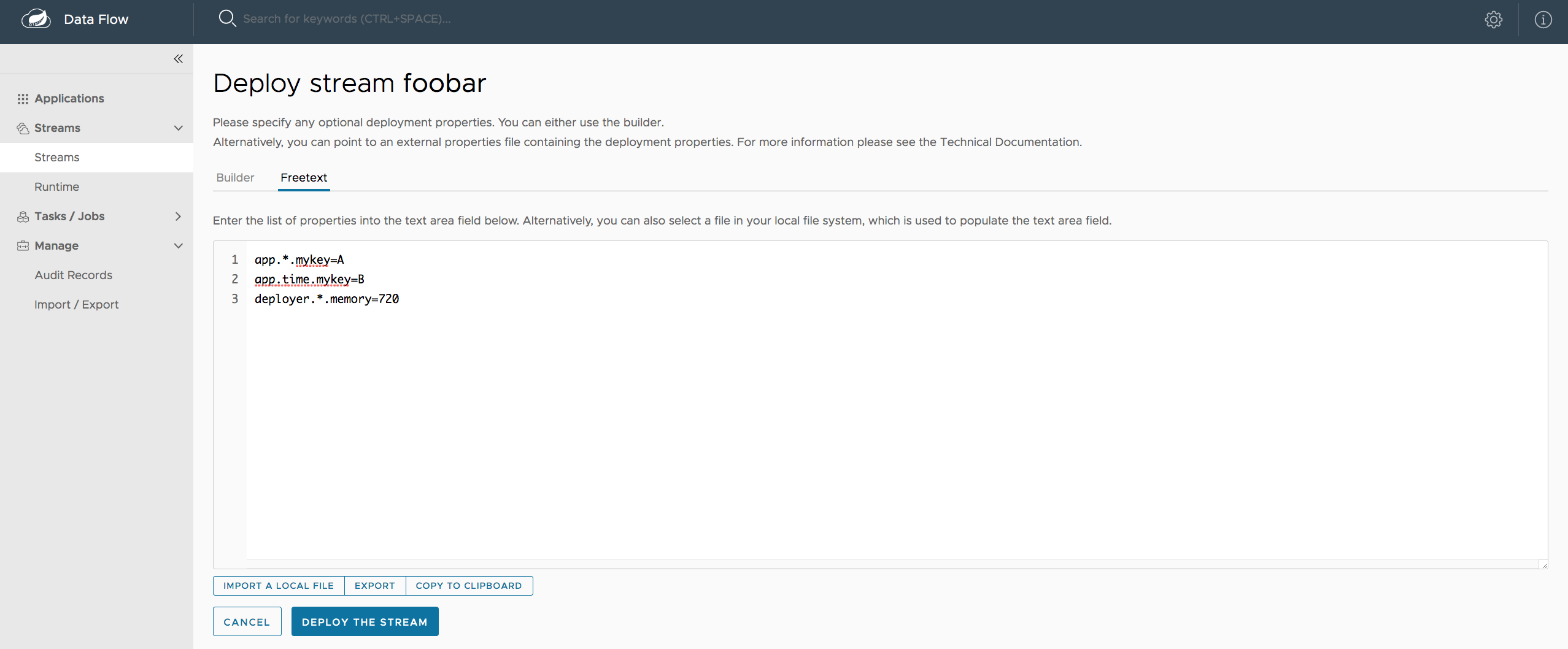
37.4。访问流日志
部署流应用程序后,可以从 Streamsummary页面访问其日志,如下图所示:
37.5。创建扇入和扇出流
在扇入和扇出一章中,您可以了解如何使用命名目标来支持扇入和扇出用例。UI 还为命名目的地提供了专门的支持:
在此示例中,我们有来自HTTP 源和JDBC 源的数据,它们被发送到 sharedData通道,这代表了一个扇入用例。在另一端,我们有一个Cassandra Sink和一个订阅sharedData通道的File Sink,这代表了一个扇出用例。
37.6。创建点击流
使用仪表板创建水龙头非常简单。假设您有一个由HTTP Source和File Sink组成的流,并且您希望利用该流也将数据发送到JDBC Sink。要创建点击流,请将HTTP Source的输出连接器连接到JDBC Sink。连接显示为虚线,表示您创建了一个分流流。
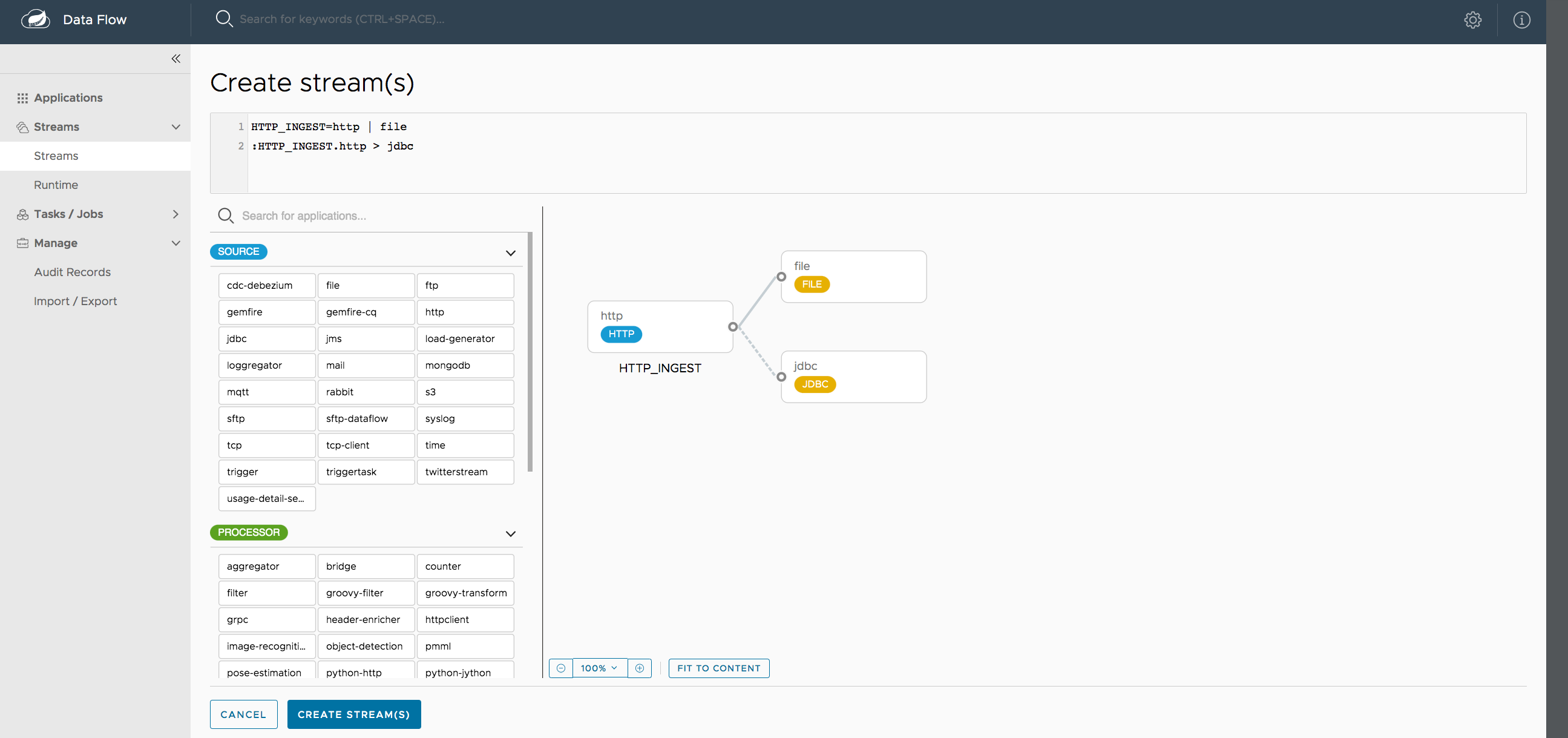
主要流(HTTP Source to File Sink)将被自动命名,以防您尚未提供流的名称。创建分流流时,必须始终明确命名主要流。在上图中,主要流被命名为HTTP_INGEST。
通过使用仪表板,您还可以切换主要流,使其成为次要分流流。
将鼠标悬停在现有的主流上,即HTTP Source和File Sink之间的线。出现几个控制图标,通过单击标有Switch to/from tap的图标,您可以将主要流更改为点击流。对分流流执行相同操作并将其切换到主流。
| 当直接与命名目的地交互时,可以有“n”个组合(输入/输出)。这使您可以创建涉及各种数据源和目标的复杂拓扑。 |
37.7。导入和导出流
仪表板的导入/导出选项卡包含一个页面,该页面提供导入和导出流的选项。
下图显示了流导出页面:
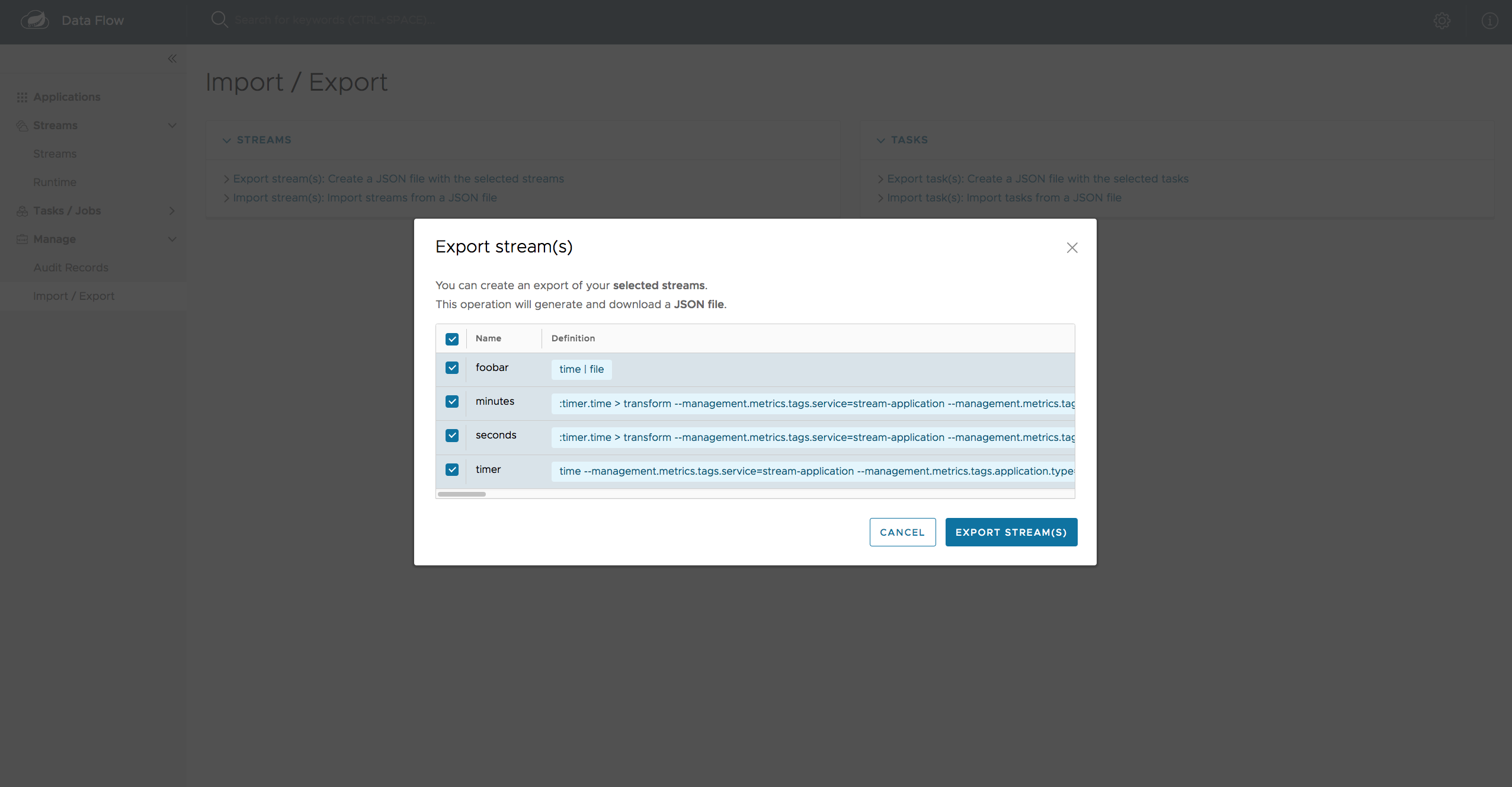
导入流时,您必须从有效的 JSON 文件导入。您可以手动起草文件或从流导出页面导出文件。
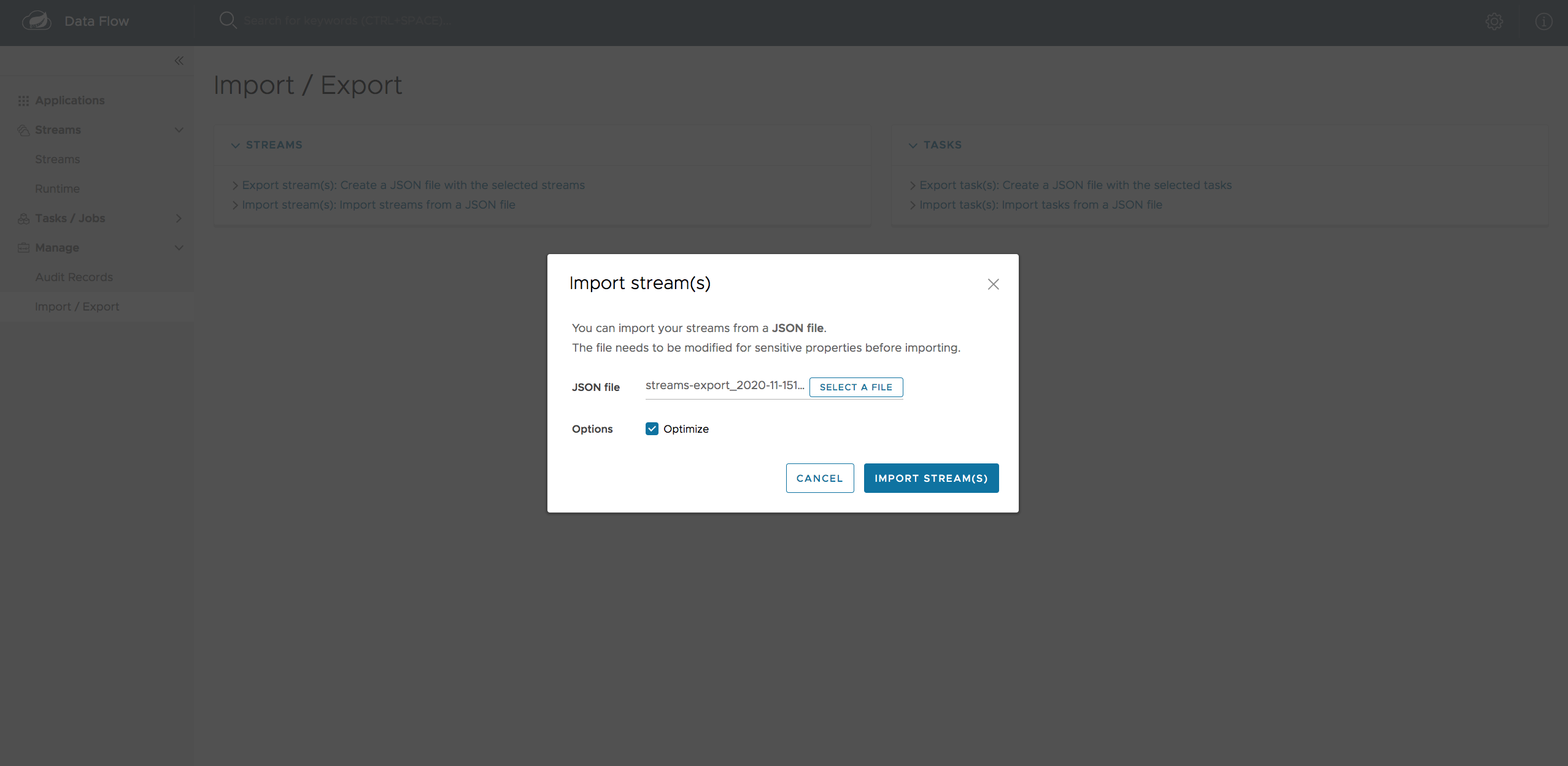
导入文件后,您将确认操作是否成功完成。
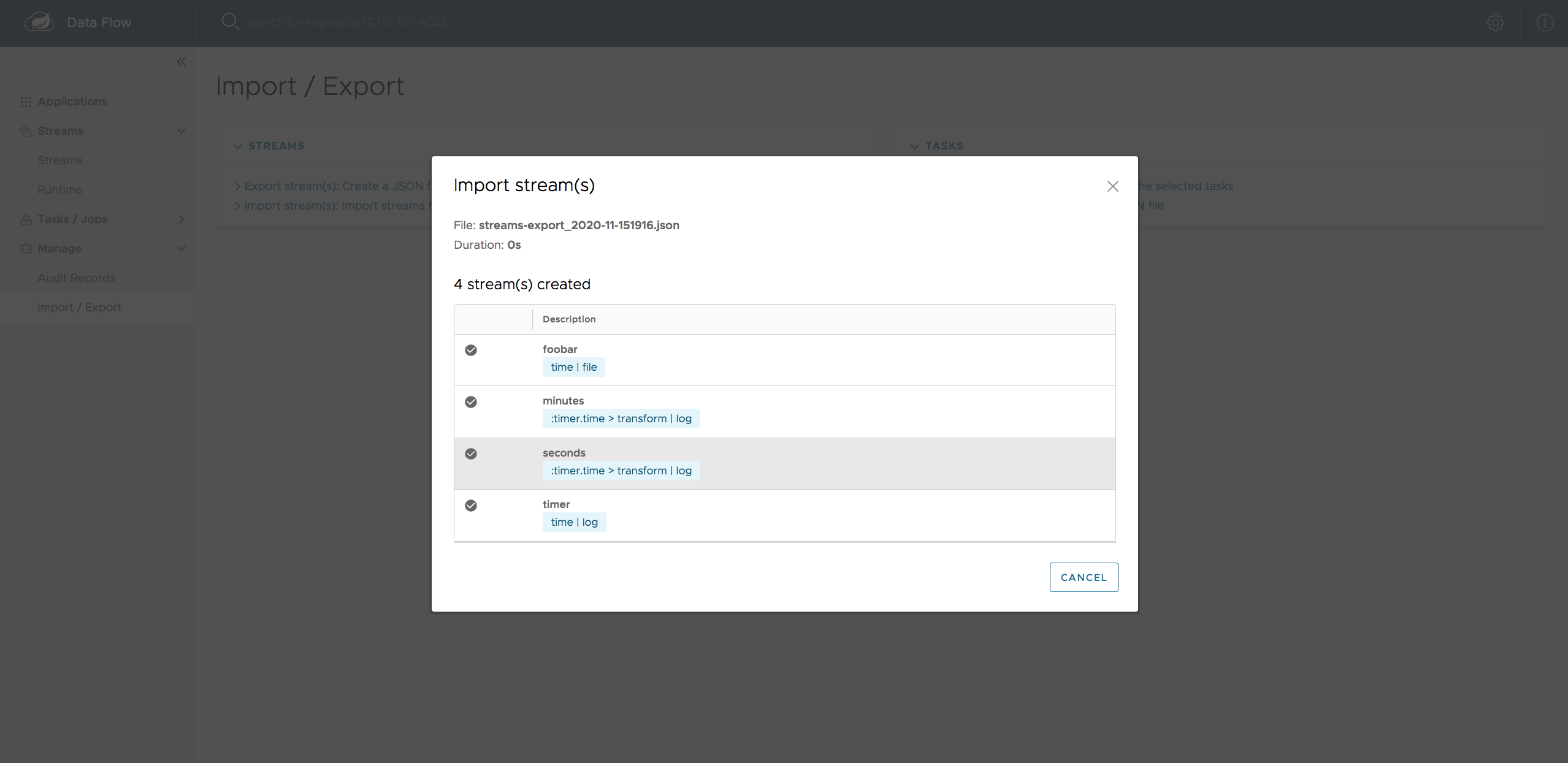
38. 任务
仪表板的任务选项卡当前具有三个选项卡:
38.1。应用
每个应用程序都将一个工作单元封装到一个可重用的组件中。在 Data Flow 运行时环境中,应用程序允许您为流和任务创建定义。因此,任务选项卡中的应用程序选项卡允许您创建任务定义。
| 您还可以使用此选项卡创建批处理作业。 |
下图显示了任务应用程序的典型列表:
在此屏幕上,您可以执行以下操作:
-
查看详细信息,例如任务应用程序选项。
-
从相应的应用程序创建任务定义。
38.1.1。查看任务申请详情
在此页面上,您可以查看所选任务应用程序的详细信息,包括该应用程序的可用选项(属性)列表。
38.2. 定义
此页面列出数据流任务定义并提供启动或销毁这些任务的操作。
下图显示了定义页面:
38.2.1。创建任务定义
下图显示了由时间戳应用程序以及可用于创建任务定义的任务应用程序列表组成的任务定义:
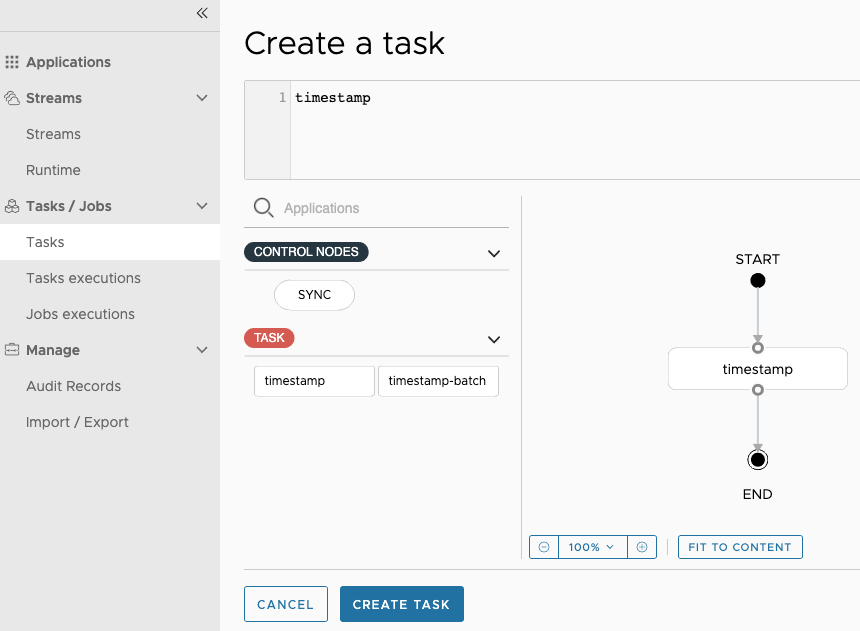
在此页面上,您还可以指定在应用程序部署期间使用的各种属性。一旦您对任务定义感到满意,您可以单击CREATE TASK按钮。然后会出现一个对话框,询问任务定义名称和描述。至少,您必须为新定义提供一个名称。
38.2.2. 创建组合任务定义
仪表板包括“创建组合任务”选项卡,它提供了用于创建组合任务的交互式图形界面。
在此选项卡中,您可以:
-
使用 DSL、图形画布或两者兼而有之,创建和可视化组合任务。
-
使用 GUI 中的自动调整和网格布局功能,以更简单和交互式地组织组合任务。
在创建组合任务屏幕上,您可以通过输入参数键和参数值来定义一个或多个任务参数。
| 未键入任务参数。 |
下图显示了组合的任务设计器:
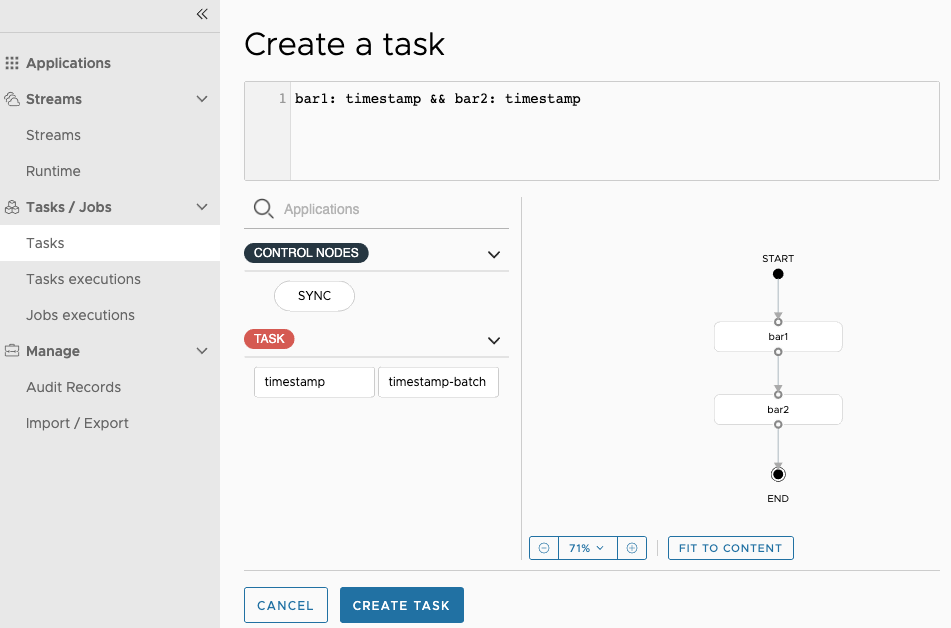
38.2.3. 启动任务
创建任务定义后,您可以通过仪表板启动任务。为此,请单击任务选项卡,然后按 选择要启动的任务Launch。下图显示了任务启动页面:
38.2.4. 导入/导出任务
导入/导出页面提供导入和导出任务的选项。这是通过单击页面左侧的导入/导出选项来完成的。在此处,单击导出任务:使用所选任务创建 JSON 文件选项。Export Tasks(s)页面出现。
下图显示了任务导出页面:
同样,您可以导入任务定义。为此,请单击页面左侧的导入/导出选项。在此处,单击导入任务:从 JSON 文件导入任务选项以显示导入任务页面。在Import Tasks页面上,您必须从有效的 JSON 文件导入。您可以手动起草文件或从“任务导出”页面导出文件。
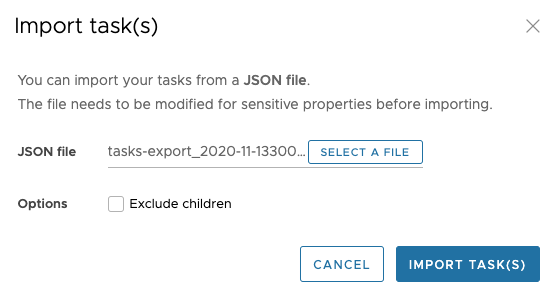
导入文件后,您将确认操作是否成功完成。
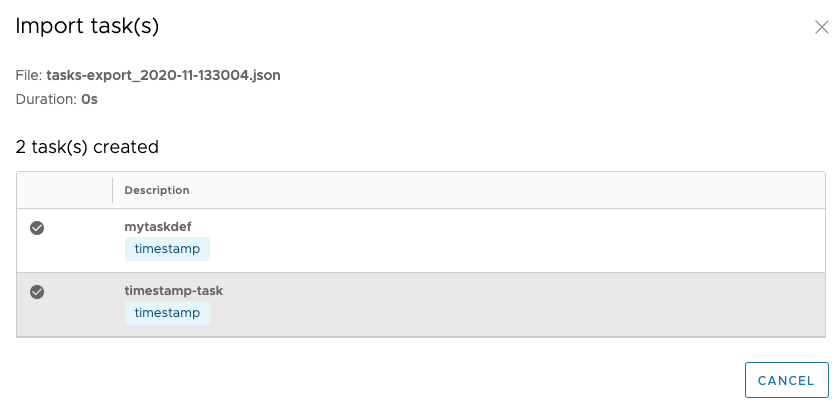
38.3. 处决
任务执行选项卡显示当前正在运行和已完成的任务执行。在此页面中,您可以深入了解“任务执行详细信息”页面。此外,您可以重新启动任务执行或停止正在运行的执行。
最后,您可以清理一个或多个任务执行。此操作从底层持久性存储中删除任何关联的任务或批处理作业。此操作只能在父任务执行时触发,并级联到子任务执行(如果有的话)。
下图显示了执行选项卡:

38.4. 执行细节
对于“任务执行”选项卡上的每个任务执行,您可以通过单击任务执行的执行 ID来检索有关特定执行的详细信息。
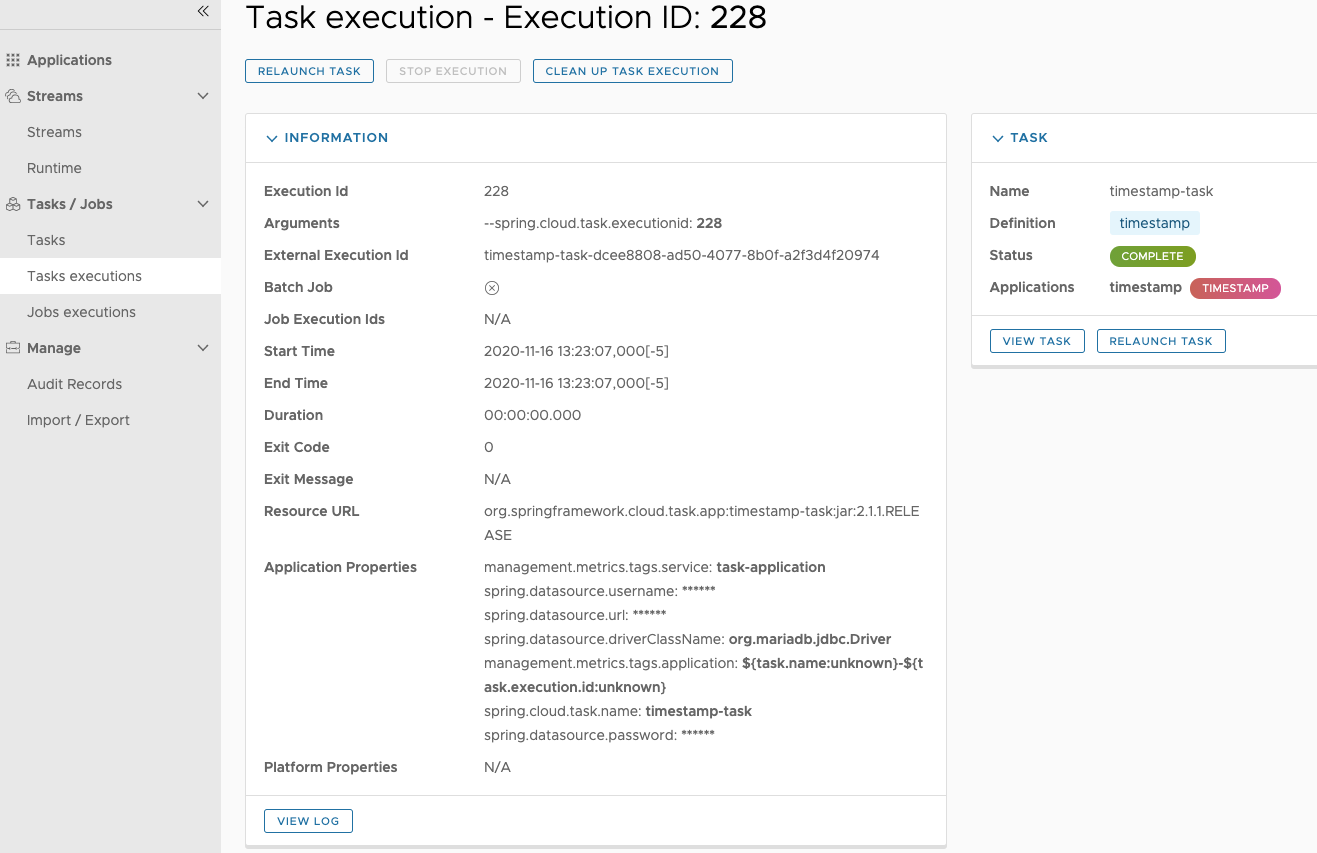
在此屏幕上,您不仅可以查看来自任务执行页面的信息,还可以查看:
-
任务参数
-
外部执行 ID
-
批处理作业指示器(指示任务执行是否包含 Spring Batch 作业。)
-
作业执行 ID 链接(单击作业执行 ID 将转到该作业执行 ID 的作业执行详细信息。)
-
任务执行持续时间
-
任务执行退出消息
-
记录任务执行的输出
此外,您还可以触发以下操作:
-
重新启动任务
-
停止正在运行的任务
-
任务执行清理(仅适用于父任务执行)
38.4.1。停止执行任务
要向平台提交停止任务执行请求,请单击需要停止的任务执行旁边的下拉按钮。现在单击停止任务选项。仪表板显示一个对话框,询问您是否确定要停止任务执行。如果是,请单击Stop Task Execution(s)。
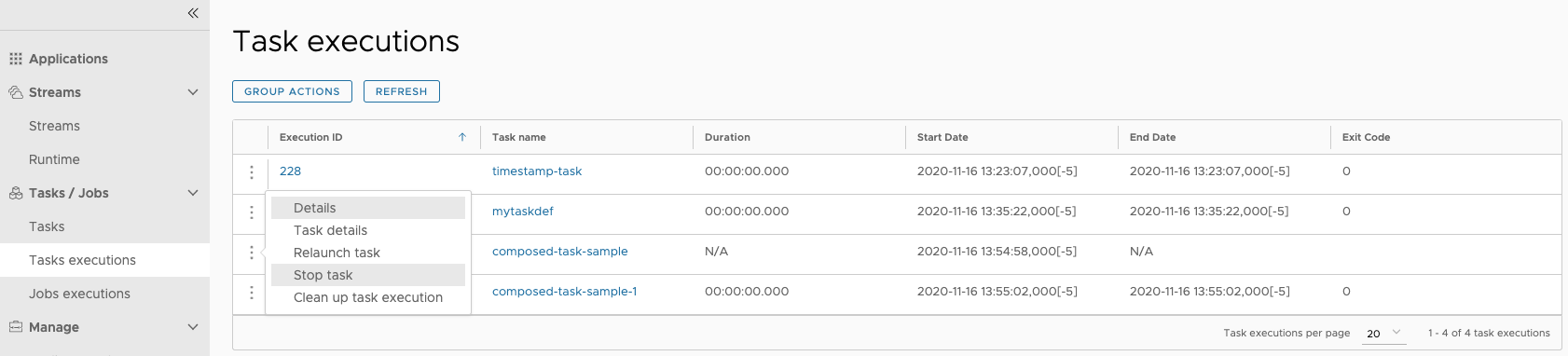
| 通过使用远程分区的 Spring Batch 应用程序启动的子 Spring Cloud Task 应用程序不会停止。 |
39. 工作
Dashboard的Job Executions选项卡允许您检查批处理作业。屏幕的主要部分提供作业执行列表。批处理作业是每个执行一个或多个批处理作业的任务。每个作业执行都有一个对任务执行 ID 的引用(在任务 ID 列中)。
作业执行列表还显示了底层作业定义的状态。因此,如果基础定义已被删除,“未找到定义”会出现在“状态”列中。
您可以对每个作业执行以下操作:
-
重新启动(对于失败的作业)。
-
停止(用于运行作业)。
-
查看执行详细信息。
| 单击停止按钮实际上会向正在运行的作业发送停止请求,该作业可能不会立即停止。 |
下图显示了“作业”选项卡:

39.1。作业执行细节
启动批处理作业后,作业执行详细信息页面会显示有关作业的信息。
下图显示了作业执行详细信息页面:
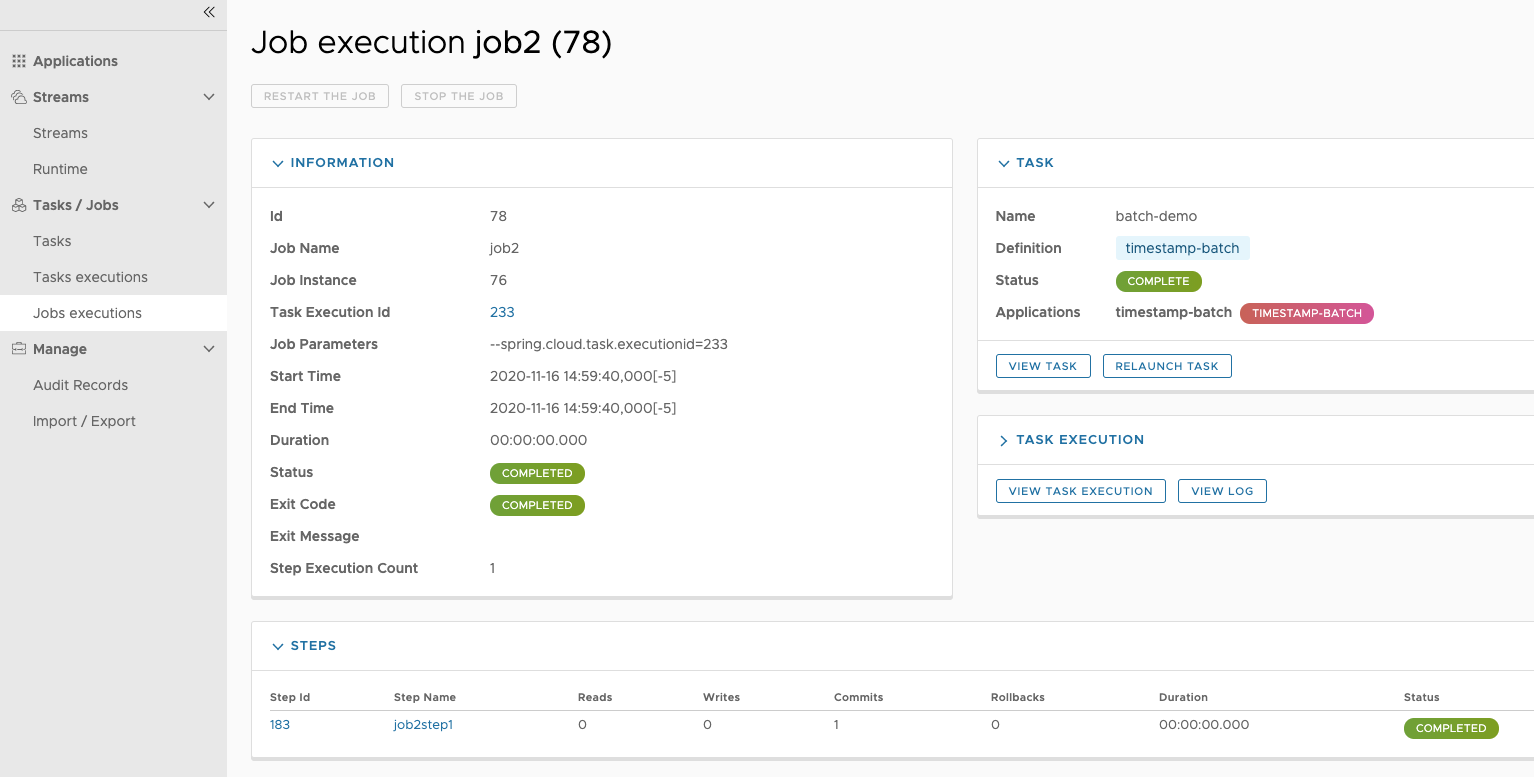
Job Execution Details 页面包含已执行步骤的列表。您可以通过单击放大镜图标进一步深入了解每个步骤的执行细节。
39.2. 步骤执行详情
“步骤执行详细信息”页面提供有关作业中单个步骤的信息。
下图显示了 Step Execution Details 页面:
Step Execution Details 屏幕提供了所有 Step Execution Context 键值对的完整列表。
| 对于例外情况,退出说明字段包含其他错误信息。但是,此字段最多可包含 2500 个字符。因此,在长异常堆栈跟踪的情况下,可能会出现错误消息的修剪。发生这种情况时,请检查服务器日志文件以获取更多详细信息。 |
39.3. 步骤执行历史
在Step Execution History下,您还可以查看与所选步骤相关的各种指标,例如持续时间、读取计数、写入计数等。
40. 调度
您可以从 SCDF 仪表板为任务定义创建计划。有关详细信息,请参阅微型站点的调度批处理作业部分。
41. 审计
仪表板的审核页面使您可以访问记录的审核事件。记录审计事件:
-
流
-
创造
-
删除
-
部署
-
取消部署
-
-
任务
-
创造
-
删除
-
发射
-
-
任务调度
-
创建时间表
-
删除时间表
-
下图显示了审核记录页面:
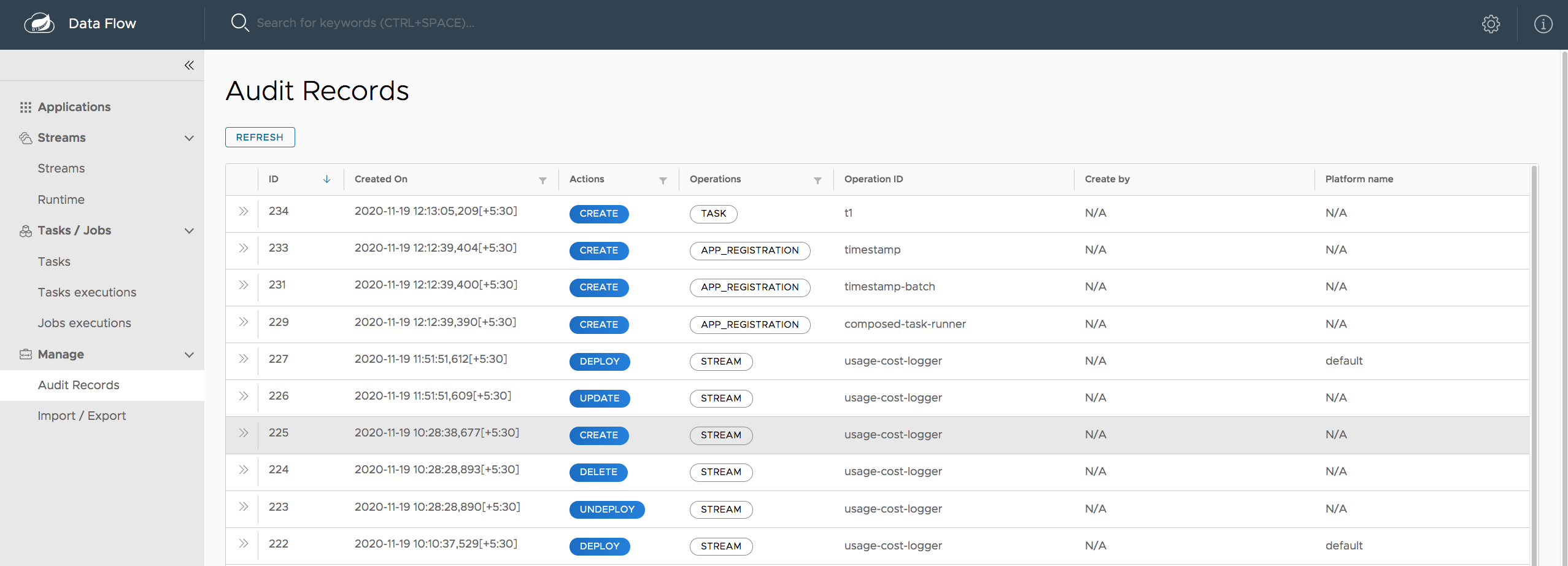
通过单击显示详细信息图标(右侧圆圈中的“i”),您可以获得有关审计详细信息的更多详细信息:
通常,审计提供以下信息:
-
记录是什么时候创建的?
-
触发审核事件的用户的名称(如果启用了安全性)
-
审计操作(计划、流或任务)
-
执行的操作(创建、删除、部署、回滚、取消部署或更新)
-
相关 ID,例如流或任务名称
-
审计数据
审计数据属性的写入值取决于执行的审计操作和操作类型。例如,在创建计划时,任务定义的名称、任务定义属性、部署属性和命令行参数将被写入持久性存储。
在保存审计记录之前,我们会尽最大努力对敏感信息进行清理。正在检测以下任何键,并且它们的敏感值被屏蔽:
-
密码
-
秘密
-
钥匙
-
令牌
-
。*证书。*
-
vcap_services
样品
本节显示可用的示例。
42. 链接
提供以下示例:
REST API 指南
本节介绍 Spring Cloud Data Flow REST API。
43. 概述
Spring Cloud Data Flow 提供了一个 REST API,让您可以访问服务器的所有方面。事实上,Spring Cloud Data Flow shell 是该 API 的一流使用者。
如果您计划将 REST API 与 Java 一起使用,则应考虑使用提供的 Java 客户端 ( DataflowTemplate),该客户端在内部使用 REST API。
|
43.1。HTTP 动词
Spring Cloud Data Flow 在使用 HTTP 动词时尝试尽可能地遵守标准 HTTP 和 REST 约定,如下表所述:
| 动词 | 用法 |
|---|---|
|
用于检索资源。 |
|
用于创建新资源。 |
|
用于更新现有资源,包括部分更新。也用于暗示 的概念的资源 |
|
用于删除现有资源。 |
43.2. HTTP 状态码
Spring Cloud Data Flow 在使用 HTTP 状态码时尽量遵循标准 HTTP 和 REST 约定,如下表所示:
| 状态码 | 用法 |
|---|---|
|
请求成功完成。 |
|
已成功创建新资源。资源的 URI 可从响应的 |
|
已成功应用对现有资源的更新。 |
|
请求格式不正确。响应正文包括提供更多信息的错误描述。 |
|
请求的资源不存在。 |
|
请求的资源已经存在。例如,任务已存在或流已被部署 |
|
在无法停止或重新启动作业执行的情况下返回。 |
43.3. 标头
每个响应都有以下标头:
| 姓名 | 描述 |
|---|---|
|
有效负载的 Content-Type,例如 |
43.4. 错误
| 小路 | 类型 | 描述 |
|---|---|---|
|
|
发生的 HTTP 错误,例如 |
|
|
错误原因的描述 |
|
|
发出请求的路径 |
|
|
HTTP 状态码,例如 |
|
|
错误发生的时间,以毫秒为单位 |
43.5。超媒体
Spring Cloud Data Flow 使用超媒体,资源在其响应中包含指向其他资源的链接。响应采用资源到资源语言 (HAL)格式的超文本应用程序。链接可以在_links键下方找到。API 的用户不应自己创建 URI。相反,他们应该使用上述链接进行导航。
44. 资源
API 包括以下资源:
44.1。指数
该索引提供了 Spring Cloud Data Flow 的 REST API 的入口点。以下主题提供了更多详细信息:
44.1.1. 访问索引
使用GET请求访问索引。
请求结构
GET / HTTP/1.1
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/' -i -X GET响应结构
| 小路 | 类型 | 描述 |
|---|---|---|
|
|
其他资源的链接 |
|
|
每次在此 REST API 中实现更改时递增 |
|
|
链接到审计记录 |
|
|
链接到仪表板 |
|
|
链接到流/定义 |
|
|
链接到流/定义/定义 |
|
|
链接流/定义/定义是模板化的 |
|
|
链接到运行时/应用程序 |
|
|
链接到运行时/apps/{appId} |
|
|
链接运行时/应用程序是模板化的 |
|
|
链接到运行时/apps/{appId}/instances |
|
|
链接 runtime/apps/{appId}/instances 是模板化的 |
|
|
链接到运行时/apps/{appId}/instances/{instanceId} |
|
|
链接 runtime/apps/{appId}/instances/{instanceId} 是模板化的 |
|
|
链接到运行时/流 |
|
|
链接运行时/流是模板化的 |
|
|
链接到运行时/流/{streamNames} |
|
|
链接 runtime/streams/{streamNames} 是模板化的 |
|
|
链接到流/日志 |
|
|
链接到流/日志/{streamName} |
|
|
链接到流/日志/{streamName}/{appName} |
|
|
链接流/日志/{streamName} 已模板化 |
|
|
链接流/日志/{streamName}/{appName} 已模板化 |
|
|
链接到流/部署 |
|
|
链接到流/部署 |
|
|
链接流/部署/{name} 已模板化 |
|
|
链接流/部署/{name} 已模板化 |
|
|
链接流/部署/{name} 已模板化 |
|
|
链接流/部署/{name} 已模板化 |
|
|
链接流/部署/{name} 已模板化 |
|
|
链接到流/部署/部署 |
|
|
链接流/部署/部署是模板化的 |
|
|
链接到流/部署/清单/{name}/{version} |
|
|
链接流/部署/清单/{name}/{version} 已模板化 |
|
|
链接到流/部署/历史/{name} |
|
|
链接流/部署/历史是模板化的 |
|
|
链接到流/部署/回滚/{name}/{version} |
|
|
链接流/部署/回滚/{name}/{version} 已模板化 |
|
|
链接到流/部署/更新/{name} |
|
|
链接流/部署/更新/{name} 已模板化 |
|
|
链接到流/部署/平台/列表 |
|
|
链接到流/部署/规模/{streamName}/{appName}/instances/{count} |
|
|
链接流/部署/规模/{streamName}/{appName}/instances/{count} 是模板化的 |
|
|
链接到流/验证 |
|
|
链接流/验证是模板化的 |
|
|
链接到任务/平台 |
|
|
链接到任务/定义 |
|
|
链接到任务/定义/定义 |
|
|
链接任务/定义/定义是模板化的 |
|
|
链接到任务/执行 |
|
|
链接到任务/执行/名称 |
|
|
链接任务/执行/名称是模板化的 |
|
|
链接到任务/执行/当前 |
|
|
链接到任务/执行/执行 |
|
|
链接任务/执行/执行是模板化的 |
|
|
链接到任务/信息/执行 |
|
|
链接任务/信息是模板化的 |
|
|
链接到任务/日志 |
|
|
链接任务/日志是模板化的 |
|
|
链接到任务/执行/时间表 |
|
|
链接到任务/计划/实例 |
|
|
链接任务/计划/实例是模板化的 |
|
|
链接到任务/验证 |
|
|
链接任务/验证是模板化的 |
|
|
链接到工作/执行 |
|
|
链接到工作/精简执行 |
|
|
链接到工作/执行/名称 |
|
|
链接作业/执行/名称是模板化的 |
|
|
链接到工作/执行/状态 |
|
|
链接作业/执行/状态是模板化的 |
|
|
链接到工作/精简执行/名称 |
|
|
链接作业/执行/名称是模板化的 |
|
|
链接到作业/瘦执行/jobInstanceId |
|
|
链接作业/执行/jobInstanceId 是模板化的 |
|
|
链接到jobs/thinexecutions/taskExecutionId |
|
|
链接作业/执行/taskExecutionId 是模板化的 |
|
|
链接到作业/执行/执行 |
|
|
链接作业/执行/执行是模板化的 |
|
|
链接到作业/执行/执行/步骤 |
|
|
链接作业/执行/执行/步骤是模板化的 |
|
|
链接到作业/执行/执行/步骤/步骤 |
|
|
链接作业/执行/执行/步骤/步骤是模板化的 |
|
|
链接到作业/执行/执行/步骤/步骤/进度 |
|
|
链接作业/执行/执行/步骤/步骤/进度是模板化的 |
|
|
链接到工作/实例/名称 |
|
|
链接作业/实例/名称已模板化 |
|
|
链接到作业/实例/实例 |
|
|
链接作业/实例/实例是模板化的 |
|
|
链接到工具/parseTaskTextToGraph |
|
|
链接到工具/convertTaskGraphToText |
|
|
链接到应用程序 |
|
|
链接到关于 |
|
|
链接到完成/流 |
|
|
链接完成/流是模板化的 |
|
|
链接到完成/任务 |
|
|
链接完成/任务是模板化的 |
示例响应
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 7064
{
"_links" : {
"dashboard" : {
"href" : "http://localhost:9393/dashboard"
},
"audit-records" : {
"href" : "http://localhost:9393/audit-records"
},
"streams/definitions" : {
"href" : "http://localhost:9393/streams/definitions"
},
"streams/definitions/definition" : {
"href" : "http://localhost:9393/streams/definitions/{name}",
"templated" : true
},
"streams/validation" : {
"href" : "http://localhost:9393/streams/validation/{name}",
"templated" : true
},
"runtime/streams" : {
"href" : "http://localhost:9393/runtime/streams{?names}",
"templated" : true
},
"runtime/streams/{streamNames}" : {
"href" : "http://localhost:9393/runtime/streams/{streamNames}",
"templated" : true
},
"runtime/apps" : {
"href" : "http://localhost:9393/runtime/apps"
},
"runtime/apps/{appId}" : {
"href" : "http://localhost:9393/runtime/apps/{appId}",
"templated" : true
},
"runtime/apps/{appId}/instances" : {
"href" : "http://localhost:9393/runtime/apps/{appId}/instances",
"templated" : true
},
"runtime/apps/{appId}/instances/{instanceId}" : {
"href" : "http://localhost:9393/runtime/apps/{appId}/instances/{instanceId}",
"templated" : true
},
"streams/deployments" : {
"href" : "http://localhost:9393/streams/deployments"
},
"streams/deployments/{name}{?reuse-deployment-properties}" : {
"href" : "http://localhost:9393/streams/deployments/{name}?reuse-deployment-properties=false",
"templated" : true
},
"streams/deployments/{name}" : {
"href" : "http://localhost:9393/streams/deployments/{name}",
"templated" : true
},
"streams/deployments/history/{name}" : {
"href" : "http://localhost:9393/streams/deployments/history/{name}",
"templated" : true
},
"streams/deployments/manifest/{name}/{version}" : {
"href" : "http://localhost:9393/streams/deployments/manifest/{name}/{version}",
"templated" : true
},
"streams/deployments/platform/list" : {
"href" : "http://localhost:9393/streams/deployments/platform/list"
},
"streams/deployments/rollback/{name}/{version}" : {
"href" : "http://localhost:9393/streams/deployments/rollback/{name}/{version}",
"templated" : true
},
"streams/deployments/update/{name}" : {
"href" : "http://localhost:9393/streams/deployments/update/{name}",
"templated" : true
},
"streams/deployments/deployment" : {
"href" : "http://localhost:9393/streams/deployments/{name}",
"templated" : true
},
"streams/deployments/scale/{streamName}/{appName}/instances/{count}" : {
"href" : "http://localhost:9393/streams/deployments/scale/{streamName}/{appName}/instances/{count}",
"templated" : true
},
"streams/logs" : {
"href" : "http://localhost:9393/streams/logs"
},
"streams/logs/{streamName}" : {
"href" : "http://localhost:9393/streams/logs/{streamName}",
"templated" : true
},
"streams/logs/{streamName}/{appName}" : {
"href" : "http://localhost:9393/streams/logs/{streamName}/{appName}",
"templated" : true
},
"tasks/platforms" : {
"href" : "http://localhost:9393/tasks/platforms"
},
"tasks/definitions" : {
"href" : "http://localhost:9393/tasks/definitions"
},
"tasks/definitions/definition" : {
"href" : "http://localhost:9393/tasks/definitions/{name}",
"templated" : true
},
"tasks/executions" : {
"href" : "http://localhost:9393/tasks/executions"
},
"tasks/executions/name" : {
"href" : "http://localhost:9393/tasks/executions{?name}",
"templated" : true
},
"tasks/executions/current" : {
"href" : "http://localhost:9393/tasks/executions/current"
},
"tasks/executions/execution" : {
"href" : "http://localhost:9393/tasks/executions/{id}",
"templated" : true
},
"tasks/validation" : {
"href" : "http://localhost:9393/tasks/validation/{name}",
"templated" : true
},
"tasks/info/executions" : {
"href" : "http://localhost:9393/tasks/info/executions{?completed,name}",
"templated" : true
},
"tasks/logs" : {
"href" : "http://localhost:9393/tasks/logs/{taskExternalExecutionId}{?platformName}",
"templated" : true
},
"tasks/schedules" : {
"href" : "http://localhost:9393/tasks/schedules"
},
"tasks/schedules/instances" : {
"href" : "http://localhost:9393/tasks/schedules/instances/{taskDefinitionName}",
"templated" : true
},
"jobs/executions" : {
"href" : "http://localhost:9393/jobs/executions"
},
"jobs/executions/name" : {
"href" : "http://localhost:9393/jobs/executions{?name}",
"templated" : true
},
"jobs/executions/status" : {
"href" : "http://localhost:9393/jobs/executions{?status}",
"templated" : true
},
"jobs/executions/execution" : {
"href" : "http://localhost:9393/jobs/executions/{id}",
"templated" : true
},
"jobs/executions/execution/steps" : {
"href" : "http://localhost:9393/jobs/executions/{jobExecutionId}/steps",
"templated" : true
},
"jobs/executions/execution/steps/step" : {
"href" : "http://localhost:9393/jobs/executions/{jobExecutionId}/steps/{stepId}",
"templated" : true
},
"jobs/executions/execution/steps/step/progress" : {
"href" : "http://localhost:9393/jobs/executions/{jobExecutionId}/steps/{stepId}/progress",
"templated" : true
},
"jobs/instances/name" : {
"href" : "http://localhost:9393/jobs/instances{?name}",
"templated" : true
},
"jobs/instances/instance" : {
"href" : "http://localhost:9393/jobs/instances/{id}",
"templated" : true
},
"tools/parseTaskTextToGraph" : {
"href" : "http://localhost:9393/tools"
},
"tools/convertTaskGraphToText" : {
"href" : "http://localhost:9393/tools"
},
"jobs/thinexecutions" : {
"href" : "http://localhost:9393/jobs/thinexecutions"
},
"jobs/thinexecutions/name" : {
"href" : "http://localhost:9393/jobs/thinexecutions{?name}",
"templated" : true
},
"jobs/thinexecutions/jobInstanceId" : {
"href" : "http://localhost:9393/jobs/thinexecutions{?jobInstanceId}",
"templated" : true
},
"jobs/thinexecutions/taskExecutionId" : {
"href" : "http://localhost:9393/jobs/thinexecutions{?taskExecutionId}",
"templated" : true
},
"apps" : {
"href" : "http://localhost:9393/apps"
},
"about" : {
"href" : "http://localhost:9393/about"
},
"completions/stream" : {
"href" : "http://localhost:9393/completions/stream{?start,detailLevel}",
"templated" : true
},
"completions/task" : {
"href" : "http://localhost:9393/completions/task{?start,detailLevel}",
"templated" : true
}
},
"api.revision" : 14
}链接
索引的主要元素是链接,因为它们允许您遍历 API 并执行所需的功能:
| 关系 | 描述 |
|---|---|
|
访问元信息,包括启用的功能、安全信息、版本信息 |
|
访问仪表板 UI |
|
提供审计跟踪信息 |
|
处理已注册的申请 |
|
公开 Stream 的 DSL 完成功能 |
|
公开 Task 的 DSL 完成功能 |
|
提供 JobExecution 资源 |
|
提供不包含步骤执行的 JobExecution 精简资源 |
|
提供特定 JobExecution 的详细信息 |
|
提供 JobExecution 的步骤 |
|
返回特定步骤的详细信息 |
|
提供特定步骤的进度信息 |
|
按作业名称检索作业执行 |
|
按作业状态检索作业执行 |
|
按作业名称检索作业执行,不包括步骤执行 |
|
按作业实例 ID 检索作业执行,不包括步骤执行 |
|
按任务执行 ID 检索作业执行,不包括步骤执行 |
|
为特定作业实例提供作业实例资源 |
|
为特定作业名称提供作业实例资源 |
|
公开流运行时状态 |
|
公开给定流名称的流运行时状态 |
|
提供运行时应用程序资源 |
|
公开特定应用程序的运行时状态 |
|
提供应用实例的状态 |
|
提供特定应用实例的状态 |
|
提供任务定义资源 |
|
提供特定任务定义的详细信息 |
|
为任务定义提供验证 |
|
返回任务执行并允许启动任务 |
|
提供当前正在运行的任务数 |
|
提供任务执行信息 |
|
提供任务的计划信息 |
|
提供特定任务的计划信息 |
|
返回给定任务名称的所有任务执行 |
|
提供特定任务执行的详细信息 |
|
提供用于启动任务的平台帐户。可以通过添加请求参数 'schedulesEnabled=true 过滤结果以显示支持调度的平台 |
|
检索任务应用程序日志 |
|
公开 Streams 资源 |
|
处理特定的 Stream 定义 |
|
提供流定义的验证 |
|
提供 Stream 部署操作 |
|
请求流定义的部署信息 |
|
请求流定义的部署信息 |
|
请求(取消)部署现有流定义 |
|
返回发布版本的清单信息 |
|
获取流的部署历史作为此版本的列表或版本 |
|
将流回滚到流的先前版本或特定版本 |
|
更新流。 |
|
支持的部署平台列表 |
|
为选定的流增加或减少应用程序实例的数量 |
|
检索流的应用程序日志 |
|
检索流的应用程序日志 |
|
检索流的特定应用程序日志 |
|
将任务定义解析为图结构 |
|
将图形格式转换为 DSL 文本格式 |
44.2. 服务器元信息
服务器元信息端点提供有关服务器本身的更多信息。以下主题提供了更多详细信息:
44.2.1. 检索有关服务器的信息
一个GET请求返回 Spring Cloud Data Flow 的元信息,包括:
-
运行时环境信息
-
有关启用哪些功能的信息
-
Spring Cloud Data Flow Server的依赖信息
-
安全信息
请求结构
GET /about HTTP/1.1
Accept: application/json
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/about' -i -X GET \
-H 'Accept: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 2601
{
"featureInfo" : {
"analyticsEnabled" : true,
"streamsEnabled" : true,
"tasksEnabled" : true,
"schedulesEnabled" : true,
"monitoringDashboardType" : "NONE"
},
"versionInfo" : {
"implementation" : {
"name" : "${info.app.name}",
"version" : "${info.app.version}"
},
"core" : {
"name" : "Spring Cloud Data Flow Core",
"version" : "2.9.4"
},
"dashboard" : {
"name" : "Spring Cloud Dataflow UI",
"version" : "3.2.4"
},
"shell" : {
"name" : "Spring Cloud Data Flow Shell",
"version" : "2.9.4",
"url" : "https://repo1.maven.org/maven2/org/springframework/cloud/spring-cloud-dataflow-shell/2.9.4/spring-cloud-dataflow-shell-2.9.4.jar"
}
},
"securityInfo" : {
"authenticationEnabled" : false,
"authenticated" : false,
"username" : null,
"roles" : [ ]
},
"runtimeEnvironment" : {
"appDeployer" : {
"deployerImplementationVersion" : "Test Version",
"deployerName" : "Test Server",
"deployerSpiVersion" : "2.8.4",
"javaVersion" : "1.8.0_322",
"platformApiVersion" : "",
"platformClientVersion" : "",
"platformHostVersion" : "",
"platformSpecificInfo" : {
"default" : "local"
},
"platformType" : "Skipper Managed",
"springBootVersion" : "2.5.12",
"springVersion" : "5.3.18"
},
"taskLaunchers" : [ {
"deployerImplementationVersion" : "2.7.4",
"deployerName" : "LocalTaskLauncher",
"deployerSpiVersion" : "2.7.4",
"javaVersion" : "1.8.0_322",
"platformApiVersion" : "Linux 5.13.0-1017-azure",
"platformClientVersion" : "5.13.0-1017-azure",
"platformHostVersion" : "5.13.0-1017-azure",
"platformSpecificInfo" : { },
"platformType" : "Local",
"springBootVersion" : "2.5.12",
"springVersion" : "5.3.18"
}, {
"deployerImplementationVersion" : "2.7.4",
"deployerName" : "LocalTaskLauncher",
"deployerSpiVersion" : "2.7.4",
"javaVersion" : "1.8.0_322",
"platformApiVersion" : "Linux 5.13.0-1017-azure",
"platformClientVersion" : "5.13.0-1017-azure",
"platformHostVersion" : "5.13.0-1017-azure",
"platformSpecificInfo" : { },
"platformType" : "Local",
"springBootVersion" : "2.5.12",
"springVersion" : "5.3.18"
} ]
},
"monitoringDashboardInfo" : {
"url" : "",
"refreshInterval" : 15,
"dashboardType" : "NONE",
"source" : "default-scdf-source"
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/about"
}
}
}44.3. 注册申请
注册的应用程序端点提供有关向 Spring Cloud Data Flow 服务器注册的应用程序的信息。以下主题提供了更多详细信息:
44.3.1. 列出应用程序
GET请求列出 Spring Cloud Data Flow 已知的所有应用程序。以下主题提供了更多详细信息:
请求结构
GET /apps?search=&type=source&defaultVersion=true&page=0&size=10&sort=name%2CASC HTTP/1.1
Accept: application/json
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
对名称执行的搜索字符串(可选) |
|
将返回的应用程序限制为应用程序的类型。[应用程序,源,处理器,接收器,任务]之一 |
|
设置为仅检索默认版本的应用程序的布尔标志(可选) |
|
从零开始的页码(可选) |
|
列表上的排序(可选) |
|
请求的页面大小(可选) |
示例请求
$ curl 'http://localhost:9393/apps?search=&type=source&defaultVersion=true&page=0&size=10&sort=name%2CASC' -i -X GET \
-H 'Accept: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 1097
{
"_embedded" : {
"appRegistrationResourceList" : [ {
"name" : "http",
"type" : "source",
"uri" : "maven://org.springframework.cloud.stream.app:http-source-rabbit:1.2.0.RELEASE",
"version" : "1.2.0.RELEASE",
"defaultVersion" : true,
"versions" : [ "1.2.0.RELEASE" ],
"label" : null,
"_links" : {
"self" : {
"href" : "http://localhost:9393/apps/source/http/1.2.0.RELEASE"
}
}
}, {
"name" : "time",
"type" : "source",
"uri" : "maven://org.springframework.cloud.stream.app:time-source-rabbit:1.2.0.RELEASE",
"version" : "1.2.0.RELEASE",
"defaultVersion" : true,
"versions" : [ "1.2.0.RELEASE" ],
"label" : null,
"_links" : {
"self" : {
"href" : "http://localhost:9393/apps/source/time/1.2.0.RELEASE"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/apps?page=0&size=10&sort=name,asc"
}
},
"page" : {
"size" : 10,
"totalElements" : 2,
"totalPages" : 1,
"number" : 0
}
}44.3.2. 获取有关特定应用程序的信息
GET请求/apps/<type>/<name>获取有关特定应用程序的信息。以下主题提供了更多详细信息:
请求结构
GET /apps/source/http?exhaustive=false HTTP/1.1
Accept: application/json
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
返回所有应用程序属性,包括常见的 Spring Boot 属性 |
路径参数
/apps/{类型}/{名称}
| 范围 | 描述 |
|---|---|
|
要查询的应用程序类型。[应用程序,源,处理器,接收器,任务]之一 |
|
要查询的应用程序的名称 |
示例请求
$ curl 'http://localhost:9393/apps/source/http?exhaustive=false' -i -X GET \
-H 'Accept: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 2100
{
"name" : "http",
"type" : "source",
"uri" : "maven://org.springframework.cloud.stream.app:http-source-rabbit:1.2.0.RELEASE",
"version" : "1.2.0.RELEASE",
"defaultVersion" : true,
"versions" : null,
"label" : null,
"options" : [ {
"id" : "http.path-pattern",
"name" : "path-pattern",
"type" : "java.lang.String",
"description" : "An Ant-Style pattern to determine which http requests will be captured.",
"shortDescription" : "An Ant-Style pattern to determine which http requests will be captured.",
"defaultValue" : "/",
"hints" : {
"keyHints" : [ ],
"keyProviders" : [ ],
"valueHints" : [ ],
"valueProviders" : [ ]
},
"deprecation" : null,
"deprecated" : false
}, {
"id" : "http.mapped-request-headers",
"name" : "mapped-request-headers",
"type" : "java.lang.String[]",
"description" : "Headers that will be mapped.",
"shortDescription" : "Headers that will be mapped.",
"defaultValue" : null,
"hints" : {
"keyHints" : [ ],
"keyProviders" : [ ],
"valueHints" : [ ],
"valueProviders" : [ ]
},
"deprecation" : null,
"deprecated" : false
}, {
"id" : "http.secured",
"name" : "secured",
"type" : "java.lang.Boolean",
"description" : "Secure or not HTTP source path.",
"shortDescription" : "Secure or not HTTP source path.",
"defaultValue" : false,
"hints" : {
"keyHints" : [ ],
"keyProviders" : [ ],
"valueHints" : [ ],
"valueProviders" : [ ]
},
"deprecation" : null,
"deprecated" : false
}, {
"id" : "server.port",
"name" : "port",
"type" : "java.lang.Integer",
"description" : "Server HTTP port.",
"shortDescription" : "Server HTTP port.",
"defaultValue" : null,
"hints" : {
"keyHints" : [ ],
"keyProviders" : [ ],
"valueHints" : [ ],
"valueProviders" : [ ]
},
"deprecation" : null,
"deprecated" : false
} ],
"shortDescription" : null,
"inboundPortNames" : [ ],
"outboundPortNames" : [ ],
"optionGroups" : { }
}44.3.3. 注册新应用程序
一个POST请求/apps/<type>/<name>允许注册一个新的应用程序。以下主题提供了更多详细信息:
请求结构
POST /apps/source/http HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
uri=maven%3A%2F%2Forg.springframework.cloud.stream.app%3Ahttp-source-rabbit%3A1.1.0.RELEASE请求参数
| 范围 | 描述 |
|---|---|
|
应用程序位所在的 URI |
|
可以找到应用程序元数据 jar 的 URI |
|
如果已经存在同名同类型的注册必须为真,否则会报错 |
路径参数
/apps/{类型}/{名称}
| 范围 | 描述 |
|---|---|
|
要注册的应用程序类型。[应用程序,源,处理器,接收器,任务]之一 |
|
要注册的应用程序的名称 |
示例请求
$ curl 'http://localhost:9393/apps/source/http' -i -X POST \
-d 'uri=maven%3A%2F%2Forg.springframework.cloud.stream.app%3Ahttp-source-rabbit%3A1.1.0.RELEASE'响应结构
HTTP/1.1 201 Created44.3.4. 使用版本注册新应用程序
一个POST请求/apps/<type>/<name>/<version>允许注册一个新的应用程序。以下主题提供了更多详细信息:
请求结构
POST /apps/source/http/1.1.0.RELEASE HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
uri=maven%3A%2F%2Forg.springframework.cloud.stream.app%3Ahttp-source-rabbit%3A1.1.0.RELEASE请求参数
| 范围 | 描述 |
|---|---|
|
应用程序位所在的 URI |
|
可以找到应用程序元数据 jar 的 URI |
|
如果已经存在同名同类型的注册必须为真,否则会报错 |
路径参数
/apps/{type}/{name}/{version:.+}
| 范围 | 描述 |
|---|---|
|
要注册的应用程序类型。[app, source, processor, sink, task] 之一(可选) |
|
要注册的应用程序的名称 |
|
要注册的应用程序版本 |
示例请求
$ curl 'http://localhost:9393/apps/source/http/1.1.0.RELEASE' -i -X POST \
-d 'uri=maven%3A%2F%2Forg.springframework.cloud.stream.app%3Ahttp-source-rabbit%3A1.1.0.RELEASE'响应结构
HTTP/1.1 201 Created44.3.5。批量注册应用程序
一个POST请求/apps允许一次注册多个应用程序。以下主题提供了更多详细信息:
请求结构
POST /apps HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
apps=source.http%3Dmaven%3A%2F%2Forg.springframework.cloud.stream.app%3Ahttp-source-rabbit%3A1.1.0.RELEASE&force=false请求参数
| 范围 | 描述 |
|---|---|
|
可以获取包含注册的属性文件的 URI。与 |
|
内联注册集。与 |
|
如果已经存在同名同类型的注册必须为真,否则会报错 |
示例请求
$ curl 'http://localhost:9393/apps' -i -X POST \
-d 'apps=source.http%3Dmaven%3A%2F%2Forg.springframework.cloud.stream.app%3Ahttp-source-rabbit%3A1.1.0.RELEASE&force=false'响应结构
HTTP/1.1 201 Created
Content-Type: application/hal+json
Content-Length: 658
{
"_embedded" : {
"appRegistrationResourceList" : [ {
"name" : "http",
"type" : "source",
"uri" : "maven://org.springframework.cloud.stream.app:http-source-rabbit:1.1.0.RELEASE",
"version" : "1.1.0.RELEASE",
"defaultVersion" : true,
"versions" : null,
"label" : null,
"_links" : {
"self" : {
"href" : "http://localhost:9393/apps/source/http/1.1.0.RELEASE"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/apps?page=0&size=20"
}
},
"page" : {
"size" : 20,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}44.3.6。设置默认应用程序版本
对于具有相同name和的应用程序type,您可以注册多个版本。在这种情况下,您可以选择其中一个版本作为默认应用程序。
以下主题提供了更多详细信息:
请求结构
PUT /apps/source/http/1.2.0.RELEASE HTTP/1.1
Accept: application/json
Host: localhost:9393路径参数
/apps/{type}/{name}/{version:.+}
| 范围 | 描述 |
|---|---|
|
应用程序的类型。[应用程序,源,处理器,接收器,任务]之一 |
|
应用程序的名称 |
|
应用程序的版本 |
示例请求
$ curl 'http://localhost:9393/apps/source/http/1.2.0.RELEASE' -i -X PUT \
-H 'Accept: application/json'响应结构
HTTP/1.1 202 Accepted44.3.7. 注销应用程序
取消注册以前注册的应用程序的DELETE请求。/apps/<type>/<name>以下主题提供了更多详细信息:
请求结构
DELETE /apps/source/http/1.2.0.RELEASE HTTP/1.1
Host: localhost:9393路径参数
/apps/{type}/{name}/{version}
| 范围 | 描述 |
|---|---|
|
要注销的应用程序类型。[应用程序,源,处理器,接收器,任务]之一 |
|
要注销的应用程序的名称 |
|
要注销的应用程序版本(可选) |
示例请求
$ curl 'http://localhost:9393/apps/source/http/1.2.0.RELEASE' -i -X DELETE响应结构
HTTP/1.1 200 OK44.4. 审计记录
审计记录端点提供有关审计记录的信息。以下主题提供了更多详细信息:
44.4.1. 列出所有审计记录
审计记录端点允许您检索审计跟踪信息。
以下主题提供了更多详细信息:
请求结构
GET /audit-records?page=0&size=10&operations=STREAM&actions=CREATE&fromDate=2000-01-01T00%3A00%3A00&toDate=2099-01-01T00%3A00%3A00 HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
|
逗号分隔的审计操作列表(可选) |
|
逗号分隔的审计操作列表(可选) |
|
从日期过滤器(例如:2019-02-03T00:00:30)(可选) |
|
迄今为止的过滤器(例如:2019-02-03T00:00:30)(可选) |
示例请求
$ curl 'http://localhost:9393/audit-records?page=0&size=10&operations=STREAM&actions=CREATE&fromDate=2000-01-01T00%3A00%3A00&toDate=2099-01-01T00%3A00%3A00' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 680
{
"_embedded" : {
"auditRecordResourceList" : [ {
"auditRecordId" : 5,
"createdBy" : null,
"correlationId" : "timelog",
"auditData" : "time --format='YYYY MM DD' | log",
"createdOn" : "2022-04-05T22:09:10.461Z",
"auditAction" : "CREATE",
"auditOperation" : "STREAM",
"platformName" : null,
"_links" : {
"self" : {
"href" : "http://localhost:9393/audit-records/5"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/audit-records?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}44.4.2. 检索审核记录详细信息
审计记录端点允许您获取单个审计记录。以下主题提供了更多详细信息:
请求结构
GET /audit-records/5 HTTP/1.1
Host: localhost:9393路径参数
/审计记录/{id}
| 范围 | 描述 |
|---|---|
|
要查询的审计记录的id(必填) |
示例请求
$ curl 'http://localhost:9393/audit-records/5' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 354
{
"auditRecordId" : 5,
"createdBy" : null,
"correlationId" : "timelog",
"auditData" : "time --format='YYYY MM DD' | log",
"createdOn" : "2022-04-05T22:09:10.461Z",
"auditAction" : "CREATE",
"auditOperation" : "STREAM",
"platformName" : null,
"_links" : {
"self" : {
"href" : "http://localhost:9393/audit-records/5"
}
}
}44.4.3. 列出所有审计操作类型
审计记录端点允许您获取操作类型。以下主题提供了更多详细信息:
请求结构
GET /audit-records/audit-action-types HTTP/1.1
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/audit-records/audit-action-types' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 1111
[ {
"id" : 100,
"name" : "Create",
"description" : "Create an Entity",
"nameWithDescription" : "Create (Create an Entity)",
"key" : "CREATE"
}, {
"id" : 200,
"name" : "Delete",
"description" : "Delete an Entity",
"nameWithDescription" : "Delete (Delete an Entity)",
"key" : "DELETE"
}, {
"id" : 300,
"name" : "Deploy",
"description" : "Deploy an Entity",
"nameWithDescription" : "Deploy (Deploy an Entity)",
"key" : "DEPLOY"
}, {
"id" : 400,
"name" : "Rollback",
"description" : "Rollback an Entity",
"nameWithDescription" : "Rollback (Rollback an Entity)",
"key" : "ROLLBACK"
}, {
"id" : 500,
"name" : "Undeploy",
"description" : "Undeploy an Entity",
"nameWithDescription" : "Undeploy (Undeploy an Entity)",
"key" : "UNDEPLOY"
}, {
"id" : 600,
"name" : "Update",
"description" : "Update an Entity",
"nameWithDescription" : "Update (Update an Entity)",
"key" : "UPDATE"
}, {
"id" : 700,
"name" : "SuccessfulLogin",
"description" : "Successful login",
"nameWithDescription" : "SuccessfulLogin (Successful login)",
"key" : "LOGIN_SUCCESS"
} ]44.4.4. 列出所有审计操作类型
审计记录端点允许您获取操作类型。以下主题提供了更多详细信息:
请求结构
GET /audit-records/audit-operation-types HTTP/1.1
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/audit-records/audit-operation-types' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 315
[ {
"id" : 100,
"name" : "App Registration",
"key" : "APP_REGISTRATION"
}, {
"id" : 200,
"name" : "Schedule",
"key" : "SCHEDULE"
}, {
"id" : 300,
"name" : "Stream",
"key" : "STREAM"
}, {
"id" : 400,
"name" : "Task",
"key" : "TASK"
}, {
"id" : 500,
"name" : "Login",
"key" : "LOGIN"
} ]44.5。流定义
注册的应用程序端点提供有关向 Spring Cloud Data Flow 服务器注册的流定义的信息。以下主题提供了更多详细信息:
44.5.1。创建新的流定义
创建流定义是通过创建对流定义端点的 POST 请求来实现的。对流的 curl 请求ticktock可能类似于以下内容:
curl -X POST -d "name=ticktock&definition=time | log" localhost:9393/streams/definitions?deploy=false流定义还可以包含其他参数。例如,在“请求结构”下显示的示例中,我们还提供了日期时间格式。
以下主题提供了更多详细信息:
请求结构
POST /streams/definitions HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
name=timelog&definition=time+--format%3D%27YYYY+MM+DD%27+%7C+log&description=Demo+stream+for+testing&deploy=false请求参数
| 范围 | 描述 |
|---|---|
|
创建的任务定义的名称 |
|
流的定义,使用 Data Flow DSL |
|
流定义的描述 |
|
如果为 true,则在创建时部署流(默认为 false) |
示例请求
$ curl 'http://localhost:9393/streams/definitions' -i -X POST \
-d 'name=timelog&definition=time+--format%3D%27YYYY+MM+DD%27+%7C+log&description=Demo+stream+for+testing&deploy=false'响应结构
HTTP/1.1 201 Created
Content-Type: application/hal+json
Content-Length: 410
{
"name" : "timelog",
"dslText" : "time --format='YYYY MM DD' | log",
"originalDslText" : "time --format='YYYY MM DD' | log",
"status" : "undeployed",
"description" : "Demo stream for testing",
"statusDescription" : "The app or group is known to the system, but is not currently deployed",
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions/timelog"
}
}
}44.5.2. 列出所有流定义
流端点允许您列出所有流定义。以下主题提供了更多详细信息:
请求结构
GET /streams/definitions?page=0&sort=name%2CASC&search=&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
对名称执行的搜索字符串(可选) |
|
列表上的排序(可选) |
|
请求的页面大小(可选) |
示例请求
$ curl 'http://localhost:9393/streams/definitions?page=0&sort=name%2CASC&search=&size=10' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 1160
{
"_embedded" : {
"streamDefinitionResourceList" : [ {
"name" : "mysamplestream",
"dslText" : "time | log",
"originalDslText" : "time | log",
"status" : "undeployed",
"description" : "",
"statusDescription" : "The app or group is known to the system, but is not currently deployed",
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions/mysamplestream"
}
}
}, {
"name" : "timelog",
"dslText" : "time --format='YYYY MM DD' | log",
"originalDslText" : "time --format='YYYY MM DD' | log",
"status" : "undeployed",
"description" : "Demo stream for testing",
"statusDescription" : "The app or group is known to the system, but is not currently deployed",
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions/timelog"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions?page=0&size=10&sort=name,asc"
}
},
"page" : {
"size" : 10,
"totalElements" : 2,
"totalPages" : 1,
"number" : 0
}
}44.5.3. 列出相关的流定义
流端点允许您列出相关的流定义。以下主题提供了更多详细信息:
请求结构
GET /streams/definitions/timelog/related?page=0&sort=name%2CASC&search=&size=10&nested=true HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
我们是否应该递归地查找相关流定义的 findByTaskNameContains(可选) |
|
从零开始的页码(可选) |
|
对名称执行的搜索字符串(可选) |
|
列表上的排序(可选) |
|
请求的页面大小(可选) |
示例请求
$ curl 'http://localhost:9393/streams/definitions/timelog/related?page=0&sort=name%2CASC&search=&size=10&nested=true' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 769
{
"_embedded" : {
"streamDefinitionResourceList" : [ {
"name" : "timelog",
"dslText" : "time --format='YYYY MM DD' | log",
"originalDslText" : "time --format='YYYY MM DD' | log",
"status" : "undeployed",
"description" : "Demo stream for testing",
"statusDescription" : "The app or group is known to the system, but is not currently deployed",
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions/timelog"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions/timelog/related?page=0&size=10&sort=name,asc"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}44.5.4. 检索流定义详细信息
流定义端点允许您获取单个流定义。以下主题提供了更多详细信息:
请求结构
GET /streams/definitions/timelog HTTP/1.1
Host: localhost:9393路径参数
/streams/definitions/{名称}
| 范围 | 描述 |
|---|---|
|
要查询的流定义的名称(必填) |
示例请求
$ curl 'http://localhost:9393/streams/definitions/timelog' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 410
{
"name" : "timelog",
"dslText" : "time --format='YYYY MM DD' | log",
"originalDslText" : "time --format='YYYY MM DD' | log",
"status" : "undeployed",
"description" : "Demo stream for testing",
"statusDescription" : "The app or group is known to the system, but is not currently deployed",
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions/timelog"
}
}
}44.5.5。删除单个流定义
流端点允许您删除单个流定义。(另请参阅:删除所有流定义。)以下主题提供了更多详细信息:
请求结构
DELETE /streams/definitions/timelog HTTP/1.1
Host: localhost:9393请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/streams/definitions/timelog' -i -X DELETE响应结构
HTTP/1.1 200 OK44.6。流验证
流验证端点允许您验证流定义中的应用程序。以下主题提供了更多详细信息:
44.6.1。请求结构
GET /streams/validation/timelog HTTP/1.1
Host: localhost:939344.6.2. 路径参数
/streams/validation/{名称}
| 范围 | 描述 |
|---|---|
|
要验证的流定义的名称(必需) |
44.6.3. 示例请求
$ curl 'http://localhost:9393/streams/validation/timelog' -i -X GET44.6.4。响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 197
{
"appName" : "timelog",
"dsl" : "time --format='YYYY MM DD' | log",
"description" : "Demo stream for testing",
"appStatuses" : {
"source:time" : "valid",
"sink:log" : "valid"
}
}44.7。流式部署
部署定义端点提供有关向 Spring Cloud Data Flow 服务器注册的部署的信息。以下主题提供了更多详细信息:
44.7.1。部署流定义
流定义端点允许您部署单个流定义。或者,您可以将应用程序参数作为请求正文中的属性传递。以下主题提供了更多详细信息:
请求结构
POST /streams/deployments/timelog HTTP/1.1
Content-Type: application/json
Content-Length: 36
Host: localhost:9393
{"app.time.timestamp.format":"YYYY"}/streams/deployments/{timelog}
| 范围 | 描述 |
|---|---|
|
现有流定义的名称(必需) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/streams/deployments/timelog' -i -X POST \
-H 'Content-Type: application/json' \
-d '{"app.time.timestamp.format":"YYYY"}'响应结构
HTTP/1.1 201 Created44.7.2. 取消部署流定义
流定义端点允许您取消部署单个流定义。以下主题提供了更多详细信息:
请求结构
DELETE /streams/deployments/timelog HTTP/1.1
Host: localhost:9393/streams/deployments/{timelog}
| 范围 | 描述 |
|---|---|
|
现有流定义的名称(必需) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/streams/deployments/timelog' -i -X DELETE响应结构
HTTP/1.1 200 OK44.7.3. 取消部署所有流定义
流定义端点允许您取消部署所有单个流定义。以下主题提供了更多详细信息:
请求结构
DELETE /streams/deployments HTTP/1.1
Host: localhost:9393请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/streams/deployments' -i -X DELETE响应结构
HTTP/1.1 200 OK44.7.4. 更新已部署的流
感谢 Skipper,您可以更新已部署的流,并提供额外的部署属性。
请求结构
POST /streams/deployments/update/timelog1 HTTP/1.1
Content-Type: application/json
Content-Length: 196
Host: localhost:9393
{"releaseName":"timelog1","packageIdentifier":{"repositoryName":"test","packageName":"timelog1","packageVersion":"1.0.0"},"updateProperties":{"app.time.timestamp.format":"YYYYMMDD"},"force":false}/streams/deployments/update/{timelog1}
| 范围 | 描述 |
|---|---|
|
现有流定义的名称(必需) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/streams/deployments/update/timelog1' -i -X POST \
-H 'Content-Type: application/json' \
-d '{"releaseName":"timelog1","packageIdentifier":{"repositoryName":"test","packageName":"timelog1","packageVersion":"1.0.0"},"updateProperties":{"app.time.timestamp.format":"YYYYMMDD"},"force":false}'响应结构
HTTP/1.1 201 Created44.7.5。回滚流定义
将流回滚到流的先前版本或特定版本。
请求结构
POST /streams/deployments/rollback/timelog1/1 HTTP/1.1
Content-Type: application/json
Host: localhost:9393/streams/deployments/rollback/{name}/{version}
| 范围 | 描述 |
|---|---|
|
现有流定义的名称(必需) |
|
回滚到的版本 |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/streams/deployments/rollback/timelog1/1' -i -X POST \
-H 'Content-Type: application/json'响应结构
HTTP/1.1 201 Created44.7.6。获取清单
返回已发布版本的清单。对于具有依赖项的包,清单包含这些依赖项的内容。
请求结构
GET /streams/deployments/manifest/timelog1/1 HTTP/1.1
Content-Type: application/json
Host: localhost:9393/streams/deployments/manifest/{name}/{version}
| 范围 | 描述 |
|---|---|
|
现有流定义的名称(必需) |
|
流的版本 |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/streams/deployments/manifest/timelog1/1' -i -X GET \
-H 'Content-Type: application/json'响应结构
HTTP/1.1 200 OK44.7.7。获取部署历史
获取流的部署历史记录。
请求结构
GET /streams/deployments/history/timelog1 HTTP/1.1
Content-Type: application/json
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/streams/deployments/history/timelog1' -i -X GET \
-H 'Content-Type: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 162
[ {
"name" : null,
"version" : 0,
"info" : null,
"pkg" : null,
"configValues" : {
"raw" : null
},
"manifest" : null,
"platformName" : null
} ]44.7.8。获取部署平台
检索支持的部署平台列表。
请求结构
GET /streams/deployments/platform/list HTTP/1.1
Content-Type: application/json
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/streams/deployments/platform/list' -i -X GET \
-H 'Content-Type: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 106
[ {
"id" : null,
"name" : "default",
"type" : "local",
"description" : null,
"options" : [ ]
} ]44.7.9。比例流定义
流定义端点允许您在流定义中缩放单个应用程序。或者,您可以将应用程序参数作为请求正文中的属性传递。以下主题提供了更多详细信息:
请求结构
POST /streams/deployments/scale/timelog/log/instances/1 HTTP/1.1
Content-Type: application/json
Content-Length: 36
Host: localhost:9393
{"app.time.timestamp.format":"YYYY"}/streams/deployments/scale/{streamName}/{appName}/instances/{count}
| 范围 | 描述 |
|---|---|
|
现有流定义的名称(必需) |
|
在流应用程序名称中进行缩放 |
|
所选流应用程序的实例数(必需) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/streams/deployments/scale/timelog/log/instances/1' -i -X POST \
-H 'Content-Type: application/json' \
-d '{"app.time.timestamp.format":"YYYY"}'响应结构
HTTP/1.1 201 Created44.8。任务定义
任务定义端点提供有关向 Spring Cloud Data Flow 服务器注册的任务定义的信息。以下主题提供了更多详细信息:
44.8.1。创建新任务定义
任务定义端点允许您创建新的任务定义。以下主题提供了更多详细信息:
请求结构
POST /tasks/definitions HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
name=my-task&definition=timestamp+--format%3D%27YYYY+MM+DD%27&description=Demo+task+definition+for+testing请求参数
| 范围 | 描述 |
|---|---|
|
创建的任务定义的名称 |
|
任务的定义,使用 Data Flow DSL |
|
任务定义说明 |
示例请求
$ curl 'http://localhost:9393/tasks/definitions' -i -X POST \
-d 'name=my-task&definition=timestamp+--format%3D%27YYYY+MM+DD%27&description=Demo+task+definition+for+testing'响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 342
{
"name" : "my-task",
"dslText" : "timestamp --format='YYYY MM DD'",
"description" : "Demo task definition for testing",
"composed" : false,
"composedTaskElement" : false,
"lastTaskExecution" : null,
"status" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/definitions/my-task"
}
}
}44.8.2. 列出所有任务定义
任务定义端点允许您获取所有任务定义。以下主题提供了更多详细信息:
请求结构
GET /tasks/definitions?page=0&size=10&sort=taskName%2CASC&search=&manifest=true HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
|
对名称执行的搜索字符串(可选) |
|
列表上的排序(可选) |
|
将任务清单包含到最新任务执行中的标志(可选) |
示例请求
$ curl 'http://localhost:9393/tasks/definitions?page=0&size=10&sort=taskName%2CASC&search=&manifest=true' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 689
{
"_embedded" : {
"taskDefinitionResourceList" : [ {
"name" : "my-task",
"dslText" : "timestamp --format='YYYY MM DD'",
"description" : "Demo task definition for testing",
"composed" : false,
"composedTaskElement" : false,
"lastTaskExecution" : null,
"status" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/definitions/my-task"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/definitions?page=0&size=10&sort=taskName,asc"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}44.8.3. 检索任务定义详细信息
任务定义端点允许您获取单个任务定义。以下主题提供了更多详细信息:
请求结构
GET /tasks/definitions/my-task?manifest=true HTTP/1.1
Host: localhost:9393/tasks/definitions/{我的任务}
| 范围 | 描述 |
|---|---|
|
现有任务定义的名称(必填) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/tasks/definitions/my-task?manifest=true' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 342
{
"name" : "my-task",
"dslText" : "timestamp --format='YYYY MM DD'",
"description" : "Demo task definition for testing",
"composed" : false,
"composedTaskElement" : false,
"lastTaskExecution" : null,
"status" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/definitions/my-task"
}
}
}44.8.4。删除任务定义
任务定义端点允许您删除单个任务定义。以下主题提供了更多详细信息:
请求结构
DELETE /tasks/definitions/my-task?cleanup=true HTTP/1.1
Host: localhost:9393/tasks/definitions/{我的任务}
| 范围 | 描述 |
|---|---|
|
现有任务定义的名称(必填) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/tasks/definitions/my-task?cleanup=true' -i -X DELETE响应结构
HTTP/1.1 200 OK44.9。任务计划程序
任务调度程序端点提供有关向调度程序实现注册的任务调度的信息。以下主题提供了更多详细信息:
44.9.1。创建新的任务计划
任务计划端点允许您创建新的任务计划。以下主题提供了更多详细信息:
请求结构
POST /tasks/schedules HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
scheduleName=myschedule&taskDefinitionName=mytaskname&properties=scheduler.cron.expression%3D00+22+17+%3F+*&arguments=--foo%3Dbar请求参数
| 范围 | 描述 |
|---|---|
|
创建的计划的名称 |
|
要计划的任务定义的名称 |
|
计划和启动任务所需的属性 |
|
用于启动任务的命令行参数 |
示例请求
$ curl 'http://localhost:9393/tasks/schedules' -i -X POST \
-d 'scheduleName=myschedule&taskDefinitionName=mytaskname&properties=scheduler.cron.expression%3D00+22+17+%3F+*&arguments=--foo%3Dbar'响应结构
HTTP/1.1 201 Created44.9.2. 列出所有时间表
任务计划端点可让您获取所有任务计划。以下主题提供了更多详细信息:
请求结构
GET /tasks/schedules?page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
示例请求
$ curl 'http://localhost:9393/tasks/schedules?page=0&size=10' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 587
{
"_embedded" : {
"scheduleInfoResourceList" : [ {
"scheduleName" : "FOO",
"taskDefinitionName" : "BAR",
"scheduleProperties" : {
"scheduler.AAA.spring.cloud.scheduler.cron.expression" : "00 41 17 ? * *"
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/schedules/FOO"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/schedules?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}44.9.3. 列出过滤的时间表
任务计划端点允许您获取具有指定任务定义名称的所有任务计划。以下主题提供了更多详细信息:
请求结构
GET /tasks/schedules/instances/FOO?page=0&size=10 HTTP/1.1
Host: localhost:9393/tasks/schedules/instances/{任务定义名称}
| 范围 | 描述 |
|---|---|
|
根据指定的任务定义过滤计划(必需) |
请求参数
| 范围 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
示例请求
$ curl 'http://localhost:9393/tasks/schedules/instances/FOO?page=0&size=10' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 599
{
"_embedded" : {
"scheduleInfoResourceList" : [ {
"scheduleName" : "FOO",
"taskDefinitionName" : "BAR",
"scheduleProperties" : {
"scheduler.AAA.spring.cloud.scheduler.cron.expression" : "00 41 17 ? * *"
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/schedules/FOO"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/schedules/instances/FOO?page=0&size=1"
}
},
"page" : {
"size" : 1,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}44.9.4。删除任务计划
任务计划端点允许您删除单个任务计划。以下主题提供了更多详细信息:
请求结构
DELETE /tasks/schedules/mytestschedule HTTP/1.1
Host: localhost:9393/tasks/schedules/{scheduleName}
| 范围 | 描述 |
|---|---|
|
现有计划的名称(必填) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/tasks/schedules/mytestschedule' -i -X DELETE响应结构
HTTP/1.1 200 OK44.10。任务验证
任务验证端点允许您验证任务定义中的应用程序。以下主题提供了更多详细信息:
44.10.1。请求结构
GET /tasks/validation/taskC HTTP/1.1
Host: localhost:939344.10.2。路径参数
/tasks/validation/{名称}
| 范围 | 描述 |
|---|---|
|
要验证的任务定义的名称(必填) |
44.10.3。示例请求
$ curl 'http://localhost:9393/tasks/validation/taskC' -i -X GET44.10.4。响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 144
{
"appName" : "taskC",
"dsl" : "timestamp --format='yyyy MM dd'",
"description" : "",
"appStatuses" : {
"task:taskC" : "valid"
}
}44.11。任务执行
任务执行端点提供有关向 Spring Cloud Data Flow 服务器注册的任务执行的信息。以下主题提供了更多详细信息:
44.11.1。启动任务
启动任务是通过请求创建新的任务执行来完成的。以下主题提供了更多详细信息:
请求结构
POST /tasks/executions HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
name=taskA&properties=app.my-task.foo%3Dbar%2Cdeployer.my-task.something-else%3D3&arguments=--server.port%3D8080+--foo%3Dbar请求参数
| 范围 | 描述 |
|---|---|
|
要启动的任务定义的名称 |
|
启动时使用的应用程序和部署程序属性 |
|
传递给任务的命令行参数 |
示例请求
$ curl 'http://localhost:9393/tasks/executions' -i -X POST \
-d 'name=taskA&properties=app.my-task.foo%3Dbar%2Cdeployer.my-task.something-else%3D3&arguments=--server.port%3D8080+--foo%3Dbar'响应结构
HTTP/1.1 201 Created
Content-Type: application/json
Content-Length: 1
144.11.2。停止任务
通过发布现有任务执行的 id 来停止任务。以下主题提供了更多详细信息:
请求结构
POST /tasks/executions/1 HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
platform=default路径参数
/tasks/executions/{id}
| 范围 | 描述 |
|---|---|
|
现有任务执行的 ID(必需) |
请求参数
| 范围 | 描述 |
|---|---|
|
与任务执行关联的平台(可选) |
示例请求
$ curl 'http://localhost:9393/tasks/executions/1' -i -X POST \
-d 'platform=default'响应结构
HTTP/1.1 200 OK44.11.3。列出所有任务执行
任务执行端点允许您列出所有任务执行。以下主题提供了更多详细信息:
请求结构
GET /tasks/executions?page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
示例请求
$ curl 'http://localhost:9393/tasks/executions?page=0&size=10' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 2711
{
"_embedded" : {
"taskExecutionResourceList" : [ {
"executionId" : 2,
"exitCode" : null,
"taskName" : "taskB",
"startTime" : null,
"endTime" : null,
"exitMessage" : null,
"arguments" : [ ],
"jobExecutionIds" : [ ],
"errorMessage" : null,
"externalExecutionId" : "taskB-e5964e65-faea-4135-b54f-643e51cc1ce4",
"parentExecutionId" : null,
"resourceUrl" : "org.springframework.cloud.task.app:timestamp-task:jar:1.2.0.RELEASE",
"appProperties" : {
"management.metrics.tags.service" : "task-application",
"timestamp.format" : "yyyy MM dd",
"spring.datasource.username" : null,
"spring.datasource.url" : null,
"spring.datasource.driverClassName" : null,
"management.metrics.tags.application" : "${spring.cloud.task.name:unknown}-${spring.cloud.task.executionid:unknown}",
"spring.cloud.task.name" : "taskB"
},
"deploymentProperties" : {
"app.my-task.foo" : "bar",
"deployer.my-task.something-else" : "3"
},
"platformName" : "default",
"taskExecutionStatus" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/executions/2"
}
}
}, {
"executionId" : 1,
"exitCode" : null,
"taskName" : "taskA",
"startTime" : null,
"endTime" : null,
"exitMessage" : null,
"arguments" : [ ],
"jobExecutionIds" : [ ],
"errorMessage" : null,
"externalExecutionId" : "taskA-e336a64c-8ac6-4881-8743-741bd724ed01",
"parentExecutionId" : null,
"resourceUrl" : "org.springframework.cloud.task.app:timestamp-task:jar:1.2.0.RELEASE",
"appProperties" : {
"management.metrics.tags.service" : "task-application",
"timestamp.format" : "yyyy MM dd",
"spring.datasource.username" : null,
"spring.datasource.url" : null,
"spring.datasource.driverClassName" : null,
"management.metrics.tags.application" : "${spring.cloud.task.name:unknown}-${spring.cloud.task.executionid:unknown}",
"spring.cloud.task.name" : "taskA"
},
"deploymentProperties" : {
"app.my-task.foo" : "bar",
"deployer.my-task.something-else" : "3"
},
"platformName" : "default",
"taskExecutionStatus" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/executions/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/executions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 2,
"totalPages" : 1,
"number" : 0
}
}44.11.4。列出具有指定任务名称的所有任务执行
任务执行端点允许您列出具有指定任务名称的任务执行。以下主题提供了更多详细信息:
请求结构
GET /tasks/executions?name=taskB&page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
|
与任务执行关联的名称 |
示例请求
$ curl 'http://localhost:9393/tasks/executions?name=taskB&page=0&size=10' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 1492
{
"_embedded" : {
"taskExecutionResourceList" : [ {
"executionId" : 2,
"exitCode" : null,
"taskName" : "taskB",
"startTime" : null,
"endTime" : null,
"exitMessage" : null,
"arguments" : [ ],
"jobExecutionIds" : [ ],
"errorMessage" : null,
"externalExecutionId" : "taskB-e5964e65-faea-4135-b54f-643e51cc1ce4",
"parentExecutionId" : null,
"resourceUrl" : "org.springframework.cloud.task.app:timestamp-task:jar:1.2.0.RELEASE",
"appProperties" : {
"management.metrics.tags.service" : "task-application",
"timestamp.format" : "yyyy MM dd",
"spring.datasource.username" : null,
"spring.datasource.url" : null,
"spring.datasource.driverClassName" : null,
"management.metrics.tags.application" : "${spring.cloud.task.name:unknown}-${spring.cloud.task.executionid:unknown}",
"spring.cloud.task.name" : "taskB"
},
"deploymentProperties" : {
"app.my-task.foo" : "bar",
"deployer.my-task.something-else" : "3"
},
"platformName" : "default",
"taskExecutionStatus" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/executions/2"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/executions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}44.11.5。任务执行细节
任务执行端点可让您获取有关任务执行的详细信息。以下主题提供了更多详细信息:
请求结构
GET /tasks/executions/1 HTTP/1.1
Host: localhost:9393/tasks/executions/{id}
| 范围 | 描述 |
|---|---|
|
现有任务执行的 id(必需) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/tasks/executions/1' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 1085
{
"executionId" : 1,
"exitCode" : null,
"taskName" : "taskA",
"startTime" : null,
"endTime" : null,
"exitMessage" : null,
"arguments" : [ ],
"jobExecutionIds" : [ ],
"errorMessage" : null,
"externalExecutionId" : "taskA-e336a64c-8ac6-4881-8743-741bd724ed01",
"parentExecutionId" : null,
"resourceUrl" : "org.springframework.cloud.task.app:timestamp-task:jar:1.2.0.RELEASE",
"appProperties" : {
"management.metrics.tags.service" : "task-application",
"timestamp.format" : "yyyy MM dd",
"spring.datasource.username" : null,
"spring.datasource.url" : null,
"spring.datasource.driverClassName" : null,
"management.metrics.tags.application" : "${spring.cloud.task.name:unknown}-${spring.cloud.task.executionid:unknown}",
"spring.cloud.task.name" : "taskA"
},
"deploymentProperties" : {
"app.my-task.foo" : "bar",
"deployer.my-task.something-else" : "3"
},
"platformName" : "default",
"taskExecutionStatus" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/executions/1"
}
}
}44.11.6。删除任务执行
任务执行端点允许您:
-
清理用于部署任务的资源
-
从持久性存储中删除相关的任务数据以及可能关联的 Spring Batch 作业数据
| 清理实现(第一个选项)是特定于平台的。这两个操作可以同时触发,也可以分别触发。 |
以下主题提供了更多详细信息:
有关删除任务执行数据,请参阅以下部分。
请求结构
DELETE /tasks/executions/1,2?action=CLEANUP,REMOVE_DATA HTTP/1.1
Host: localhost:9393/tasks/executions/{ids}
| 范围 | 描述 |
|---|---|
|
提供 2 个逗号分隔的任务执行 ID 值。 |
|
您必须提供实际存在的任务执行 ID。否则, |
请求参数
此端点支持一个名为action的可选请求参数。它是一个枚举并支持以下值:
-
清理
-
REMOVE_DATA
| 范围 | 描述 |
|---|---|
|
同时使用两个动作 CLEANUP 和 REMOVE_DATA。 |
示例请求
$ curl 'http://localhost:9393/tasks/executions/1,2?action=CLEANUP,REMOVE_DATA' -i -X DELETE响应结构
HTTP/1.1 200 OK44.11.7。删除任务执行数据
您不仅可以清理用于部署任务的资源,还可以从底层持久性存储中删除与任务执行相关的数据。此外,如果任务执行与一个或多个批处理作业执行相关联,则这些也将被删除。
以下示例说明了如何使用多个任务执行 ID 和多个操作发出请求:
$ curl 'http://localhost:9393/tasks/executions/1,2?action=CLEANUP,REMOVE_DATA' -i -X DELETE/tasks/executions/{ids}
| 范围 | 描述 |
|---|---|
|
提供 2 个逗号分隔的任务执行 ID 值。 |
| 范围 | 描述 |
|---|---|
|
同时使用两个动作 CLEANUP 和 REMOVE_DATA。 |
使用REMOVE_DATAaction 参数从持久存储中删除数据时,您必须提供代表父任务执行的任务执行 ID。当您提供子任务执行(作为组合任务的一部分执行)时,将400返回(错误请求)HTTP 状态。
|
当删除大量任务执行时,某些数据库类型会限制IN子句中的条目数(Spring Cloud Data Flow 用于删除任务执行关系的方法)。Spring Cloud Data Flow 支持 Sql Server(最多 2100 个条目)和 Oracle DB(最多 1000 个条目)的删除分块。但是,Spring Cloud Data Flow 允许用户设置自己的分块因子。为此,请将spring.cloud.dataflow.task.executionDeleteChunkSize属性设置为适当的块大小。默认是0这意味着 Spring Cloud Data Flow 不会分块执行删除的任务(Oracle 和 Sql Server 数据库除外)。
|
44.11.8。任务执行当前计数
任务执行当前端点允许您检索当前正在运行的执行次数。以下主题提供了更多详细信息:
请求结构
api-guide.adoc 中未解析的指令 - 包括::/home/runner/work/spring-cloud-dataflow/spring-cloud-dataflow/spring-cloud-dataflow-docs/../spring-cloud-dataflow-classic- docs/target/generated-snippets/task-executions-documentation/launch-task-current-count/http-request.adoc[]
请求参数
此端点没有请求参数。
示例请求
api-guide.adoc 中未解析的指令 - 包括::/home/runner/work/spring-cloud-dataflow/spring-cloud-dataflow/spring-cloud-dataflow-docs/../spring-cloud-dataflow-classic- docs/target/generated-snippets/task-executions-documentation/launch-task-current-count/curl-request.adoc[]
响应结构
api-guide.adoc 中未解析的指令 - 包括::/home/runner/work/spring-cloud-dataflow/spring-cloud-dataflow/spring-cloud-dataflow-docs/../spring-cloud-dataflow-classic- docs/target/generated-snippets/task-executions-documentation/launch-task-current-count/http-response.adoc[]
44.12。作业执行
作业执行端点提供有关向 Spring Cloud Data Flow 服务器注册的作业执行的信息。以下主题提供了更多详细信息:
44.12.1。列出所有作业执行
作业执行端点允许您列出所有作业执行。以下主题提供了更多详细信息:
请求结构
GET /jobs/executions?page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
示例请求
$ curl 'http://localhost:9393/jobs/executions?page=0&size=10' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 3066
{
"_embedded" : {
"jobExecutionResourceList" : [ {
"executionId" : 2,
"stepExecutionCount" : 0,
"jobId" : 2,
"taskExecutionId" : 2,
"name" : "DOCJOB1",
"startDate" : "2022-04-05",
"startTime" : "22:09:55",
"duration" : "00:00:00",
"jobExecution" : {
"id" : 2,
"version" : 1,
"jobParameters" : {
"parameters" : { }
},
"jobInstance" : {
"id" : 2,
"jobName" : "DOCJOB1",
"version" : null
},
"stepExecutions" : [ ],
"status" : "STOPPED",
"startTime" : "2022-04-05T22:09:55.794+0000",
"createTime" : "2022-04-05T22:09:55.794+0000",
"endTime" : null,
"lastUpdated" : "2022-04-05T22:09:55.794+0000",
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : ""
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"failureExceptions" : [ ],
"jobConfigurationName" : null,
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : true,
"abandonable" : true,
"stoppable" : false,
"defined" : true,
"timeZone" : "UTC",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/2"
}
}
}, {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"name" : "DOCJOB",
"startDate" : "2022-04-05",
"startTime" : "22:09:55",
"duration" : "00:00:00",
"jobExecution" : {
"id" : 1,
"version" : 2,
"jobParameters" : {
"parameters" : { }
},
"jobInstance" : {
"id" : 1,
"jobName" : "DOCJOB",
"version" : null
},
"stepExecutions" : [ ],
"status" : "STOPPING",
"startTime" : "2022-04-05T22:09:55.790+0000",
"createTime" : "2022-04-05T22:09:55.789+0000",
"endTime" : null,
"lastUpdated" : "2022-04-05T22:09:55.911+0000",
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : ""
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"failureExceptions" : [ ],
"jobConfigurationName" : null,
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : true,
"stoppable" : false,
"defined" : false,
"timeZone" : "UTC",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 2,
"totalPages" : 1,
"number" : 0
}
}44.12.2。列出所有不包括步骤执行的作业执行
作业执行端点允许您列出所有作业执行,但不包括步骤执行。以下主题提供了更多详细信息:
请求结构
GET /jobs/thinexecutions?page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
示例请求
$ curl 'http://localhost:9393/jobs/thinexecutions?page=0&size=10' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 1604
{
"_embedded" : {
"jobExecutionThinResourceList" : [ {
"executionId" : 2,
"stepExecutionCount" : 0,
"jobId" : 2,
"taskExecutionId" : 2,
"instanceId" : 2,
"name" : "DOCJOB1",
"startDate" : "2022-04-05",
"startTime" : "22:09:55",
"startDateTime" : "2022-04-05T22:09:55.794+0000",
"duration" : "00:00:00",
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : true,
"abandonable" : true,
"stoppable" : false,
"defined" : true,
"timeZone" : "UTC",
"status" : "STOPPED",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions/2"
}
}
}, {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"instanceId" : 1,
"name" : "DOCJOB",
"startDate" : "2022-04-05",
"startTime" : "22:09:55",
"startDateTime" : "2022-04-05T22:09:55.790+0000",
"duration" : "00:00:00",
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : false,
"stoppable" : true,
"defined" : false,
"timeZone" : "UTC",
"status" : "STARTED",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 2,
"totalPages" : 1,
"number" : 0
}
}44.12.3。列出具有指定作业名称的所有作业执行
作业执行端点允许您列出所有作业执行。以下主题提供了更多详细信息:
请求结构
GET /jobs/executions?name=DOCJOB&page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
|
与作业执行关联的名称 |
示例请求
$ curl 'http://localhost:9393/jobs/executions?name=DOCJOB&page=0&size=10' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 1669
{
"_embedded" : {
"jobExecutionResourceList" : [ {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"name" : "DOCJOB",
"startDate" : "2022-04-05",
"startTime" : "22:09:55",
"duration" : "00:00:00",
"jobExecution" : {
"id" : 1,
"version" : 2,
"jobParameters" : {
"parameters" : { }
},
"jobInstance" : {
"id" : 1,
"jobName" : "DOCJOB",
"version" : null
},
"stepExecutions" : [ ],
"status" : "STOPPING",
"startTime" : "2022-04-05T22:09:55.790+0000",
"createTime" : "2022-04-05T22:09:55.789+0000",
"endTime" : null,
"lastUpdated" : "2022-04-05T22:09:55.911+0000",
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : ""
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"failureExceptions" : [ ],
"jobConfigurationName" : null,
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : true,
"stoppable" : false,
"defined" : false,
"timeZone" : "UTC",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}44.12.4。列出具有指定作业名称的所有作业执行,但不包括步骤执行
作业执行端点允许您列出所有作业执行。以下主题提供了更多详细信息:
请求结构
GET /jobs/thinexecutions?name=DOCJOB&page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
|
与作业执行关联的名称 |
示例请求
$ curl 'http://localhost:9393/jobs/thinexecutions?name=DOCJOB&page=0&size=10' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 943
{
"_embedded" : {
"jobExecutionThinResourceList" : [ {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"instanceId" : 1,
"name" : "DOCJOB",
"startDate" : "2022-04-05",
"startTime" : "22:09:55",
"startDateTime" : "2022-04-05T22:09:55.790+0000",
"duration" : "00:00:00",
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : true,
"stoppable" : false,
"defined" : false,
"timeZone" : "UTC",
"status" : "STOPPING",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}44.12.5。列出指定日期范围内的所有作业执行,不包括步骤执行
作业执行端点允许您列出所有作业执行。以下主题提供了更多详细信息:
请求结构
GET /jobs/thinexecutions?page=0&size=10&fromDate=2000-09-24T17%3A00%3A45%2C000&toDate=2050-09-24T18%3A00%3A45%2C000 HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
|
从开始日期过滤结果,格式为 'yyyy-MM-dd'T'HH:mm:ss,SSS' |
|
|
示例请求
$ curl 'http://localhost:9393/jobs/thinexecutions?page=0&size=10&fromDate=2000-09-24T17%3A00%3A45%2C000&toDate=2050-09-24T18%3A00%3A45%2C000' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 1605
{
"_embedded" : {
"jobExecutionThinResourceList" : [ {
"executionId" : 2,
"stepExecutionCount" : 0,
"jobId" : 2,
"taskExecutionId" : 2,
"instanceId" : 2,
"name" : "DOCJOB1",
"startDate" : "2022-04-05",
"startTime" : "22:09:55",
"startDateTime" : "2022-04-05T22:09:55.794+0000",
"duration" : "00:00:00",
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : true,
"abandonable" : true,
"stoppable" : false,
"defined" : true,
"timeZone" : "UTC",
"status" : "STOPPED",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions/2"
}
}
}, {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"instanceId" : 1,
"name" : "DOCJOB",
"startDate" : "2022-04-05",
"startTime" : "22:09:55",
"startDateTime" : "2022-04-05T22:09:55.790+0000",
"duration" : "00:00:00",
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : true,
"stoppable" : false,
"defined" : false,
"timeZone" : "UTC",
"status" : "STOPPING",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 2,
"totalPages" : 1,
"number" : 0
}
}44.12.6。列出指定作业实例 ID 的所有作业执行,不包括步骤执行
作业执行端点允许您列出所有作业执行。以下主题提供了更多详细信息:
请求结构
GET /jobs/thinexecutions?page=0&size=10&jobInstanceId=1 HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
|
按作业实例 ID 过滤结果 |
示例请求
$ curl 'http://localhost:9393/jobs/thinexecutions?page=0&size=10&jobInstanceId=1' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 943
{
"_embedded" : {
"jobExecutionThinResourceList" : [ {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"instanceId" : 1,
"name" : "DOCJOB",
"startDate" : "2022-04-05",
"startTime" : "22:09:55",
"startDateTime" : "2022-04-05T22:09:55.790+0000",
"duration" : "00:00:00",
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : true,
"stoppable" : false,
"defined" : false,
"timeZone" : "UTC",
"status" : "STOPPING",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}44.12.7。列出指定任务执行 ID 的所有作业执行,不包括步骤执行
作业执行端点允许您列出所有作业执行。以下主题提供了更多详细信息:
请求结构
GET /jobs/thinexecutions?page=0&size=10&taskExecutionId=1 HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
|
按任务执行id过滤结果 |
示例请求
$ curl 'http://localhost:9393/jobs/thinexecutions?page=0&size=10&taskExecutionId=1' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 943
{
"_embedded" : {
"jobExecutionThinResourceList" : [ {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"instanceId" : 1,
"name" : "DOCJOB",
"startDate" : "2022-04-05",
"startTime" : "22:09:55",
"startDateTime" : "2022-04-05T22:09:55.790+0000",
"duration" : "00:00:00",
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : true,
"stoppable" : false,
"defined" : false,
"timeZone" : "UTC",
"status" : "STOPPING",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}44.12.8。作业执行详情
作业执行端点可让您获取有关作业执行的详细信息。以下主题提供了更多详细信息:
请求结构
GET /jobs/executions/2 HTTP/1.1
Host: localhost:9393/jobs/executions/{id}
| 范围 | 描述 |
|---|---|
|
现有作业执行的 ID(必需) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/jobs/executions/2' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 1188
{
"executionId" : 2,
"stepExecutionCount" : 0,
"jobId" : 2,
"taskExecutionId" : 2,
"name" : "DOCJOB1",
"startDate" : "2022-04-05",
"startTime" : "22:09:55",
"duration" : "00:00:00",
"jobExecution" : {
"id" : 2,
"version" : 1,
"jobParameters" : {
"parameters" : { }
},
"jobInstance" : {
"id" : 2,
"jobName" : "DOCJOB1",
"version" : 0
},
"stepExecutions" : [ ],
"status" : "STOPPED",
"startTime" : "2022-04-05T22:09:55.794+0000",
"createTime" : "2022-04-05T22:09:55.794+0000",
"endTime" : null,
"lastUpdated" : "2022-04-05T22:09:55.794+0000",
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : ""
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"failureExceptions" : [ ],
"jobConfigurationName" : null,
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : true,
"abandonable" : true,
"stoppable" : false,
"defined" : true,
"timeZone" : "UTC",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/2"
}
}
}44.12.9。停止作业执行
作业执行端点允许您停止作业执行。以下主题提供了更多详细信息:
请求结构
PUT /jobs/executions/1 HTTP/1.1
Accept: application/json
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
stop=true/jobs/executions/{id}
| 范围 | 描述 |
|---|---|
|
现有作业执行的 ID(必需) |
请求参数
| 范围 | 描述 |
|---|---|
|
如果设置为 true,则发送信号以停止作业 |
示例请求
$ curl 'http://localhost:9393/jobs/executions/1' -i -X PUT \
-H 'Accept: application/json' \
-d 'stop=true'响应结构
HTTP/1.1 200 OK10 年 12 月 44 日。重新启动作业执行
作业执行端点允许您重新启动作业执行。以下主题提供了更多详细信息:
请求结构
PUT /jobs/executions/2 HTTP/1.1
Accept: application/json
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
restart=true/jobs/executions/{id}
| 范围 | 描述 |
|---|---|
|
现有作业执行的 ID(必需) |
请求参数
| 范围 | 描述 |
|---|---|
|
如果设置为 true,则发送信号以重新启动作业 |
示例请求
$ curl 'http://localhost:9393/jobs/executions/2' -i -X PUT \
-H 'Accept: application/json' \
-d 'restart=true'响应结构
HTTP/1.1 200 OK44.13。作业实例
作业实例端点提供有关向 Spring Cloud Data Flow 服务器注册的作业实例的信息。以下主题提供了更多详细信息:
44.13.1。列出所有作业实例
作业实例端点允许您列出所有作业实例。以下主题提供了更多详细信息:
请求结构
GET /jobs/instances?name=DOCJOB&page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
|
与作业实例关联的名称 |
示例请求
$ curl 'http://localhost:9393/jobs/instances?name=DOCJOB&page=0&size=10' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 1845
{
"_embedded" : {
"jobInstanceResourceList" : [ {
"jobName" : "DOCJOB",
"jobInstanceId" : 1,
"jobExecutions" : [ {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"name" : "DOCJOB",
"startDate" : "2022-04-05",
"startTime" : "22:09:04",
"duration" : "00:00:00",
"jobExecution" : {
"id" : 1,
"version" : 1,
"jobParameters" : {
"parameters" : { }
},
"jobInstance" : {
"id" : 1,
"jobName" : "DOCJOB",
"version" : 0
},
"stepExecutions" : [ ],
"status" : "STARTED",
"startTime" : "2022-04-05T22:09:04.943+0000",
"createTime" : "2022-04-05T22:09:04.921+0000",
"endTime" : null,
"lastUpdated" : "2022-04-05T22:09:04.943+0000",
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : ""
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"failureExceptions" : [ ],
"jobConfigurationName" : null,
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : false,
"stoppable" : true,
"defined" : false,
"timeZone" : "UTC"
} ],
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/instances/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/instances?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}44.13.2。作业实例详细信息
作业实例端点允许您列出所有作业实例。以下主题提供了更多详细信息:
请求结构
GET /jobs/instances/1 HTTP/1.1
Host: localhost:9393/jobs/instances/{id}
| 范围 | 描述 |
|---|---|
|
现有作业实例的 ID(必填) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/jobs/instances/1' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 1354
{
"jobName" : "DOCJOB",
"jobInstanceId" : 1,
"jobExecutions" : [ {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"name" : "DOCJOB",
"startDate" : "2022-04-05",
"startTime" : "22:09:04",
"duration" : "00:00:00",
"jobExecution" : {
"id" : 1,
"version" : 1,
"jobParameters" : {
"parameters" : { }
},
"jobInstance" : {
"id" : 1,
"jobName" : "DOCJOB",
"version" : 0
},
"stepExecutions" : [ ],
"status" : "STARTED",
"startTime" : "2022-04-05T22:09:04.943+0000",
"createTime" : "2022-04-05T22:09:04.921+0000",
"endTime" : null,
"lastUpdated" : "2022-04-05T22:09:04.943+0000",
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : ""
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"failureExceptions" : [ ],
"jobConfigurationName" : null,
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : false,
"stoppable" : true,
"defined" : false,
"timeZone" : "UTC"
} ],
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/instances/1"
}
}
}44.14。作业步骤执行
作业步骤执行端点提供有关向 Spring Cloud Data Flow 服务器注册的作业步骤执行的信息。以下主题提供了更多详细信息:
44.14.1。列出作业执行的所有步骤执行
作业步骤执行端点允许您列出所有作业步骤执行。以下主题提供了更多详细信息:
请求结构
GET /jobs/executions/1/steps?page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
示例请求
$ curl 'http://localhost:9393/jobs/executions/1/steps?page=0&size=10' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 1623
{
"_embedded" : {
"stepExecutionResourceList" : [ {
"jobExecutionId" : 1,
"stepExecution" : {
"stepName" : "DOCJOB_STEP",
"id" : 1,
"version" : 0,
"status" : "STARTING",
"readCount" : 0,
"writeCount" : 0,
"commitCount" : 0,
"rollbackCount" : 0,
"readSkipCount" : 0,
"processSkipCount" : 0,
"writeSkipCount" : 0,
"startTime" : "2022-04-05T22:10:00.667+0000",
"endTime" : null,
"lastUpdated" : "2022-04-05T22:10:00.667+0000",
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"exitStatus" : {
"exitCode" : "EXECUTING",
"exitDescription" : ""
},
"terminateOnly" : false,
"filterCount" : 0,
"failureExceptions" : [ ],
"jobParameters" : {
"parameters" : { }
},
"jobExecutionId" : 1,
"skipCount" : 0,
"summary" : "StepExecution: id=1, version=0, name=DOCJOB_STEP, status=STARTING, exitStatus=EXECUTING, readCount=0, filterCount=0, writeCount=0 readSkipCount=0, writeSkipCount=0, processSkipCount=0, commitCount=0, rollbackCount=0"
},
"stepType" : "",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1/steps/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1/steps?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}44.14.2。作业步骤执行详细信息
作业步骤执行端点可让您获取有关作业步骤执行的详细信息。以下主题提供了更多详细信息:
请求结构
GET /jobs/executions/1/steps/1 HTTP/1.1
Host: localhost:9393/jobs/executions/{id}/steps/{stepid}
| 范围 | 描述 |
|---|---|
|
现有作业执行的 ID(必需) |
|
特定作业执行的现有步骤执行的 ID(必需) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/jobs/executions/1/steps/1' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 1173
{
"jobExecutionId" : 1,
"stepExecution" : {
"stepName" : "DOCJOB_STEP",
"id" : 1,
"version" : 0,
"status" : "STARTING",
"readCount" : 0,
"writeCount" : 0,
"commitCount" : 0,
"rollbackCount" : 0,
"readSkipCount" : 0,
"processSkipCount" : 0,
"writeSkipCount" : 0,
"startTime" : "2022-04-05T22:10:00.667+0000",
"endTime" : null,
"lastUpdated" : "2022-04-05T22:10:00.667+0000",
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"exitStatus" : {
"exitCode" : "EXECUTING",
"exitDescription" : ""
},
"terminateOnly" : false,
"filterCount" : 0,
"failureExceptions" : [ ],
"jobParameters" : {
"parameters" : { }
},
"jobExecutionId" : 1,
"skipCount" : 0,
"summary" : "StepExecution: id=1, version=0, name=DOCJOB_STEP, status=STARTING, exitStatus=EXECUTING, readCount=0, filterCount=0, writeCount=0 readSkipCount=0, writeSkipCount=0, processSkipCount=0, commitCount=0, rollbackCount=0"
},
"stepType" : "",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1/steps/1"
}
}
}44.14.3。作业步骤执行进度
作业步骤执行端点可让您获取有关作业步骤执行进度的详细信息。以下主题提供了更多详细信息:
请求结构
GET /jobs/executions/1/steps/1/progress HTTP/1.1
Host: localhost:9393/jobs/executions/{id}/steps/{stepid}/progress
| 范围 | 描述 |
|---|---|
|
现有作业执行的 ID(必需) |
|
特定作业执行的现有步骤执行的 ID(必需) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/jobs/executions/1/steps/1/progress' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 2676
{
"stepExecution" : {
"stepName" : "DOCJOB_STEP",
"id" : 1,
"version" : 0,
"status" : "STARTING",
"readCount" : 0,
"writeCount" : 0,
"commitCount" : 0,
"rollbackCount" : 0,
"readSkipCount" : 0,
"processSkipCount" : 0,
"writeSkipCount" : 0,
"startTime" : "2022-04-05T22:10:00.667+0000",
"endTime" : null,
"lastUpdated" : "2022-04-05T22:10:00.667+0000",
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"exitStatus" : {
"exitCode" : "EXECUTING",
"exitDescription" : ""
},
"terminateOnly" : false,
"filterCount" : 0,
"failureExceptions" : [ ],
"jobParameters" : {
"parameters" : { }
},
"jobExecutionId" : 1,
"skipCount" : 0,
"summary" : "StepExecution: id=1, version=0, name=DOCJOB_STEP, status=STARTING, exitStatus=EXECUTING, readCount=0, filterCount=0, writeCount=0 readSkipCount=0, writeSkipCount=0, processSkipCount=0, commitCount=0, rollbackCount=0"
},
"stepExecutionHistory" : {
"stepName" : "DOCJOB_STEP",
"count" : 0,
"commitCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"standardDeviation" : 0.0,
"mean" : 0.0
},
"rollbackCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"standardDeviation" : 0.0,
"mean" : 0.0
},
"readCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"standardDeviation" : 0.0,
"mean" : 0.0
},
"writeCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"standardDeviation" : 0.0,
"mean" : 0.0
},
"filterCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"standardDeviation" : 0.0,
"mean" : 0.0
},
"readSkipCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"standardDeviation" : 0.0,
"mean" : 0.0
},
"writeSkipCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"standardDeviation" : 0.0,
"mean" : 0.0
},
"processSkipCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"standardDeviation" : 0.0,
"mean" : 0.0
},
"duration" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"standardDeviation" : 0.0,
"mean" : 0.0
},
"durationPerRead" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"standardDeviation" : 0.0,
"mean" : 0.0
}
},
"percentageComplete" : 0.5,
"finished" : false,
"duration" : 251.0,
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1/steps/1"
}
}
}44.15。有关应用程序的运行时信息
您可以全局或单独获取有关系统已知的运行应用程序的信息。以下主题提供了更多详细信息:
44.15.1。在运行时列出所有应用程序
要检索有关所有应用程序的所有实例的信息,请/runtime/apps使用 查询端点GET。以下主题提供了更多详细信息:
请求结构
GET /runtime/apps HTTP/1.1
Accept: application/json
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/runtime/apps' -i -X GET \
-H 'Accept: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 209
{
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps?page=0&size=20"
}
},
"page" : {
"size" : 20,
"totalElements" : 0,
"totalPages" : 0,
"number" : 0
}
}44.15.2。查询单个应用的所有实例
要检索有关特定应用程序的所有实例的信息,请/runtime/apps/<appId>/instances使用 查询端点GET。以下主题提供了更多详细信息:
请求结构
GET /runtime/apps HTTP/1.1
Accept: application/json
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/runtime/apps' -i -X GET \
-H 'Accept: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 209
{
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps?page=0&size=20"
}
},
"page" : {
"size" : 20,
"totalElements" : 0,
"totalPages" : 0,
"number" : 0
}
}44.15.3。查询单个应用的单个实例
要检索有关特定应用程序的特定实例的信息,请/runtime/apps/<appId>/instances/<instanceId>使用 查询端点GET。以下主题提供了更多详细信息:
请求结构
GET /runtime/apps HTTP/1.1
Accept: application/json
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/runtime/apps' -i -X GET \
-H 'Accept: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 209
{
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps?page=0&size=20"
}
},
"page" : {
"size" : 20,
"totalElements" : 0,
"totalPages" : 0,
"number" : 0
}
}44.16。流日志
您可以获取整个流或流中特定应用程序的流的应用程序日志。以下主题提供了更多详细信息:
44.16.1。通过流名称获取应用程序的日志
使用带有 REST 端点的 HTTPGET方法/streams/logs/<streamName>来检索给定流名称的所有应用程序日志。以下主题提供了更多详细信息:
请求结构
GET /streams/logs/ticktock HTTP/1.1
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/streams/logs/ticktock' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 93
{
"logs" : {
"ticktock-time-v1" : "Logs-time",
"ticktock-log-v1" : "Logs-log"
}
}44.16.2。从流中获取特定应用程序的日志
要从流中检索特定应用程序的日志,请使用HTTP 方法查询/streams/logs/<streamName>/<appName>端点。GET以下主题提供了更多详细信息:
请求结构
GET /streams/logs/ticktock/ticktock-log-v1 HTTP/1.1
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/streams/logs/ticktock/ticktock-log-v1' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 55
{
"logs" : {
"ticktock-log-v1" : "Logs-log"
}
}44.17。任务日志
您可以获取特定任务执行的任务执行日志。
以下主题提供了更多详细信息:
44.17.1。获取任务执行日志
要检索任务执行的日志,请/tasks/logs/<ExternalTaskExecutionId>使用 HTTPGET方法查询端点。以下主题提供了更多详细信息:
请求结构
GET /tasks/logs/taskA-8301a3af-5ef1-46fc-8756-998ee1a4bc67?platformName=default HTTP/1.1
Host: localhost:9393请求参数
| 范围 | 描述 |
|---|---|
|
启动任务的平台名称。 |
示例请求
$ curl 'http://localhost:9393/tasks/logs/taskA-8301a3af-5ef1-46fc-8756-998ee1a4bc67?platformName=default' -i -X GET响应结构
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 10043
"stdout:\n2022-04-05 22:09:17.251 INFO 3502 --- [ main] s.c.a.AnnotationConfigApplicationContext : Refreshing org.springframework.context.annotation.AnnotationConfigApplicationContext@4e515669: startup date [Tue Apr 05 22:09:17 UTC 2022]; root of context hierarchy\n2022-04-05 22:09:17.598 INFO 3502 --- [ main] trationDelegate$BeanPostProcessorChecker : Bean 'configurationPropertiesRebinderAutoConfiguration' of type [org.springframework.cloud.autoconfigure.ConfigurationPropertiesRebinderAutoConfiguration$$EnhancerBySpringCGLIB$$b056ca48] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying)\n\n . ____ _ __ _ _\n /\\\\ / ___'_ __ _ _(_)_ __ __ _ \\ \\ \\ \\\n( ( )\\___ | '_ | '_| | '_ \\/ _` | \\ \\ \\ \\\n \\\\/ ___)| |_)| | | | | || (_| | ) ) ) )\n ' |____| .__|_| |_|_| |_\\__, | / / / /\n =========|_|==============|___/=/_/_/_/\n :: Spring Boot :: (v1.5.2.RELEASE)\n\n2022-04-05 22:09:17.839 INFO 3502 --- [ main] c.c.c.ConfigServicePropertySourceLocator : Fetching config from server at: http://localhost:8888\n2022-04-05 22:09:17.910 WARN 3502 --- [ main] c.c.c.ConfigServicePropertySourceLocator : Could not locate PropertySource: I/O error on GET request for \"http://localhost:8888/timestamp-task/default\": Connection refused (Connection refused); nested exception is java.net.ConnectException: Connection refused (Connection refused)\n2022-04-05 22:09:17.911 INFO 3502 --- [ main] o.s.c.t.a.t.TimestampTaskApplication : No active profile set, falling back to default profiles: default\n2022-04-05 22:09:17.924 INFO 3502 --- [ main] s.c.a.AnnotationConfigApplicationContext : Refreshing org.springframework.context.annotation.AnnotationConfigApplicationContext@445b84c0: startup date [Tue Apr 05 22:09:17 UTC 2022]; parent: org.springframework.context.annotation.AnnotationConfigApplicationContext@4e515669\n2022-04-05 22:09:18.405 INFO 3502 --- [ main] o.s.cloud.context.scope.GenericScope : BeanFactory id=1e36064f-ccbe-3d2f-9196-128427cc78a0\n2022-04-05 22:09:18.461 INFO 3502 --- [ main] trationDelegate$BeanPostProcessorChecker : Bean 'org.springframework.cloud.autoconfigure.ConfigurationPropertiesRebinderAutoConfiguration' of type [org.springframework.cloud.autoconfigure.ConfigurationPropertiesRebinderAutoConfiguration$$EnhancerBySpringCGLIB$$b056ca48] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying)\n2022-04-05 22:09:18.467 INFO 3502 --- [ main] trationDelegate$BeanPostProcessorChecker : Bean 'org.springframework.transaction.annotation.ProxyTransactionManagementConfiguration' of type [org.springframework.transaction.annotation.ProxyTransactionManagementConfiguration$$EnhancerBySpringCGLIB$$943cc74b] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying)\n2022-04-05 22:09:18.982 INFO 3502 --- [ main] o.s.jdbc.datasource.init.ScriptUtils : Executing SQL script from class path resource [org/springframework/cloud/task/schema-h2.sql]\n2022-04-05 22:09:19.012 INFO 3502 --- [ main] o.s.jdbc.datasource.init.ScriptUtils : Executed SQL script from class path resource [org/springframework/cloud/task/schema-h2.sql] in 30 ms.\n2022-04-05 22:09:19.307 INFO 3502 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Registering beans for JMX exposure on startup\n2022-04-05 22:09:19.313 INFO 3502 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Bean with name 'configurationPropertiesRebinder' has been autodetected for JMX exposure\n2022-04-05 22:09:19.313 INFO 3502 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Bean with name 'environmentManager' has been autodetected for JMX exposure\n2022-04-05 22:09:19.314 INFO 3502 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Bean with name 'refreshScope' has been autodetected for JMX exposure\n2022-04-05 22:09:19.316 INFO 3502 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Located managed bean 'environmentManager': registering with JMX server as MBean [taskA-8301a3af-5ef1-46fc-8756-998ee1a4bc67:name=environmentManager,type=EnvironmentManager]\n2022-04-05 22:09:19.326 INFO 3502 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Located managed bean 'refreshScope': registering with JMX server as MBean [taskA-8301a3af-5ef1-46fc-8756-998ee1a4bc67:name=refreshScope,type=RefreshScope]\n2022-04-05 22:09:19.333 INFO 3502 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Located managed bean 'configurationPropertiesRebinder': registering with JMX server as MBean [taskA-8301a3af-5ef1-46fc-8756-998ee1a4bc67:name=configurationPropertiesRebinder,context=445b84c0,type=ConfigurationPropertiesRebinder]\n2022-04-05 22:09:19.391 INFO 3502 --- [ main] o.s.c.support.DefaultLifecycleProcessor : Starting beans in phase 0\n2022-04-05 22:09:19.404 WARN 3502 --- [ main] s.c.a.AnnotationConfigApplicationContext : Exception encountered during context initialization - cancelling refresh attempt: org.springframework.context.ApplicationContextException: Failed to start bean 'taskLifecycleListener'; nested exception is java.lang.IllegalArgumentException: Invalid TaskExecution, ID 1 not found\n2022-04-05 22:09:19.405 INFO 3502 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Unregistering JMX-exposed beans on shutdown\n2022-04-05 22:09:19.405 INFO 3502 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Unregistering JMX-exposed beans\n2022-04-05 22:09:19.405 ERROR 3502 --- [ main] o.s.c.t.listener.TaskLifecycleListener : An event to end a task has been received for a task that has not yet started.\n2022-04-05 22:09:19.410 INFO 3502 --- [ main] utoConfigurationReportLoggingInitializer : \n\nError starting ApplicationContext. To display the auto-configuration report re-run your application with 'debug' enabled.\n2022-04-05 22:09:19.416 ERROR 3502 --- [ main] o.s.boot.SpringApplication : Application startup failed\n\norg.springframework.context.ApplicationContextException: Failed to start bean 'taskLifecycleListener'; nested exception is java.lang.IllegalArgumentException: Invalid TaskExecution, ID 1 not found\n\tat org.springframework.context.support.DefaultLifecycleProcessor.doStart(DefaultLifecycleProcessor.java:178) ~[spring-context-4.3.7.RELEASE.jar!/:4.3.7.RELEASE]\n\tat org.springframework.context.support.DefaultLifecycleProcessor.access$200(DefaultLifecycleProcessor.java:50) ~[spring-context-4.3.7.RELEASE.jar!/:4.3.7.RELEASE]\n\tat org.springframework.context.support.DefaultLifecycleProcessor$LifecycleGroup.start(DefaultLifecycleProcessor.java:348) ~[spring-context-4.3.7.RELEASE.jar!/:4.3.7.RELEASE]\n\tat org.springframework.context.support.DefaultLifecycleProcessor.startBeans(DefaultLifecycleProcessor.java:151) ~[spring-context-4.3.7.RELEASE.jar!/:4.3.7.RELEASE]\n\tat org.springframework.context.support.DefaultLifecycleProcessor.onRefresh(DefaultLifecycleProcessor.java:114) ~[spring-context-4.3.7.RELEASE.jar!/:4.3.7.RELEASE]\n\tat org.springframework.context.support.AbstractApplicationContext.finishRefresh(AbstractApplicationContext.java:879) ~[spring-context-4.3.7.RELEASE.jar!/:4.3.7.RELEASE]\n\tat org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:545) ~[spring-context-4.3.7.RELEASE.jar!/:4.3.7.RELEASE]\n\tat org.springframework.boot.SpringApplication.refresh(SpringApplication.java:737) [spring-boot-1.5.2.RELEASE.jar!/:1.5.2.RELEASE]\n\tat org.springframework.boot.SpringApplication.refreshContext(SpringApplication.java:370) [spring-boot-1.5.2.RELEASE.jar!/:1.5.2.RELEASE]\n\tat org.springframework.boot.SpringApplication.run(SpringApplication.java:314) [spring-boot-1.5.2.RELEASE.jar!/:1.5.2.RELEASE]\n\tat org.springframework.boot.SpringApplication.run(SpringApplication.java:1162) [spring-boot-1.5.2.RELEASE.jar!/:1.5.2.RELEASE]\n\tat org.springframework.boot.SpringApplication.run(SpringApplication.java:1151) [spring-boot-1.5.2.RELEASE.jar!/:1.5.2.RELEASE]\n\tat org.springframework.cloud.task.app.timestamp.TimestampTaskApplication.main(TimestampTaskApplication.java:29) [classes!/:1.2.0.RELEASE]\n\tat sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:1.8.0_322]\n\tat sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[na:1.8.0_322]\n\tat sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_322]\n\tat java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_322]\n\tat org.springframework.boot.loader.MainMethodRunner.run(MainMethodRunner.java:48) [timestamp-task-1.2.0.RELEASE.jar:1.2.0.RELEASE]\n\tat org.springframework.boot.loader.Launcher.launch(Launcher.java:87) [timestamp-task-1.2.0.RELEASE.jar:1.2.0.RELEASE]\n\tat org.springframework.boot.loader.Launcher.launch(Launcher.java:50) [timestamp-task-1.2.0.RELEASE.jar:1.2.0.RELEASE]\n\tat org.springframework.boot.loader.JarLauncher.main(JarLauncher.java:51) [timestamp-task-1.2.0.RELEASE.jar:1.2.0.RELEASE]\nCaused by: java.lang.IllegalArgumentException: Invalid TaskExecution, ID 1 not found\n\tat org.springframework.util.Assert.notNull(Assert.java:134) ~[spring-core-4.3.7.RELEASE.jar!/:4.3.7.RELEASE]\n\tat org.springframework.cloud.task.listener.TaskLifecycleListener.doTaskStart(TaskLifecycleListener.java:200) ~[spring-cloud-task-core-1.2.0.RELEASE.jar!/:1.2.0.RELEASE]\n\tat org.springframework.cloud.task.listener.TaskLifecycleListener.start(TaskLifecycleListener.java:282) ~[spring-cloud-task-core-1.2.0.RELEASE.jar!/:1.2.0.RELEASE]\n\tat org.springframework.context.support.DefaultLifecycleProcessor.doStart(DefaultLifecycleProcessor.java:175) ~[spring-context-4.3.7.RELEASE.jar!/:4.3.7.RELEASE]\n\t... 20 common frames omitted\n\n"附录
遇到 Spring Cloud Data Flow 问题,我们愿意提供帮助!
-
问一个问题。我们监控stackoverflow.com中带有 标记的问题
spring-cloud-dataflow。 -
在github.com/spring-cloud/spring-cloud-dataflow/issues报告 Spring Cloud Data Flow 的错误。
附录 A:数据流模板
如 API 指南章节所述,Spring Cloud Data Flow 的功能完全通过 REST 端点公开。虽然您可以直接使用这些端点,但 Spring Cloud Data Flow 还提供了基于 Java 的 API,这使得使用这些 REST 端点更加容易。
中心入口点是包中的DataFlowTemplate类org.springframework.cloud.dataflow.rest.client。
此类实现DataFlowOperations接口并委托给以下子模板,这些子模板为每个功能集提供特定功能:
| 界面 | 描述 |
|---|---|
|
用于流操作的 REST 客户端 |
|
用于计数器操作的 REST 客户端 |
|
用于字段值计数器操作的 REST 客户端 |
|
用于聚合计数器操作的 REST 客户端 |
|
用于任务操作的 REST 客户端 |
|
用于作业操作的 REST 客户端 |
|
用于应用注册表操作的 REST 客户端 |
|
用于完成操作的 REST 客户端 |
|
用于运行时操作的 REST 客户端 |
在DataFlowTemplate初始化时,可以通过 HATEOAS(Hypermedia as the Engine of Application State)提供的 REST 关系发现子模板。
| 如果无法解析资源,则相应的子模板将导致 NULL。一个常见的原因是 Spring Cloud Data Flow 允许在启动时启用或禁用特定的功能集。有关更多信息,请参阅本地、Cloud Foundry或Kubernetes配置章节之一,具体取决于您部署应用程序的位置。 |
A.1。使用数据流模板
当您使用 Data Flow Template 时,唯一需要的 Data Flow 依赖项是 Spring Cloud Data Flow Rest Client,如以下 Maven 片段所示:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dataflow-rest-client</artifactId>
<version>2.9.4</version>
</dependency>使用该依赖项,您可以获得DataFlowTemplate类以及调用 Spring Cloud Data Flow 服务器所需的所有依赖项。
实例化 时DataFlowTemplate,您还传入了RestTemplate. 请注意,RestTemplate需要一些额外的配置才能在DataFlowTemplate. 将 a 声明RestTemplate为 bean 时,以下配置就足够了:
@Bean
public static RestTemplate restTemplate() {
RestTemplate restTemplate = new RestTemplate();
restTemplate.setErrorHandler(new VndErrorResponseErrorHandler(restTemplate.getMessageConverters()));
for(HttpMessageConverter<?> converter : restTemplate.getMessageConverters()) {
if (converter instanceof MappingJackson2HttpMessageConverter) {
final MappingJackson2HttpMessageConverter jacksonConverter =
(MappingJackson2HttpMessageConverter) converter;
jacksonConverter.getObjectMapper()
.registerModule(new Jackson2HalModule())
.addMixIn(JobExecution.class, JobExecutionJacksonMixIn.class)
.addMixIn(JobParameters.class, JobParametersJacksonMixIn.class)
.addMixIn(JobParameter.class, JobParameterJacksonMixIn.class)
.addMixIn(JobInstance.class, JobInstanceJacksonMixIn.class)
.addMixIn(ExitStatus.class, ExitStatusJacksonMixIn.class)
.addMixIn(StepExecution.class, StepExecutionJacksonMixIn.class)
.addMixIn(ExecutionContext.class, ExecutionContextJacksonMixIn.class)
.addMixIn(StepExecutionHistory.class, StepExecutionHistoryJacksonMixIn.class);
}
}
return restTemplate;
}
您还可以RestTemplate使用
DataFlowTemplate.getDefaultDataflowRestTemplate();
|
DataFlowTemplate现在您可以使用以下代码实例化:
DataFlowTemplate dataFlowTemplate = new DataFlowTemplate(
new URI("http://localhost:9393/"), restTemplate); (1)| 1 | URI指向 Spring Cloud Data Flow Server 的 ROOT 。 |
根据您的要求,您现在可以调用服务器。例如,如果要获取当前可用应用程序的列表,可以运行以下代码:
PagedResources<AppRegistrationResource> apps = dataFlowTemplate.appRegistryOperations().list();
System.out.println(String.format("Retrieved %s application(s)",
apps.getContent().size()));
for (AppRegistrationResource app : apps.getContent()) {
System.out.println(String.format("App Name: %s, App Type: %s, App URI: %s",
app.getName(),
app.getType(),
app.getUri()));
}A2。数据流模板和安全
使用 时DataFlowTemplate,您还可以像使用Data Flow Shell一样提供所有与安全相关的选项。事实上,Data Flow Shell
使用它DataFlowTemplate的所有操作。
为了让您开始,我们提供了一个HttpClientConfigurer使用构建器模式来设置各种与安全相关的选项:
HttpClientConfigurer
.create(targetUri) (1)
.basicAuthCredentials(username, password) (2)
.skipTlsCertificateVerification() (3)
.withProxyCredentials(proxyUri, proxyUsername, proxyPassword) (4)
.addInterceptor(interceptor) (5)
.buildClientHttpRequestFactory() (6)| 1 | 使用提供的目标 URI 创建一个 HttpClientConfigurer。 |
| 2 | 设置基本身份验证的凭据(使用 OAuth2 密码授予) |
| 3 | 跳过 SSL 证书验证(仅用于开发!) |
| 4 | 配置任何代理设置 |
| 5 | 添加自定义拦截器,例如设置 OAuth2 授权标头。这允许您传递 OAuth2 访问令牌而不是用户名/密码凭据。 |
| 6 | 构建ClientHttpRequestFactory可以在RestTemplate. |
HttpClientConfigurer配置好之后,就可以使用它来buildClientHttpRequestFactory
构建ClientHttpRequestFactory,然后在RestTemplate. 然后,您可以实例化实际DataFlowTemplate
使用 that RestTemplate。
要配置Basic Authentication,需要进行以下设置:
RestTemplate restTemplate = DataFlowTemplate.getDefaultDataflowRestTemplate();
HttpClientConfigurer httpClientConfigurer = HttpClientConfigurer.create("http://localhost:9393");
httpClientConfigurer.basicAuthCredentials("my_username", "my_password");
restTemplate.setRequestFactory(httpClientConfigurer.buildClientHttpRequestFactory());
DataFlowTemplate dataFlowTemplate = new DataFlowTemplate("http://localhost:9393", restTemplate);您可以 在 GitHub 上的spring-cloud-dataflow-samples存储库中找到示例应用程序。
附录 B:“操作方法”指南
本节提供了人们在使用 Spring Cloud Data Flow 时经常出现的一些常见问题的答案。
如果您有我们未在此处介绍的特定问题,您可能需要查看stackoverflow.com以查看是否有人已经提供了答案。这也是提出新问题的好地方(使用spring-cloud-dataflow标签)。
我们也非常乐意扩展本节。如果您想添加“操作方法”,可以向我们发送拉取请求。
B.1。配置 Maven 属性
您可以在启动数据流服务器时通过命令行属性设置 Maven 属性,例如本地 Maven 存储库位置、远程 Maven 存储库、身份验证凭据和代理服务器属性。或者,您可以通过设置SPRING_APPLICATION_JSON数据流服务器的环境属性来设置属性。
如果使用 Maven 存储库解析应用程序,则需要显式配置远程 Maven 存储库,local数据流服务器除外。其他数据流服务器实现(使用 Maven 资源进行应用程序工件解析)对远程存储库没有默认值。local服务器具有repo.spring.io/libs-snapshot默认的远程存储库。
要将属性作为命令行选项传递,请使用类似于以下的命令运行服务器:
$ java -jar <dataflow-server>.jar --maven.localRepository=mylocal
--maven.remote-repositories.repo1.url=https://repo1
--maven.remote-repositories.repo1.auth.username=repo1user
--maven.remote-repositories.repo1.auth.password=repo1pass
--maven.remote-repositories.repo2.url=https://repo2 --maven.proxy.host=proxyhost
--maven.proxy.port=9018 --maven.proxy.auth.username=proxyuser
--maven.proxy.auth.password=proxypass您还可以使用SPRING_APPLICATION_JSON环境属性:
export SPRING_APPLICATION_JSON='{ "maven": { "local-repository": "local","remote-repositories": { "repo1": { "url": "https://repo1", "auth": { "username": "repo1user", "password": "repo1pass" } },
"repo2": { "url": "https://repo2" } }, "proxy": { "host": "proxyhost", "port": 9018, "auth": { "username": "proxyuser", "password": "proxypass" } } } }'这是格式良好的 JSON 中的相同内容:
SPRING_APPLICATION_JSON='{
"maven": {
"local-repository": "local",
"remote-repositories": {
"repo1": {
"url": "https://repo1",
"auth": {
"username": "repo1user",
"password": "repo1pass"
}
},
"repo2": {
"url": "https://repo2"
}
},
"proxy": {
"host": "proxyhost",
"port": 9018,
"auth": {
"username": "proxyuser",
"password": "proxypass"
}
}
}
}'
根据 Spring Cloud Data Flow 服务器实现,您可能必须使用平台特定的环境设置功能来传递环境属性。例如,在 Cloud Foundry 中,您可以将它们传递为cf set-env SPRING_APPLICATION_JSON.
|
B.3。经常问的问题
在本节中,我们回顾了 Spring Cloud Data Flow 的常见问题。有关详细信息,请参阅微型网站的常见问题部分。
附录 C:建筑
本附录描述了如何构建 Spring Cloud Data Flow。
要构建源代码,您需要安装 JDK 1.8。
该构建使用 Maven 包装器,因此您不必安装特定版本的 Maven。
主要构建命令如下:
$ ./mvnw clean install为了加快构建速度,您可以添加-DskipTests以避免运行测试。
您也可以自己安装 Maven (>=3.3.3) 并运行mvn命令来代替./mvnw下面的示例。-P spring如果你这样做,如果你的本地 Maven 设置不包含 Spring 预发布工件的存储库声明
,你可能还需要添加。 |
您可能需要通过设置一个MAVEN_OPTS类似于-Xmx512m -XX:MaxPermSize=128m. 我们尝试在.mvn配置中涵盖这一点,因此,如果您发现必须这样做才能使构建成功,请提出票证以将设置添加到源代码管理中。
|
C.1。文档
有一个full生成文档的配置文件。您可以使用以下命令仅构建文档:
$ ./mvnw clean package -DskipTests -P full -pl {project-artifactId} -amC.2。使用代码
如果您没有喜欢的 IDE,我们建议您在处理代码时使用Spring Tools Suite或Eclipse 。我们使用m2eclipse Eclipse 插件来支持 Maven。其他 IDE 和工具通常也可以正常工作。
C.2.1。使用 m2eclipse 导入 Eclipse
在使用 Eclipse 时,我们推荐使用m2eclip eclipse 插件。如果您还没有安装 m2eclipse,它可以从 Eclipse 市场获得。
不幸的是,m2e 还不支持 Maven 3.3。因此,一旦项目被导入 Eclipse,您还需要告诉 m2eclipse 使用.settings.xml项目的文件。如果您不这样做,您可能会看到与项目中的 POM 相关的许多不同错误。为此:
-
打开您的 Eclipse 首选项。
-
展开Maven 首选项。
-
选择用户设置。
-
在User Settings字段中,单击Browse并导航到您导入的 Spring Cloud 项目。
-
选择该
.settings.xml项目中的文件。 -
单击应用。
-
单击确定。
或者,您可以将存储库设置从 Spring Cloud 的.settings.xml文件复制到您自己的~/.m2/settings.xml.
|
C.2.2。在没有 m2eclipse 的情况下导入 Eclipse
如果您不想使用 m2eclipse,可以使用以下命令生成 Eclipse 项目元数据:
$ ./mvnw eclipse:eclipse您可以通过从File菜单中选择Import existing projects来导入生成的 Eclipse 项目。
附录 D:贡献
Spring Cloud 在非限制性 Apache 2.0 许可下发布,并遵循非常标准的 Github 开发流程,使用 Github 跟踪器处理问题并将拉取请求合并到主分支。如果您想贡献一些微不足道的东西,请不要犹豫,但请遵循本附录中的指南。
D.1。签署贡献者许可协议
在我们接受重要的(除了纠正印刷错误之外)补丁或拉取请求之前,我们需要您签署贡献者协议。签署贡献者协议并不授予任何人对主存储库的提交权限,但这确实意味着我们可以接受您的贡献,如果我们这样做,您将获得作者信用。积极的贡献者可能会被要求加入核心团队并被赋予合并拉取请求的能力。
D.2。代码约定和内务管理
以下指南对于拉取请求都不是必不可少的,但它们都可以帮助您的开发人员同事理解和使用您的代码。它们也可以在原始拉取请求之后但在合并之前添加。
-
使用 Spring Framework 代码格式约定。如果您使用 Eclipse,则可以使用Spring Cloud Build项目中的
eclipse-code-formatter.xml文件导入格式化程序设置。如果您使用 IntelliJ,则可以使用Eclipse Code Formatter Plugin导入相同的文件。 -
确保所有新
.java文件都有一个简单的 Javadoc 类注释,其中至少有一个@author标识您的标签,最好至少有一个描述类目的的段落。 -
将 ASF 许可证标题注释添加到所有新
.java文件(为此,请从项目中的现有文件中复制它)。 -
将您自己添加
@author到您大量修改的 .java 文件中(不仅仅是外观更改)。 -
添加一些 Javadocs,如果更改名称空间,则添加一些 XSD 文档元素。
-
一些单元测试也会有很大帮助。必须有人来做,你的开发人员同事很感激你的努力。
-
如果没有其他人使用您的分支,请根据当前主分支(或主项目中的其他目标分支)对其进行变基。
-
编写提交消息时,请遵循这些约定。如果您修复现有问题,请
Fixes gh-XXXX在提交消息的末尾添加(其中 XXXX 是问题编号)。== 身份提供者
本附录包含如何设置特定提供程序以使用数据流安全性的信息。
在撰写本文时,Azure 是唯一的身份提供者。
D.3。天蓝色
Azure AD (Active Directory) 是一个成熟的身份提供程序,提供有关身份验证和授权的广泛功能。与任何其他提供商一样,它有自己的细微差别,这意味着必须小心设置它。
在本节中,我们将介绍如何为 AD 和 Spring Cloud Data Flow 完成 OAuth2 设置。
| 您需要完整的组织访问权限才能正确设置所有内容。 |
D.3.1。创建新的 AD 环境
首先,创建一个新的 Active Directory 环境。选择一种类型作为 Azure Active Directory(不是 b2c 类型),然后选择您的组织名称和初始域。下图显示了设置:

D.3.2。创建新应用注册
应用程序注册是创建 OAuth 客户端以供 OAuth 应用程序使用的地方。至少,您需要创建两个客户端,一个用于 Data Flow 和 Skipper 服务器,一个用于 Data Flow shell,因为这两个客户端的配置略有不同。服务器应用程序可以被认为是受信任的应用程序,而 shell 不受信任(因为用户可以看到它的完整配置)。
注意:我们建议对 Data Flow 和 Skipper 服务器使用相同的 OAuth 客户端。虽然您可以使用不同的客户端,但它目前不会提供任何价值,因为配置需要相同。
下图显示了创建新应用注册的设置:

需要时,Certificates & secrets在 AD 中创建客户端密码。
|
D.3.3。公开数据流 API
要准备 OAuth 范围,请为每个数据流安全角色创建一个。在这个例子中,那些将是
-
api://dataflow-server/dataflow.create -
api://dataflow-server/dataflow.deploy -
api://dataflow-server/dataflow.destroy -
api://dataflow-server/dataflow.manage -
api://dataflow-server/dataflow.schedule -
api://dataflow-server/dataflow.modify -
api://dataflow-server/dataflow.view
下图显示了要公开的 API:

之前创建的范围需要添加为 API 权限,如下图所示:

D.3.4。创建特权客户端
对于即将使用密码授权的 OAuth 客户端,需要为 OAuth 客户端创建与用于服务器的 API 权限相同的 API 权限(如上一节所述)。
| 所有这些权限都需要授予管理员权限。 |
下图显示了特权设置:

| 特权客户端需要一个客户端密码,在 shell 中使用时需要将其暴露给客户端配置。如果您不想公开该机密,请使用 创建公共客户端公共客户端。 |
D.3.5。创建公共客户端
公共客户端基本上是没有客户端密码且类型设置为公共的客户端。
下图显示了公共客户端的配置:

D.3.6。配置示例
本节包含 Data Flow 和 Skipper 服务器以及 shell 的配置示例。
要启动数据流服务器:
$ java -jar spring-cloud-dataflow-server.jar \
--spring.config.additional-location=dataflow-azure.ymlspring:
cloud:
dataflow:
security:
authorization:
provider-role-mappings:
dataflow-server:
map-oauth-scopes: true
role-mappings:
ROLE_VIEW: dataflow.view
ROLE_CREATE: dataflow.create
ROLE_MANAGE: dataflow.manage
ROLE_DEPLOY: dataflow.deploy
ROLE_DESTROY: dataflow.destroy
ROLE_MODIFY: dataflow.modify
ROLE_SCHEDULE: dataflow.schedule
security:
oauth2:
client:
registration:
dataflow-server:
provider: azure
redirect-uri: '{baseUrl}/login/oauth2/code/{registrationId}'
client-id: <client id>
client-secret: <client secret>
scope:
- openid
- profile
- email
- offline_access
- api://dataflow-server/dataflow.view
- api://dataflow-server/dataflow.deploy
- api://dataflow-server/dataflow.destroy
- api://dataflow-server/dataflow.manage
- api://dataflow-server/dataflow.modify
- api://dataflow-server/dataflow.schedule
- api://dataflow-server/dataflow.create
provider:
azure:
issuer-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/v2.0
user-name-attribute: name
resourceserver:
jwt:
jwk-set-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/discovery/v2.0/keys要启动 Skipper 服务器:
$ java -jar spring-cloud-skipper-server.jar \
--spring.config.additional-location=skipper-azure.ymlspring:
cloud:
skipper:
security:
authorization:
provider-role-mappings:
skipper-server:
map-oauth-scopes: true
role-mappings:
ROLE_VIEW: dataflow.view
ROLE_CREATE: dataflow.create
ROLE_MANAGE: dataflow.manage
ROLE_DEPLOY: dataflow.deploy
ROLE_DESTROY: dataflow.destroy
ROLE_MODIFY: dataflow.modify
ROLE_SCHEDULE: dataflow.schedule
security:
oauth2:
client:
registration:
skipper-server:
provider: azure
redirect-uri: '{baseUrl}/login/oauth2/code/{registrationId}'
client-id: <client id>
client-secret: <client secret>
scope:
- openid
- profile
- email
- offline_access
- api://dataflow-server/dataflow.view
- api://dataflow-server/dataflow.deploy
- api://dataflow-server/dataflow.destroy
- api://dataflow-server/dataflow.manage
- api://dataflow-server/dataflow.modify
- api://dataflow-server/dataflow.schedule
- api://dataflow-server/dataflow.create
provider:
azure:
issuer-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/v2.0
user-name-attribute: name
resourceserver:
jwt:
jwk-set-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/discovery/v2.0/keys要启动 shell 并(可选)将凭据作为选项传递:
$ java -jar spring-cloud-dataflow-shell.jar \
--spring.config.additional-location=dataflow-azure-shell.yml \
--dataflow.username=<USERNAME> \
--dataflow.password=<PASSWORD> security:
oauth2:
client:
registration:
dataflow-shell:
provider: azure
client-id: <client id>
client-secret: <client secret>
authorization-grant-type: password
scope:
- offline_access
- api://dataflow-server/dataflow.create
- api://dataflow-server/dataflow.deploy
- api://dataflow-server/dataflow.destroy
- api://dataflow-server/dataflow.manage
- api://dataflow-server/dataflow.modify
- api://dataflow-server/dataflow.schedule
- api://dataflow-server/dataflow.view
provider:
azure:
issuer-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/v2.0启动公共 shell 并(可选)将凭据作为选项传递:
$ java -jar spring-cloud-dataflow-shell.jar \
--spring.config.additional-location=dataflow-azure-shell-public.yml \
--dataflow.username=<USERNAME> \
--dataflow.password=<PASSWORD>spring:
security:
oauth2:
client:
registration:
dataflow-shell:
provider: azure
client-id: <client id>
authorization-grant-type: password
client-authentication-method: post
scope:
- offline_access
- api://dataflow-server/dataflow.create
- api://dataflow-server/dataflow.deploy
- api://dataflow-server/dataflow.destroy
- api://dataflow-server/dataflow.manage
- api://dataflow-server/dataflow.modify
- api://dataflow-server/dataflow.schedule
- api://dataflow-server/dataflow.view
provider:
azure:
issuer-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/v2.0